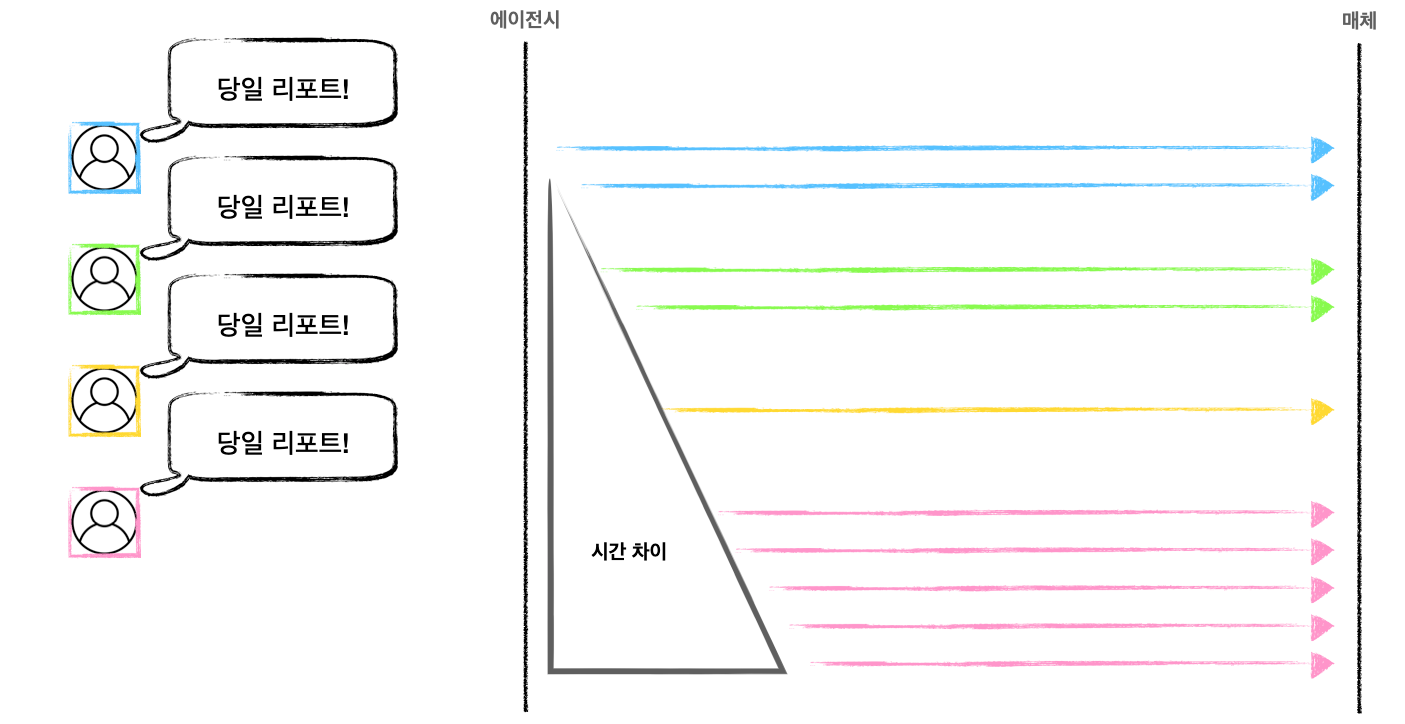
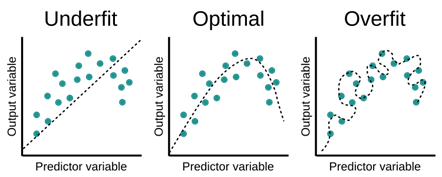인스타그램을 보다보면 나오는 화려한 광고들은 누가 만들까요?
대 AI 시대에도 광고 소재는 여전히 많은 전문가들의 손을 거쳐 제작되고, 또 수명이 다하면 사라집니다.
그렇기 때문에 마케팅 에이전시에서도, 인하우스 마케팅 부서에서도, 주기적으로 레퍼런스를 찾기 위해 반복적으로 아까운 시간을 보내게 됩니다.
LEVER Xpert AI팀은 간단한 질의로 마케터의 상황에 필요한 광고 소재 이미지를 찾을 수 있는 소재 검색을 구현함으로써 레퍼런스 수급이라는 과업을 빠르게 해줄 수 있는 도구를 마련하고자 했습니다.
이 글은 검색의 틀을 처음 구성하며 시도했던 방향과 실험 결과를 기록하고자 합니다.
2. 시스템 개요
광고 소재 이미지를 자연어로 검색하는 시스템입니다.
크게 두 개의 파이프라인으로 구성됩니다.
Offline Pipeline은 검색 대상 데이터를 미리 준비하고, Online Pipeline은 사용자 질의를 실시간으로 처리합니다.
이어지는 절에서 각 파이프라인과 기술 스택을 자세히 다룹니다.
2.1. Offline Pipeline — 데이터 준비
Offline Pipeline은 사용자 검색에 앞서 실행하는 단계입니다.
광고 소재 이미지를 검색 가능한 형태로 미리 변환해 두는 게 목적입니다.
다음과 같이 구성됩니다.
Description 추출: LLM이 광고 소재 이미지를 보고 구조화된 설명 텍스트를 생성합니다.
이중 인덱싱: Description을 의미 검색용 (Dense)과 키워드 검색용 (Sparse) 두 형태로 변환해 같은 Vector DB에 저장합니다.
2.2. Online Pipeline — 검색 API
Online Pipeline은 사용자 질의가 들어왔을 때 실시간으로 동작합니다.
앞서 준비된 인덱스 위에서 질의를 처리해 결과를 반환합니다.
다음과 같이 구성됩니다.
질의 이해: LLM이 자연어 질의를 검색에 적합한 형태로 변환합니다 (e.g., 검색어 추출, 변형 쿼리 생성).
Hybrid Search: 의미 검색 (Dense)과 키워드 검색 (Sparse)을 동시에 실행해 결과를 결합합니다.
Reranking: LLM이 검색 결과의 순위를 재평가해 최종 순위를 결정합니다.
2.3. 기술 스택과 다음 섹션 미리보기
기술 스택
Vector DB: Milvus
Dense Embedding: Gemini Embedding
Sparse Search: BM25
LLM: Gemini (질의 이해, Reranking)
다음 섹션 미리보기
이 시스템을 만들면서 마주친 핵심 결정과 발견을 세 가지 Deep Dive로 풀어냅니다.
3장: CLIP 같은 멀티모달 임베딩 대신 Description 기반을 선택한 이유와 trade-off를 다룹니다.
4장: 확장 쿼리에 동등 가중치를 주면 원본 의도가 묻히는 문제를 강화학습의 Exploitation vs Exploration 개념으로 풀어냅니다.
5장: 직관적으로 옳아 보였던 가설들이 실측에서 반대 방향으로 작동한 사례들을 정리합니다.
3. Deep Dive 1 — 이미지를 ‘검색 가능한 텍스트’로 만들기
3.1. 이미지를 어떻게 검색 가능하게 할 것인가
일반적인 RAG 시스템은 텍스트 문서를 검색 대상으로 삼습니다.
문서를 청크 단위로 잘라 임베딩하고, 자연어 질의를 같은 공간에 매핑해 유사도로 매칭하는 구조가 보편적입니다.
저희가 풀려는 문제는 이와 다르게 검색 대상이 텍스트가 아닌 이미지 (광고 소재)입니다.
마케터는 “따뜻한 색감의 모델컷”처럼 자연어로 질의하는데 그 질의가 향하는 대상은 이미지입니다.
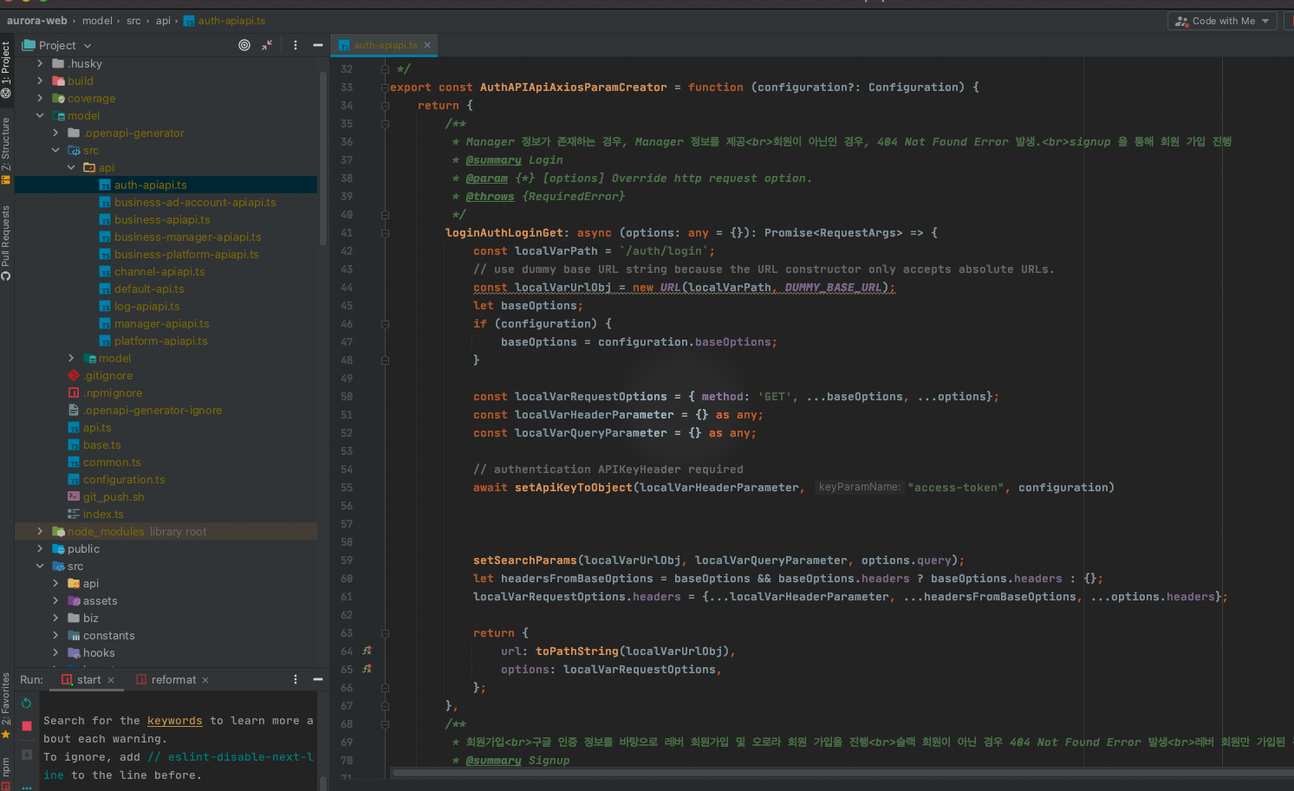
이질적인 두 modality를 어떻게 같은 검색 공간으로 끌어들일지가 시스템 설계의 첫 번째 과제였습니다.
3.2. 두 가지 선택지
이 과제에 접근할 수 있는 길은 크게 두 가지입니다.
접근 A — 이미지 직접 임베딩
CLIP같은 멀티모달 임베딩 모델로 이미지를 벡터화하고, 질의 텍스트도 같은 공간에 임베딩하여 유사도로 매칭하는 방식입니다.
이미지와 텍스트가 사전 학습된 공통 임베딩 공간 위에 놓이므로, 중간 변환 없이 두 modality를 곧바로 비교할 수 있다는 점이 가장 큰 장점입니다.
접근 B — 이미지 → 설명 텍스트 → 임베딩 (Description 기반)
LLM이 이미지를 보고 구조화된 설명 텍스트를 생성한 뒤, 그 텍스트를 임베딩하여 텍스트–텍스트 검색으로 풀어내는 방식입니다.
이미지를 일단 텍스트 공간으로 옮긴 후 그 위에서 기존 RAG의 검색 패턴을 그대로 활용하는 구조입니다.
두 modality를 같은 텍스트 공간으로 통일할 수 있다는 점이 가장 큰 장점입니다.
저희는 접근 B (Description 기반)를 선택했습니다.
이유는 네 가지였습니다.
3.3. Description 기반을 선택한 이유
첫째, 표현력
Description은 이미지의 다면적 특성을 구조화해서 담아냅니다.
광고 소재는 한 가지로 요약되지 않습니다.
소재 형식, 소구하는 바, 등장하는 객체 등 여러 측면이 한 이미지 안에 공존합니다.
CLIP같은 멀티모달 임베딩은 이 모든 측면을 하나의 벡터로 압축합니다.
반면 Description은 각 측면을 구분된 텍스트 단위로 풀어낼 수 있습니다.
저희 PoC에서도 한 이미지를 여러 카테고리로 나누어 추출했습니다.
마케터가 카피 문구를 기준으로 검색할 수도 있고 원하는 소재 이미지를 묘사하는 방식으로 검색할 수도 있습니다.
어느 요소가 검색의 기준이 되든 대응할 수 있으려면 이미지를 측면별로 분리해서 표현할 수 있어야 합니다.
이 분리 가능성이 Description 기반의 첫 번째 강점입니다.
둘째, 검색 구조의 유연성
의미 기반과 키워드 기반 검색 양쪽을 모두 활용할 수 있습니다.
자연어의 의미를 포착해야 하는 질의 (Dense)와 고유명사처럼 정확한 키워드 매칭이 필요한 질의 (Sparse)는 서로 다른 검색 방식을 요구합니다.
고유명사는 의미 임베딩만으로는 안정적으로 매칭되지 않습니다.
Description 기반은 두 검색을 결합한 Hybrid Search로 자연스럽게 확장됩니다.
셋째, 질의와 같은 텍스트 공간
의미 비교가 직관적입니다.
마케터의 자연어 질의와 Description은 둘 다 한국어 텍스트입니다.
“여름철 바캉스를 연상시키는 실사 배경의 연출제품컷”이라는 질의가 들어왔을 때 “해변 리조트 분위기의 청량한 배경”이라는 Description과 의미가 가까운지 판단하는 것은 텍스트 공간 위에서 직접 일어납니다.
CLIP 기반 방식은 사전 학습된 공간을 사용하여 마케팅 도메인 특유의 어휘 (e.g., “소구점”, “비포애프터형 광고”)가 어떻게 매핑되는지 통제하기 어렵습니다.
반면 Description 기반 방식은 추출 프롬프트를 통해 도메인 어휘를 직접 주입할 수 있습니다.
검색이 동작하는 의미 공간을 검색 대상 도메인 (마케팅)에 맞춰 조정할 수 있다는 뜻입니다.
넷째, 해석 가능성과 반복 개선의 용이성
어떤 소재가 왜 매칭되었는지 사람이 읽고 판단할 수 있습니다.
그 소재의 Description을 직접 살펴보면 결과 상위에 올라온 이유를 알 수 있습니다.
검색 품질이 기대에 못 미칠 때 원인이 Description의 어떤 표현에 있는지 추적이 가능합니다.
추적된 원인을 통해 모델을 다시 학습시키는 것이 아닌, 추출 프롬프트만 수정하여 표현을 바꿀 수 있어서 개선 사이클이 빨라집니다.
CLIP 기반은 모델을 교체하거나 파인튜닝해야 표현 공간을 바꿀 수 있어 반복 개선의 비용이 큽니다.
이 네 가지 강점의 핵심은 이미지라는 modality를 텍스트 공간으로 통일함으로써 검색 대상도 질의도 같은 공간 위에서 다룰 수 있게 된다는 점입니다.
4. Deep Dive 2 — Query Expansion에 강화학습 개념을 적용하다
4.1. 문제 상황
3장에서 Description 기반의 Hybrid Search가 동작하는 환경을 만들었습니다.
그 위에서 다른 종류의 문제가 드러났습니다.
사용자 질의가 짧거나 모호할 때 Recall (검색 결과 상위에 정답이 포함되는 비율)이 눈에 띄게 낮았습니다.
예를 들어 “여름 소재” 같은 2~3 단어짜리 질의는 매칭되는 Description이 제한적이었습니다.
한 이미지의 Description 안에는 “해변 리조트 분위기”, “청량한 파란 하늘”, “자외선 차단” 같은 다양한 표현이 들어있는데, “여름 소재”라는 표면적 어휘로는 이 표현들을 모두 포착하기 어렵습니다.
원본 질의의 표면적 어휘에만 의존해서는 같은 의미를 담은 다양한 Description의 표현을 충분히 잡지 못한다는 것이 핵심 문제였습니다.
이 문제를 풀기 위해 사용자 질의를 검색 직전에 한 번 더 가공하는 단계 (Query Rewrite)를 도입하기로 결정했습니다.
4.2. 세 가지 접근
Query Rewrite에는 크게 세 가지 접근이 알려져 있습니다.
접근 A — Augmentation (쿼리 보강)
원본 질의를 더 자세하게 풀어 한 개의 풍부한 질의로 만드는 방식입니다.
e.g., “상품누끼컷” → “배경을 제거하고 상품만 깔끔하게 오려낸 이미지”.
어려운 단어를 풀어주거나 누락된 맥락을 더해 검색에 유리한 형태로 보강합니다.
접근 B — Expansion (쿼리 확장)
원본 질의를 다양한 표현으로 변형하여 여러 개의 쿼리를 만드는 방식입니다.
e.g., “여름철 바캉스를 연상시키는 실사 배경의 연출제품컷”
원본 질의에 대한 가상의 답변 텍스트를 LLM으로 생성한 뒤, 그 가상 답변으로 검색하는 방식입니다.
검색 대상인 Description과 비슷한 결의 텍스트가 질의 쪽에서 만들어지므로 임베딩 공간 안에서의 거리가 가까워질 수 있다는 직관에서 출발합니다.
비교 결과
같은 평가 환경 (Description 기반 인덱스, Hybrid Search) 위에서 세 가지 접근을 측정했습니다.
Recall@30은 검색 결과 상위 30개 안에 정답이 포함되는 비율을 가리킵니다.
본문의 수치는 PoC 환경에서 측정한 값으로, 실제 제품의 최종 성능과는 다를 수 있습니다.
접근
Recall@30
Augmentation
0.51
Expansion
0.66
HyDE (Query Description)
0.59
Expansion의 개선 폭이 가장 컸기 때문에 이 접근을 채택했습니다.
직관적으로도 설명됩니다.
광고 소재의 Description은 같은 시각적 의미를 두고도 표현이 매우 다양해질 수 있는 텍스트입니다.
원본 질의 하나만으로 그 다양성을 모두 잡기보다, 여러 변형 쿼리로 의미 공간을 폭넓게 훑는 쪽이 매칭 누락을 줄이는 데 더 효과적이었습니다.
4.3. Expansion 적용에서 마주친 문제
Expansion의 동작은 단순합니다.
LLM이 원본 질의를 받아 N개의 변형 쿼리를 생성하고 각 쿼리로 따로 검색해서 나온 결과들을 결합 (fusion)하는 구조입니다.
중앙의 다트 한 발이 원본 쿼리, 주변의 다트들이 확장 쿼리. 모두에게 같은 무게를 주면 평균이 중심에서 벗어난다.
그런데 단순한 결합 방식에 문제가 있었습니다.
원본과 확장 쿼리에 동등한 가중치를 주면 확장을 아예 쓰지 않은 경우보다 Recall@30이 오히려 낮아졌습니다 (정확한 수치는 4.5절의 표에서 확인할 수 있습니다).
확장 쿼리는 LLM이 원본을 보고 만든 변형이라 사용자 의도와 어긋난 것도 섞입니다.
원본과 같은 가중치로 합치면 이런 어긋난 변형들이 결과를 끌어내려 확장으로 얻은 Recall 향상이 그만큼 줄어듭니다.
4.4. Exploitation vs Exploration
이 시점에서 강화학습의 한 개념이 떠올랐습니다.
Exploitation과 Exploration의 trade-off입니다.
Exploitation: 이미 알고 있는 좋은 선택지를 활용하는 것
Exploration: 새로운 선택지를 탐색하여 더 좋은 선택지를 발견할 가능성을 키우는 것
강화학습에서 이 둘 사이의 균형을 어떻게 잡느냐가 전체 성능을 결정합니다.
너무 Exploitation만 하면 새로운 가능성을 놓치고, 너무 Exploration만 하면 이미 검증된 좋은 선택을 활용하지 못합니다.
Query Expansion의 상황도 정확히 같은 구조였습니다.
Original Query = Exploitation: 사용자가 명시적으로 표현한 가장 신뢰도 높은 의도
Expanded Queries = Exploration: 사용자가 명시하지 않은 다양한 표현을 탐색하는 시도
원본 쿼리와 확장 쿼리를 동등하게 결합한다는 것은 Exploitation과 Exploration의 비중을 1:N (N = 확장 쿼리 개수)로 설정해서 Exploration 쪽으로 크게 기울인다는 뜻이 됩니다.
이 비중이 너무 한쪽으로 쏠렸기 때문에 결과가 나빠진 것이라는 가설을 세웠습니다.
4.5. Exploration Weight의 도입
가설을 검증하기 위해 결합 방식을 다음과 같이 바꿨습니다.
원본 쿼리의 결과는 가중치 1.0으로 고정하고, 확장 쿼리들의 결과에는 별도의 가중치 exploration_weight를 부여합니다.
결과 통합은 Weighted RRF (Reciprocal Rank Fusion)로 처리합니다.
여기서 weight_i는 i번째 쿼리에 부여된 가중치 (원본은 1.0, 확장 쿼리는 exploration_weight), rank_i는 그 쿼리에서 해당 문서가 등장한 순위, k는 상위 순위의 영향이 과도해지지 않도록 순위 차이를 완만하게 만드는 상수입니다.
exploration_weight의 정의는 직관적으로 다음과 같습니다.
exploration_weight = 0.0: 확장 쿼리들의 결과를 완전히 무시. 원본 쿼리만 사용 (순수 Exploitation)
exploration_weight = 1.0: 원본과 확장 쿼리들에 동등한 가중치 부여. 가장 강한 Exploration
0.0 < exploration_weight < 1.0: 원본을 우선시하면서 확장 쿼리의 신호도 일부 반영
최적 weight 탐색
exploration_weight를 0.0부터 1.0까지 0.1 단위로 sweep하여 측정했습니다.
대표 결과 (Recall@30 기준)만 추리면 다음과 같습니다.
exploration_weight
Recall@30
0.0 (원본만)
0.80
0.2 (채택)
0.86
0.5
0.83
0.7
0.81
1.0 (동등 가중치)
0.77
(이 표의 수치는 4.2 이후 환경이 발전된 후속 평가 기준입니다.)
가장 높은 Recall@30을 보인 지점은 exploration_weight = 0.2였습니다.
원본만 쓰는 경우 (0.80)와 동등 가중치인 경우 (0.77) 둘 다 채택값 (0.86)보다 낮습니다.
도입 전후 성능 변화
Exploration Weight 도입의 효과는 두 비교에서 모두 명확하게 드러납니다.
원본만 사용 (exploration_weight = 0.0)과 비교: Recall@30 0.80 → 0.86 (절대값 +0.06, 상대 +7.5%)
원본 우선 + 확장의 일부 반영이라는 균형 잡힌 설계가 두 극단보다 모두 더 좋은 성능을 만들어냈습니다.
이는 Exploitation과 Exploration의 trade-off라는 강화학습의 익숙한 개념을 검색이라는 전혀 다른 도메인에 그대로 가져와 풀어낸 사례입니다.
5. 예상을 뒤집은 발견들
PoC 진행 중 직관적으로 옳아 보였던 가설들이 실측에서 반대 방향의 결과를 내는 사례가 여러 번 있었습니다.
이 장에서는 그중 두 가지를 정리합니다.
두 사례는 각각 Description과 Query Expansion 영역에서 일어났지만 공통된 패턴을 보여줍니다.
5.1. “더 자세히 설명하면 더 잘 찾을 줄 알았는데”
Description의 품질을 높이기 위한 자연스러운 시도 중 하나는 “더 길게 쓰게 하는 것”이었습니다.
가설은 단순했습니다.
각 카테고리에 더 많은 문장이 들어가면 표현이 풍부해져 다양한 질의에 더 잘 매칭될 것이다.
구체적으로는 Description 추출 프롬프트에 다음과 같은 지침을 추가했습니다.
각 카테고리 내용은 최소 3 문장, 최대 5 문장을 포함해야 합니다.
길이 조건 적용 전후를 Recall@30으로 측정했습니다.
지표
길이 조건 없음
길이 조건 추가
Recall@30
0.85
0.82 (↓)
결과는 직관과 반대로 Recall@30이 떨어졌습니다.
원인은 다음과 같이 정리됩니다.
문장이 길어질수록 카테고리 안에 핵심 묘사뿐 아니라 부수적인 묘사도 함께 들어갑니다.
검색 임베딩 입장에서 이 부수적인 묘사는 신호가 아니라 노이즈로 작용할 가능성이 큽니다.
풍부함을 더하려던 의도가 매칭 신호를 흐리는 방향으로 작용한 셈입니다.
길이 자체가 답이 아니라는 점이 이 발견의 핵심 교훈이었습니다.
5.2. “Expansion 프롬프트에 Description 어휘 힌트를 주면 더 잘 될 줄 알았는데”
Expansion 자체의 효과를 확인한 뒤, Expansion 프롬프트를 더 다듬으면 추가 개선이 있을 것이라고 기대했습니다.
가설은 다음과 같았습니다.
확장된 쿼리들이 검색 대상인 Description의 어휘·문체와 닮을수록 임베딩 공간 안에서의 거리가 더 가까워져 매칭이 좋아질 것이다.
이 가설에 따라 Expansion 프롬프트에 다음과 같은 지침과 예시를 추가했습니다.
광고 description에 자주 등장하는 어휘와 패턴을 반영하도록 한다.
NDCG@10 (검색 결과 상위 10개의 순위 품질을 평가하는 지표) 기준으로 측정했고 결과는 예상과 정반대였습니다.
지표
어휘 힌트 없음
어휘 힌트 추가
NDCG@10
0.55
0.44 (↓)
상대 변화 기준 약 -20%.
PoC에서 비교한 여러 변형 중에서도 큰 폭의 하락이었습니다.
원인을 추정해보면 다음과 같습니다.
“광고 description에 자주 등장하는 어휘/패턴”이라는 지침은 LLM에게 명시적인 어휘 편향을 주문하는 셈입니다.
확장 쿼리들이 일정한 어휘 셋으로 쏠리면 원본 질의가 가졌던 다양한 의미 공간을 폭넓게 훑는 Expansion의 본래 강점이 좁아집니다.
확장의 목적이 “다양한 표현으로 의미 공간을 넓히는 것”이었는데 어휘 힌트는 그 다양성을 오히려 제약하는 방향으로 작용했습니다.
친절해 보였던 힌트가 LLM의 출력을 한 쪽으로 끌어당기는 편향으로 작용한 사례입니다.
5.3. 종합 인사이트 — LLM을 다룰 때 직관이 빗나가는 지점들
두 가지 발견은 서로 다른 영역 (Description, Query Expansion)에서 일어났지만 자세히 보면 공통된 패턴을 공유합니다.
길게, 그리고 친절하게.
LLM 시스템을 더 잘 만들려는 직관적인 시도들이 자주 반대 방향으로 작용했습니다.
더 길게: Description에 길이를 강제했더니 Recall이 떨어졌습니다.
더 친절하게: Query Expansion에 Description 어휘 힌트를 줬더니 다양성이 사라지고 성능이 떨어졌습니다. 또한 별도의 시도에서 사용자 예상 질의 키워드를 Description 추출 프롬프트의 예시로 삽입했더니, 일부 카테고리에서 키워드 편향이 나타나 일반화가 떨어지는 결과도 함께 관찰됐습니다.
이 사례들은 LLM의 동작 특성에서 공통된 결을 보여줍니다.
긴 텍스트는 신호로 작용하기보다 노이즈로 작용하기 쉽습니다.
친절한 예시는 LLM의 출력을 그 예시의 방향으로 끌어당기는 편향이 됩니다.
이 PoC의 본질이 가설 검증이라는 점에서 반복되는 교훈은 단순합니다.
“빠르게 가설을 세우되 실측 없이 그 가설을 채택하지 않는다.”
직관이 빗나가는 지점일수록 더 깊은 통찰이 숨어있을 가능성이 높다는 점이 어쩌면 이 PoC의 가장 큰 수확이었을지도 모릅니다.
6. 마무리
자연어 질의로 광고 소재 이미지를 검색하는 PoC를 진행했습니다.
이 글에서는 그 과정에서 마주친 핵심 결정과 발견을 세 가지 Deep Dive로 풀어냈습니다.
각 Deep Dive가 보여준 교훈은 다음과 같습니다.
3장 — 텍스트 공간으로의 통일이 후속 작업의 기반이 된다
이미지를 텍스트 공간으로 옮긴 덕분에 사용자 질의와 검색 대상이 같은 공간에 놓였고 그 위에서 Hybrid Search를 비롯한 검색 설계가 이어졌습니다.
첫 설계 결정이 이후 모든 선택지를 좌우한 사례입니다.
4장 — 강화학습 개념이 검색 문제의 도구가 된다
Query Expansion의 동등 가중치 문제를 강화학습의 Exploitation vs Exploration trade-off로 풀어냈습니다.
익숙한 개념을 다른 도메인에 적용하는 것만으로도 막혀 있던 문제가 풀리는 경험이었습니다.
5장 — 직관보다 실측을 신뢰한다
길게·친절하게 같은 직관적 시도들이 LLM의 동작 특성과 충돌하면서 반대 방향으로 작용했습니다.
LLM은 사람의 직관과 다르게 움직인다는 점이 반복적으로 확인된 발견이었습니다.
이렇게 세 가지 교훈을 정리하며 본 PoC를 마칩니다.
마지막으로 개인적인 소감을 덧붙이자면, 가장 흥미로웠던 건 익숙한 개념이 전혀 다른 문제의 도구가 되는 순간이었습니다.
강화학습의 Exploitation vs Exploration이 검색의 가중치 설계로 이어지는 걸 보면서, 어느 한 분야에서 익힌 개념의 쓰임새가 생각보다 훨씬 멀리까지 닿을 수 있다는 걸 새삼 느꼈습니다.
다음에 마주할 문제에서도 다른 도메인의 도구를 한 번씩 끌어와보는 자세를 잃지 않으려 합니다.
LEVER Xpert AI팀은 마케터가 AI를 통해 수고로운 작업들을 자동화하고 더욱 핵심적인 전략에 집중할 수 있는 제품을 하나씩 만들어나가고자 합니다.
소재 검색은 그 로드맵의 첫 단계로, 앞으로 방대한 데이터와 매드업이 보유한 도메인 지식을 기반으로 다양한 모델과 에이전트를 만들어나가고자 합니다.
]]>dmlee최적의 메시지 브로커를 찾아서2024-12-27T00:00:00+00:002024-12-27T00:00:00+00:00https://tech.madup.com/choosing-the-right-message-broker매드업에서는 프리즘이라는 시스템을 사용하여 광고 데이터를 수집하고 있습니다.
프리즘에 대해서는 여기를 참고해 주세요.
프리즘은 여러 마이크로 서비스들로 이루어져 있고, 마이크로 서비스들 간의 통신을 위해 메시지 기반 비동기 통신 방식을 사용하고 있습니다.
따라서 메시지들을 안정적이고 효율적으로 전달할 수 있는 메시지 브로커를 선택하는 것은 매우 중요한 문제입니다.
이 글에서는 프리즘이 발전하는 과정에서 실제로 사용한 메시지 브로커의 변천사를 소개하고자 합니다.
어떠한 이유로 사용하던 메시지 브로커를 변경하게 되었는지 실제 경험에 기반한 내용을 이야기해 보겠습니다.
프리즘을 위한 메시지 브로커가 갖춰야 할 기능 요건들
메시지 브로커를 사용할 때 이상적인 동작은 “정확히 한 번”(Exactly Once) 전달일 것입니다.
하지만 현실적으로는 어렵기 때문에 “최소 한 번”(At Least Once) 전달과 “최대 한 번”(At Most Once) 전달 중에 선택을 하게 됩니다.
프리즘은 메시지를 중복으로 처리해도 문제가 없는 시스템이기 때문에 최소 한 번 전달을 현실적인 목표로 잡았습니다.
프리즘에서 필요한 메시지 브로커가 갖춰야 할 기능 요건들은 다음과 같습니다.
안정적인 메시지 전달 (최소 한 번 전달)
프리즘은 쿠버네티스 환경에서 운영되고 있습니다.
쿠버네티스 환경에서 파드의 종료는 배포나 HPA(Horizontal Pod Autoscaling) 등으로 인해 언제든 발생할 수 있기 떄문에, 파드가 종료되는 경우에도 메시지가 유실되지 않고 전달될 수 있어야 합니다.
유연한 메시지 컨슈머(consumer) 스케일링
프리즘의 각 마이크로 서비스는 HPA를 사용하여 필요에 따라 파드 개수가 적절하게 조정됩니다.
따라서 메시지 컨슈머의 개수가 변하는 경우에도 큰 지연 시간 없이 메시지를 안정적으로 가져올 수 있어야 합니다.
효율적인 메시지 분배
프리즘에서 수집하는 광고 데이터는 광고주에 따라 사이즈 차이가 크며, 그에 따라 소요되는 수집 시간도 차이가 큽니다.
데이터 사이즈가 작은 광고주의 경우 1분 안에 수집이 끝나기도 하지만, 사이즈가 큰 광고주는 20~30분이 걸리기도 합니다.
이처럼 메시지 처리 시간의 편차가 큰 편이기 때문에 일률적으로 메시지를 분배하는 라운드 로빈(Round Robin)과 같은 방식은 적합하지 않습니다.
여유가 있는 메시지 컨슈머에게 우선적으로 메시지를 전달할 수 있어야 합니다.
실제로는 더 많은 기능 요건들이 있지만, 여기서는 이 글과 관련된 것들만 언급했습니다.
이러한 요건들에 맞는 최적의 메시지 브로커를 한 번에 찾았다면 좋았겠지만 아쉽게도 그러지 못 했습니다.
지금부터는 프리즘 운영 환경에서 실제로 사용했었던 메시지 브로커인 SQS와 카프카, 그리고 현재 사용 중인 RabbitMQ에 대해 얘기해 보겠습니다.
SQS
새로운(v2) 프리즘을 만들면서 처음 사용한 메시지 브로커는 Amazon SQS(Simple Queue Service)였습니다.
AWS를 사용하고 있기 때문에 쉽게 적용할 수 있었고, 다른 팀에서도 사용하고 있었기 때문에 큰 고민 없이 선택했습니다.
그리고 현재도 프리즘 외부와 메시지를 주고 받을 때는 사용하고 있지만, 프리즘 내부에서는 사용하고 있지 않습니다.
프리즘 내부에서 SQS를 사용하지 않기로 결정한 가장 큰 이유는 기능 요건 1번 “안정적인 메시지 전달”과 관련이 있습니다.
SQS는 메시지를 수신한 후에 처리가 완료되면 해당 메시지를 삭제해야 합니다.
그리고 메시지의 최소 한 번 전달을 보장하기 위해, 수신 후 삭제되지 않은 상태에서 visibility timeout이 지나면 메시지를 다시 수신하게 됩니다.
이미지 출처: https://docs.aws.amazon.com/ko_kr/AWSSimpleQueueService/latest/SQSDeveloperGuide/sqs-visibility-timeout.html
프리즘에서는 이 visibility timeout 값을 어떻게 설정할지에 대한 고민이 많았습니다.
특히 앞에서 얘기한 것처럼 프리즘의 메시지는 처리하는데 소요되는 시간의 편차가 크기 때문에 적정한 값을 찾는 것이 어려웠습니다.
값을 크게 설정하면, 메시지를 처리하던 파드가 종료되었을 때 다시 메시지를 수신하기까지의 텀이 길어지는 문제가 있습니다.
반대로 값을 작게 설정하면, 메시지를 처리 중인데도 다시 동일한 메시지를 수신하게 되고, 메시지가 중복 처리되는 것을 막기 위해 별도의 처리를 해야 했습니다.
앞에서 언급했던 것처럼 프리즘은 메시지를 중복으로 처리해도 문제가 없긴 하나, 불필요한 자원 사용을 줄이기 위해 중복 처리되지 않도록 했습니다.
이러한 SQS 특성은 비연결성(connectionless) 때문인 것으로 생각됩니다.
메시지 컨슈머와 연결을 유지하고 관리하는 형태가 아니기 때문에, 컨슈머가 종료된 것을 인지하지 못 하고 visibility timeout과 같은 장치가 필요한 것이죠.
아무튼 visibility timeout과 관련된 SQS의 동작 방식으로 인해 애플리케이션이 불필요하게 복잡해지는 것으로 보였고,
그래서 고민 끝에 SQS 대신 카프카를 도입하기로 했습니다.
카프카(Kafka)
카프카를 사용하면서 SQS의 visibility timeout과 관련된 코드들을 삭제할 수 있었습니다.
카프카는 컨슈머 그룹이 각 파티션 별로 가지고 있는 현재 오프셋(offset)을 참조하여 다음에 가져올 메시지를 결정합니다.
어떤 메시지가 처리 중에 문제가 발생하여 해당 오프셋이 커밋되지 않았다면, 다음에 그 메시지를 다시 가져오도록 되어 있어 최소 한 번 전달을 보장하고 있습니다.
또한 브로커가 컨슈머 그룹을 관리하도록 되어 있어, 특정 컨슈머가 의도치 않게 종료되면 리밸런싱을 통해 해당 컨슈머가 메시지를 읽어 들이던 파티션들을 다른 컨슈머에게 할당하게 됩니다.
하지만 카프카를 계속 사용하면서 SQS를 사용할 때는 없었던 새로운 문제들이 등장했습니다.
첫 번째 문제는 컨슈머 그룹 리밸런싱과 관련이 있습니다. 카프카는 컨슈머 그룹에 속한 컨슈머의 개수가 바뀌면 리밸런싱을 통해 파티션을 재분배 합니다.
그런데 메시지 처리가 오래 걸리는 경우, 해당 컨슈머가 리밸런싱 과정에 참여하지 못 하면서 리밸런싱이 상당 시간 지연되는 문제가 있었습니다.
이를 해결하기 위해 메시지를 수신하는 스레드와 처리하는 스레드를 분리하여 리밸런싱 지연 시간을 줄일 수는 있었지만, 그로 인해 다른 문제들이 생겨났고, 그 문제들을 해결하기 위해 애플리케이션은 더 복잡해졌습니다.
두 번째 문제는 카프카의 파티션 구조와 관련이 있습니다. 카프카는 토픽의 메시지들을 파티션들에 나눠서 저장합니다.
예를 들어 토픽이 5개의 파티션을 가지고 있고 총 1000개의 메시지가 저장되어 있다면, 평균적으로 각 파티션은 200개 정도의 메시지를 가지고 있을 것입니다.
그리고 동일한 그룹에 속하는 컨슈머들은 이 파티션들을 나눠서 할당받아 그 안에 있는 메시지들을 순서대로 가져오게 됩니다.
그런데 앞에서 얘기했던 것처럼 프리즘의 메시지는 처리 시간의 편차가 큰 편입니다.
만약 특정 파티션에 처리 시간이 매우 오래 걸리는 메시지가 들어 있다면 어떻게 될까요?
오래 걸리는 메시지 뒤에 있는 메시지들은 처리가 되기까지 상당한 시간을 기다려야 하고,
그러다 보니 해당 파티션을 할당받은 컨슈머만 lag이 증가하는 원치 않는 상황이 발생했습니다.
이러한 문제들 때문에 카프카가 프리즘에 맞는 메시지 브로커인지를 다시 고민하게 되었고,
더 나은 대안으로 RabbitMQ를 선택하게 되었습니다.
그러면 마지막으로 왜 RabbitMQ를 선택했는지 얘기해 보겠습니다.
RabbitMQ
RabbitMQ는 AMQP(Advanced Message Queuing Protocol)를 구현한 메시지 브로커입니다.
많은 특징들이 있지만 여기서는 프리즘에 도입할 때 중요하게 생각했던 점들만 얘기해 보겠습니다.
첫 번째는 최소 한 번 전달을 보장하기 위한 기능입니다.
RabbitMQ는 메시지를 수신한 컨슈머가 메시지를 처리한 후 ack(Acknowledge)를 전송해서 처리가 완료되었음을 알리도록 되어 있습니다.
그래서 RabbitMQ 큐에 있는 메시지는 처음에는 ready 상태였다가, 컨슈머로 메시지가 전달되면 unacked로 바뀌게 되고,
컨슈머가 ack를 전송하면 큐에서 삭제됩니다.
만약 컨슈머가 메시지에 대한 ack를 전송하지 못 하고 종료되면, 그 메시지는 다시 ready 상태가 되어 다른 컨슈머에게 전달 됩니다.
그리고 RabbitMQ 브로커와 컨슈머는 연결을 맺고 있습니다.
그래서 컨슈머가 OOM(Out of Memory) 등의 이유로 인해 비정상적으로 종료되어도, 브로커가 연결이 끊어진 것을 감지하고 해당 컨슈머가 처리하고 있던 메시지들을 다시 ready 상태로 변경합니다.
두 번째는 컨슈머들의 스케일링이 쉽습니다.
카프카는 동일한 그룹의 컨슈머 개수를 늘리기 위해서는 파티션 개수를 맞춰서 늘려줘야 합니다.
그리고 컨슈머 개수가 바뀌면 리밸런싱이라는 과정을 통해 파티션들을 컨슈머들에게 재분배하게 되는데,
컨슈머 개수가 자주 바뀌는 경우에는 빈번한 리밸런싱으로 인해 메시지 처리가 지연되는 문제가 있었습니다.
메시지를 처리하는 시간이 짧고 균일하다면 크게 문제가 되지 않지만, 프리즘은 편차가 크다보니 문제가 되었습니다.
하지만 RabbitMQ는 동일한 큐에 대해 컨슈머가 추가, 삭제되는 경우에 별도의 리밸런싱과 같은 작업이 필요하지 않아
컨슈머들의 개수를 빈번하게 변경해도 문제가 없습니다.
세 번째는 메시지를 효율적으로 분배하는 것입니다.
앞에서 언급했던 것처럼 카프카의 경우 메시지들이 파티션들에 나눠서 저장되고, 오프셋을 커밋하는 구조라서 잘못하면 특정 파티션의 메시지들만 처리가 지연되는 문제가 있었습니다.
RabbitMQ는 큐에 있는 메시지들이 컨슈머로 전달되고 ack를 받아서 삭제되는 것과 같은 처리가 각 메시지에 대해 개별적으로 이뤄지기 때문에 메시지를 효율적으로 전달할 수 있었습니다.
여기까지 주된 3가지 이유에 대해 얘기해 봤는데, 이에 더해 몇 가지 장점을 더 소개해 보겠습니다.
프리즘은 매드업의 광고사업부를 위한 데이터를 수집하는 것을 넘어, 레버 엑스퍼트를 통해 다양한 고객의 광고 데이터를 수집하고 있습니다. (레버 엑스퍼트는 SaaS 형태로 제공되는 마케팅 업무 자동화 솔루션입니다.)
SaaS에서는 테넌트 간의 격리(isolation)가 중요한 문제인데요.
격리의 수준과 방법은 다양하지만, 여기서는 테넌트 별로 메시지 큐를 분리하는 상황을 얘기해 보겠습니다.
테넌트 ID에 따라 다른 메시지 큐로 메시지를 보내야 하는 기능을 어떻게 쉽게 구현할 수 있을까요?
RabbitMQ에는 exchange라는 개념이 존재합니다. 메시지 프로듀서가 exchange로 메시지를 보내면서 라우팅 키를 설정하면,
라우팅 키에 따라 미리 바인딩 된 큐로 메시지가 자동으로 전달됩니다.
테넌트 ID를 라우팅 키로 사용하면, 프로듀서는 exchange에만 메시지를 보내면 되고, exchange가 라우팅 키에 따라 메시지를 해당 큐로 넣어 주기 때문에 매우 편리합니다.
이러한 exchange, 라우팅 기능을 사용하면 메시지를 다양한 형태로 전달할 수 있습니다.
또 다른 장점은 우선순위 큐를 제공한다는 것인데, 큐에 있는 메시지들 중에서 우선순위가 높은 메시지들이 먼저 컨슈머로 전달되어 처리되도록 할 수 있습니다.
이런 우선순위 기능을 사용하면 큐를 분리하지 않고도 우선순위가 높은 요청(e.g. 유료 플랜 고객의 요청)을 먼저 처리하고, 우선순위가 낮은 요청(e.g. 급하지 않은 시스템 내부의 요청)은 나중에 처리되도록 할 수도 있습니다.
글을 마치며
지금까지 프리즘에서 사용하는 메시지 브로커를 왜 변경해왔는지 얘기해 보았습니다.
저희 팀은 SQS, 카프카를 사용했을 때 겪은 문제들을 해결하기 위해 결국 RabbitMQ를 선택했지만,
그것이 RabbitMQ가 SQS, 카프카보다 더 우수하다는 의미는 아닙니다.
단지 프리즘의 요구 사항에 가장 잘 맞았던 것 뿐입니다.
서비스에 따라 요구 사항들이 다를 것이고, 그에 맞는 메시지 브로커가 있을 것입니다.
중요한 것은 어떤 것이 우리에게 가장 적합한지를 잘 찾아가는 것이라고 생각합니다.
이렇게 적고나니 약간의 부끄러움이 밀려옵니다.
처음부터 서비스의 요구 사항들과 각 메시지 브로커의 특징들을 잘 파악해서 최선의 선택을 했다면 얼마나 좋았을까요?
그랬다면 좋았겠지만 현실은 항상 달콤하지만은 않은 것 같습니다.
중요한 것은 현재의 문제를 직시하고, 더나은 대안을 고민하고, 실행에 옮기는 것이 아닐까 생각합니다.
끝으로 저희 팀이 겪은 시행 착오가 누군가에겐 도움이 되기를 바라며 이 글을 마칩니다.
읽어 주셔서 감사합니다.
]]>Andy사진으로 둘러보는 AWS re:Invent 2023 후기2023-12-19T00:00:00+00:002023-12-19T00:00:00+00:00https://tech.madup.com/aws-reinvent안녕하세요. AdTech(Advertising technology) 스타트업 매드업에서 데이터 엔지니어 겸 사이트 신뢰성 엔지니어(SRE, Site Reliability Engineer)로 근무하고 있는 백재연입니다. 이번 글에서는 올해 라스베가스에서 열린 AWS re:Invent를 다녀온 후기를 다루려고 합니다. 키노트나 세션 등 기술과 관련된 콘텐츠는 유튜브와 AWS 공식 블로그에 잘 정리가 되어 있으니 생략하고, 처음 이 행사에 참석했던 입장에서 전반적인 행사 흐름과 체험을 위주로 정리해 봤습니다. 목차는 다음과 같습니다.
현재 매드업과 계약된 MSP를 통해 아시아나항공 전세기로 라스베가스 공항까지 직항으로 갈 수 있었습니다. 역시 국내 항공이라 그런지 한국사람들만 있어서 매너가 좋은 건지 쾌적한 비행기로 편하게 이동할 수 있었습니다. 비행 시간은 갈 때 11시간, 올 때 13시간 걸렸네요. 미국 땅을 밟는 게 이번이 처음이 아니고, 더욱이 전세기라서 비교적 쉽게 입국심사를 통과할 수 있었습니다. ( “너도 AWS 때문에 온 거야?” 하고 통과.. )
라스베가스 공항입니다
라스베가스는 사막에 있는 오아시스라는 별명을 갖고 있습니다. 실제로 위성지도를 살펴보면 사막 가운데 있지요. 그런 탓에 기후가 굉장히 건조합니다. 입술이 바짝바짝 마르는 느낌을 행사 기간 내내 느낄 수 있었네요. 게다가 (비염도 있지만) 코를 풀 때마다 피딱지가 나와서 고통스러웠습니다. 가시는 분들은 이런 점을 참고하셔서 쾌적한 여행이 되시길 바랍니다.
라스베가스 주변은 전부 사막입니다
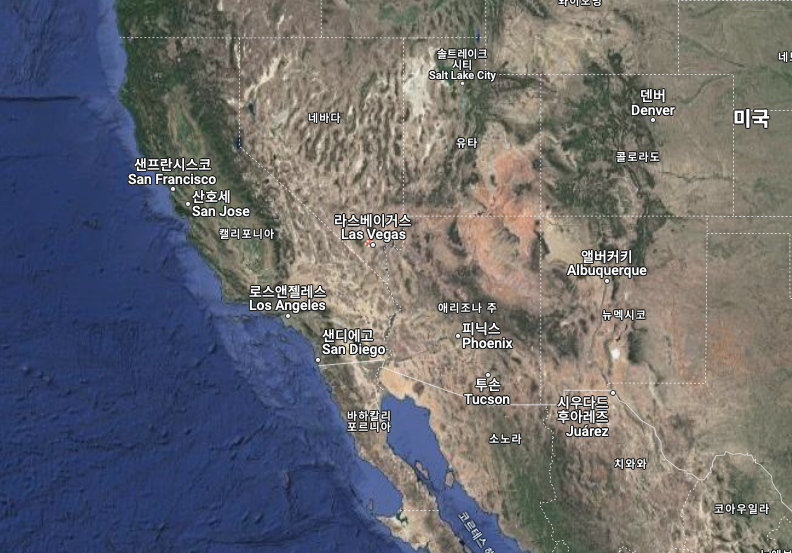
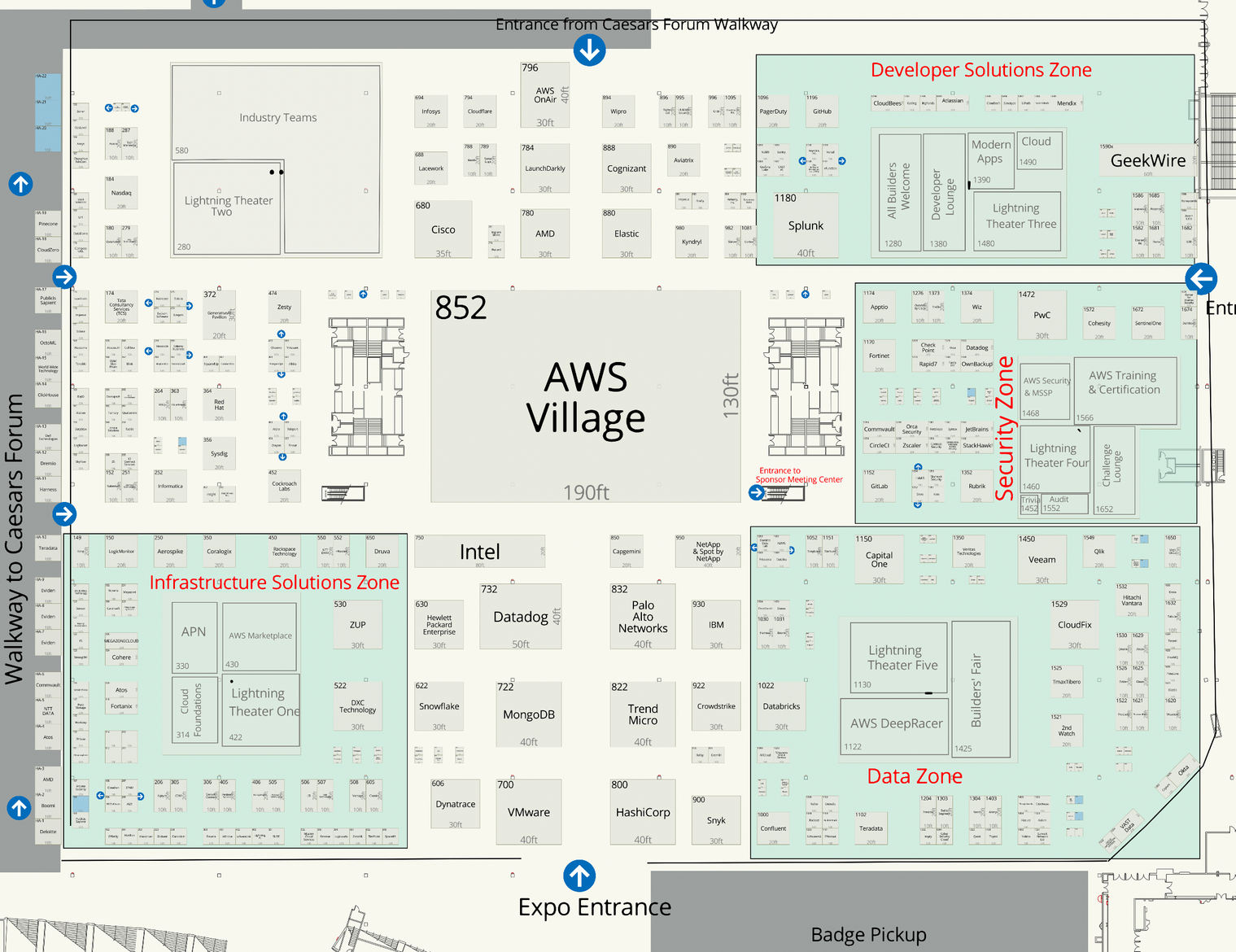
리인벤트가 진행되는 장소는 라스베가스 스트립으로 물가가 꽤 비싼 편입니다. 대체로 라스베가스는 물가가 저렴하다고 하는데 딱 이곳 스트립만 비싸다고 하네요. 아무래도 워낙 유명한 관광지라서 그런 것 같습니다. 그럼 리인벤트 베뉴 위치를 살펴볼까요? 아래 지도를 봐주세요. 주황색과 파란색으로 나눠지는데 베뉴는 주황색입니다. 그중에도 3번 베네시안은 키노트 행사가 진행되는 만큼 메인 행사장이라고 볼 수 있습니다. 가장 규모가 크기도 하고요. 파란색으로 표기된 호텔은 행사가 있진 않습니다. 그리고 색상 표기가 없는 곳에도 호텔이 있어요. 그럼 파란색으로 색칠된 호텔은 무엇이 다르냐는 건데 행사 마지막날 re:Play 파티를 갈 때 파란색 호텔에서도 버스를 운행합니다. 지도에 표시되지 않은 호텔에는 버스 운행이 없습니다. 저는 시저스 팰리스(8번과 12번 사이)에 묶었는데 버스가 없어서 가까운 벨라지오(12)로 넘어가서 버스를 탔네요.
행사장 지도
아래 위성지도로 봐주시면 거리가 대충 짐작되실 겁니다. 3번 베네시안에서 6번 만달레이베이까지 거리를 가늠해 보세요. 절대 걸어갈 수 있는 거리가 아닙니다. 리인벤트에서 제공하는 캠퍼스 셔틀을 타도 최소 10~15분은 걸립니다.
위성지도
아, 참고로 호텔 규모도 굉장히 커서 호텔 안에서도 길을 잃는 게 가능할 지경입니다. 호텔 1층은 대부분 카지노로 되어 있는데 의도적으로 길을 어렵게 만들어놨다는 이야기도 있더라고요. 호텔은 카지노 수익으로 운영되기 때문에 숙박은 상대적으로 저렴한 편이라고 합니다. 미국 내에서 이렇게 저렴한 호텔이 없다는 이야기도 들었습니다.
라스베가스 호텔 1층의 흔한 풍경
시차
아무래도 라스베가스 현지에서 업무를 보셔야 하는 분들도 계실 텐데요. 라스베가스는 서울보다 17시간 빠릅니다. 시간 계산은 라스베가스 기준으로 5시간을 더하고 낮밤을 바꿔주면 되는데, 예를 들어 라스베가스에서 밤 11시라면 5시간을 더해서 새벽 4시가 되죠. 여기에 낮밤을 바꿔주면 한국은 16시라고 생각하시면 되는 겁니다. 생각보다 겹치는 시간이 많아서 세션을 듣다가 슬랙 메시지 확인도 종종 했네요(티는 안 냈지만).
(라스베가스 시간 + 5) → 낮밤 전환 = 한국 시간
이제 행사장으로 들어가 봅니다.
리인벤트 시작! 배지 수령부터.
행사를 즐기려면 배지를 수령해야 합니다. 배지는 라스베가스 공항이나 메인 베뉴에서 받을 수 있습니다. 행사가 시작되는 월요일 오전에는 사람이 너무 많이 몰리니까 가급적 일요일에 미리 받는 게 좋습니다.
자격증과 하시코프 엠버서더 인증
Badge Pickup 장소에서 배지를 수령했으면 뒤편에 보이는 SWAG를 챙겨갈 수 있습니다. 이번 행사에 스웨그는 후드집업과 텀블러였습니다. 이제 다음날부터 라스베가스는 리인벤트 후드집업으로 물들어갑니다. 😁
베네시안에 배지와 스웨그 수령장소
그리고 위에 사진을 보시면 좌측 편에 Verify your AWS Certification이 있습니다. 이곳에서 credly.com 를 통해 만료되지 않은 AWS 자격증을 인증하면 배지에 체크 스티커를 붙여줍니다. 스크롤을 위로 올려서 제 배지를 봐주시면 됩니다. 자격증을 인증하면 누릴 수 있는 것들이 몇 개 있어서 급하게 자격증을 취득하고 갔습니다. 기왕 가는 김에 행사에서 누릴 수 있는 건 모두 누려보고 싶었거든요. 자격증 취득과 관련된 글은 SAA, SAP 후기와 DOP 후기에서 보실 수 있습니다.
SAA, SAP, DOP를 취득하고 갔습니다
리인벤트를 위해 자격증을 급하게 취득한 건 과연 옳은 선택이었을까요? 글을 계속 읽고 여러분이 판단해 보시죠(웃음). 당연히 자격증을 취득하는 과정 혹은 시험을 통해 성장하는 건 좋지만 저와 같은 목적이라면 고민을 해보셔야 할 겁니다.
리인벤트에 자격증이 있으면 뭐가 좋나요?
가장 큰 혜택은 자격증이 있는 사람만 들어갈 수 있는 공간이 있다는 겁니다. 생각보다 꽤 넓습니다. 호텔에 따라 다르지만 세션 중간에 앉아서 쉴 공간이 마땅하지 않은데 비교적 편히 쉴 수 있겠죠. 다과와 음료가 항상 비치되어 있습니다.
자격증이 있어야 들어갈 수 있는 공간
그리고 행사 이틀차(화요일)부터 자격증 인증을 받은 사람들에게 스웨그를 줍니다. 매번 같은지 모르겠지만 올해는 반팔 티셔츠였습니다. 티셔츠는 엑스포 부스만 돌아다녀도 꽤나 많이 얻을 수 있기 때문에 매력적인 스웨그인지는 잘 모르겠네요. 다음으로 레고를 줍니다.
"안녕? 위안은 안 되겠지만 자격증 취득한 거 축하해 😁"라고 말하는 것 같네요
오우, 아직 실망하기 이릅니다. 리인벤트 행사장을 돌아다녀보니까 사진 촬영해 주는 스팟이 세 군데 있는데요. 그중에 한 곳이 자격증을 취득해야 들어갈 수 있는 공간에 있으니까요. 사진 찍고 인증하는 걸 좋아하신다면 최고의 스팟이죠.
여기도 물론 줄을 서야 합니다
행사 막바지로 가면 줄이 없으니 굳이 줄 서서 급하게 찍을 필요 없습니다. 다른 사진 스팟도 마찬가지입니다. 이곳에서 찍은 사진은 메일주소를 입력해서 받게 됩니다. 나머지 두 곳은 현장에서 인화해서 줍니다.
"자격증 취득을 축하해. 사진찍고 갈래?"
아래와 같이 칠판과 (이름을 모르겠네요) 커다란 판에 각 회사의 이름이나 로고, 개성을 뽐낼 수 있습니다. 저도 소소하게 회사 로고를 그려봤습니다. 아무래도 원하는 색상이 100% 있는 건 아니라서 어려움은 있었네요.
간밤에 이렇게 누군가 작업을 해놓습니다. 이 작품들 이후에는 누구도 선뜻 손대지 못하더라고요… (오른쪽 사진은 AWS 한국 사용자 그룹에서 가져왔습니다)
식사
지정된 호텔에서 조식과 중식을 줍니다. 식당마다 메뉴는 다르기 복불복이 좀 있습니다. 왼쪽은 베네시안 식당인데 끝이 안 보일 정도로 넓습니다. “늦게 가서 자리가 없으면 어쩌지?” 같은 걱정은 하실 필요가 없습니다. 대충 수천 명은 동시에 식사가 가능한 공간입니다. 오른쪽은 만달레이베이 중식입니다. 뷔페식인데 라스베가스에서 먹었던 식사 중에 단연 최고였습니다. 너무 폭식해서 오후에 힘들었다는…
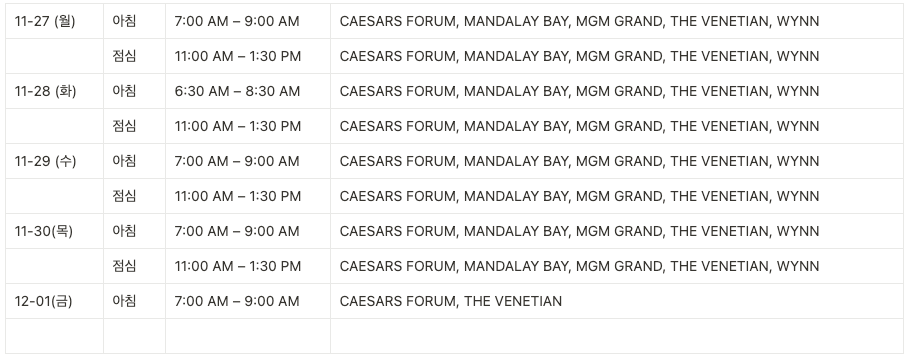
출발할 때 메모했던 건데 대충 시간대와 식사가 제공되는 호텔을 확인하실 수 있을 겁니다.
화요일 아침만 시간이 다르네요
커피는 식당을 포함해서 행사장 곳곳에서 카페인과 디카페인으로 나눠서 비치되어 있습니다. 그리고 호텔 복도에 간식이 세팅되는데 출출한 분들께는 도움이 되겠습니다.
제 취향은 아니었습니다만 다들 잘 드시더라고요
엑스포
엑스포는 AWS 기술을 활용한 아주 많은 회사들이 홍보 부스를 운영하는 공간입니다. 행사 첫날인 월요일 16시에 오픈합니다. 아래 보이는 이미지에 천막이 올라가는 순간 사람들이 엄청나게 몰린다고 하네요. 오픈 시간은 피해서 가시는 게 좋습니다. 너무 많은 인파에 치일 수 있으니까요.
오픈 전에는 베일 속에 감춰져 있습니다
오픈하면 인파가 어마어마합니다. 오픈런을 피해가 갔던 시간대에도 아래처럼 사람이 가득했으니까요. 참고로 올해는 하시코프를 비롯해서 스노우플레이크, 데이터독, 메가존 클라우드 등 엑스포에 한국 매니저 분들이 많이 참석하셨더라고요.
그래도 인파 흐름에 방향이 있습니다
특별히 방문하고 싶은 부스가 있다면 엑스포 지도를 참고하시면 좋습니다. 매년 달라지기 때문에 AWS Events 앱을 통해 확인하실 수 있을 겁니다. 2023년 지도는 참고 차원으로 남겨둡니다. 얼마나 넓은 공간인지 가늠하실 수 있겠죠?
해외에서도 커뮤니티 활동을 빼놓을 수 없겠죠? 저는 하시코프(HashiCorp) 엠버서더로 활동하고 있습니다. 이번 리인벤트에 하시코프가 에메랄드 스폰서로 들어왔는데요. 에메랄드 스폰서는 엑스포 부스 외에 다른 공간을 대여해서 운영하기도 합니다.
에메랄드 스폰서
하시코프의 경우 베네시안에 Chica Lounge를 사용했는데 엠버서더 자격으로 들어가서 푹 쉬다 나왔습니다. 보통은 사전에 예약된 고객이나 상담을 위해 운영되는 공간입니다. 왼쪽이 Chica Lounge 외관이고 오른쪽이 내부입니다. 위스키를 포함한 주류와 다과가 무료입니다. 위스키 이름도 독특했는데요. 저는 하시코프 제품 이름을 딴 terraform twist(사실 정확히는 기억이 안 납니다;)를 시음(?) 했습니다.
행사 기간 중에 가장 신났던 순간을 꼽으라면 역시 하시코프 부스를 방문했던 겁니다. 글로벌 커뮤니티 매니저를 만나서 이런저런 이야기를 했습니다. 아마도 한국에서 하시코프 엠버서더는 저 혼자 왔던 것 같네요. 그리고 평소 고민하던 기술 상담도 잘 받았습니다. 아, 하시코프도 자격증이 있으면 리인벤트를 더 잘 즐길 수 있을까 하여 테라폼 자격증도 급하게 취득했었는데 이건 아무 도움이 안 됐네요. 🤣
하시코프 글로벌 커뮤니티 매니저 자스민과 함께 🙂
한국 고객들을 위해 특별 제작 됐다는 스웨그도 받았습니다. 특히 4in1 충전기가 아주 마음에 듭니다. USB-C, 라이트닝, 애플워치 그리고 5핀인지 8핀인지 케이블까지. 제게 아주 필요한 아이템이었는데 기분 좋게 득템 했네요.
USB-C 아이폰과 에어팟, 애플워치를 동시에 충전!
그리고 부스를 돌아다니며 필요한 질문도 하고 꽤나 유익한 시간을 보낼 수 있었습니다. 제 부족한 영어 실력과 상관없이 문제를 이해하기 위해 노력해주고 해결책을 고민해 주셔서 감사했습니다. 왼쪽은 하시코프, 오른쪽은 레디스입니다. 질문과 답변은 당시에 제가 링크드인에 남겼던 글을 참고해주세요.
유쾌한 분위기!
그리고 또 다른 에메랄드 스폰서인 데이터독에서 운영하는 미끄럼틀입니다. 이런 거 있으면 꼭 해보는 사람이라 타봤는데 생각보다 무서워서 혼났습니다. 여기가 리인벤트에서 사진을 찍어주는 두 번째 장소입니다.
타는데 각오가 필요합니다..
세 번째 사진 스팟은 바로 이곳입니다. 여기도 즉석에서 사진을 뽑아주는데 줄이 아주 깁니다. 사람이 몰리지 않는 행사 후반부에 찍으시길 추천드립니다. 혹은 세션 오며 가며 사람이 없으면 바로 줄을 서시는 것도 방법입니다.
키노트와 세션
키노트는 소문대로 굉장합니다. 월~목까지 매일 키노트가 있는데 월요일만 오후(19시 30분)에 진행되고 나머지는 오전에 진행됩니다. 고로 월요일은 키노트 현장에서 맥주를 나눠줍니다.
키노트가 시작되기 전까지 화려한 공연이 이어집니다
세션은 일반적인 행사장 공간을 생각해도 됩니다. 세션은 어차피 유튜브로 나중에 편히 볼 수 있지만 현장에서 듣는 맛(?)을 따라오진 못합니다. 더욱이 영상은 뒤늦게 찾아보지 않게 되지 않나요? 아무래도 현장에서 연사자와 함께 호흡하며 들을 때 적당한 몰입감 때문에 얻어가는 게 더 있는 것 같습니다. 아마 사람마다 다르겠죠? 🙂 저는 요즘 카펜터와 멀티 테넌트 쪽에 관심이 많아서 두 개 세션을 특히 재밌게 들었습니다. 유사한 주제로 세션이 많으니 관심이 있으시면 찾아보시길 바랍니다.
세션에 들어가는 방법은 두 가지입니다. 첫 번째는 미리 Reserved 하는 거고, 이렇게 예약하지 못했다면 walk-up 하는 겁니다. 예약했다고 하더라도 세션장에 10~20분 전에 도착하지 못하면 그 자리는 그대로 release 됩니다. 그리고 walk-up 하는 사람들에게 돌아가는 거죠. 얼핏 듣기로 walk-up을 위한 자리가 20% 정도 된다고 하니 꼭 듣고 싶은 세션이라면 미리 가서 줄을 서 있으면 됩니다. 최소 30분 전에는 줄을 서야 안전하게 들어갈 수 있을 겁니다. End of Line이 있다면 더 이상 줄을 서 있을 필요가 없습니다. 어차피 못 들어갈 테니까요.
라스베가스에서 이동은?
베뉴를 이동하는 거라면 셔틀이 제공됩니다. 굳이 시간을 확인하고 탈 필요 없이 (정확하진 않지만) 수시로 운행하기 때문에 어렵지 않게 행사장을 이동할 수 있습니다. 안내가 잘 되어 있어서 버스를 잘못 타거나 이상한 곳으로 빠질 염려는 없습니다. 마음 편히 안내를 따라가세요.
그 외에 개인적인 이동이나 셔틀이 싫어서 Rideshare를 타겠다면 모든 호텔에 따로 공간이 있으니 그쪽으로 가시면 됩니다. 다만, 당연히 사람이 몰리는 시간에 그곳은 지옥이 됩니다. 아래는 월요일 저녁 베네시안 풍경입니다. 우버나 리프트가 Rideshare 공간으로 들어오지를 못하는 지경입니다. 저도 대충 25분 정도 기다려서 겨우 탔네요.
이걸 기다려서 탈만한 가치가 있는지 확인을 해봐야겠죠?
체력이 중요합니다
걸음수만 보면 별로 이상해 보이지 않습니다. 그런데 놀러 간 게 아니다 보니까 아래 이미지에 있는 걸음에는 항상 백팩과 16인치 맥북이 함께 했습니다. 맥북을 호텔에 두는 것도 저는 괜히 불안하더라고요. 수요일 넘어가면서부터는 군생활이 추억될 정도로 힘들었습니다. 만약 다시 가게 된다면 사무용 전자기기는 아이패드 정도로 타협해서 가져갈 것 같네요. 😇 행사장에는 세션뿐만 아니라 쉬거나 즐길거리가 많으니 충분한 즐기도록 하세요. 지치면 듣고 싶은 세션을 들을 힘도 없게 됩니다.
re:Play
re:Play 행사는 리인벤트 행사가 성공적으로 진행됐다는 걸 축하하기 위해 열리는 파티입니다. 리인벤트는 월~금 행사인데요, re:Play는 목요일 저녁입니다. 금요일은 오전만 세션이 있어서 사실상 다들 라스베가스를 떠나거든요. re:Play 장소는 스트립에서 조금 떨어진 곳이라 버스 타고 20~30분 정도 가야 합니다.
re:Play 전체 뷰
리인벤트 행사에 참여하지 않았어도 re:Play 행사를 참여할 수 있는데 비용이 $300입니다. 그만한 가치가 있는가?라고 묻는다면 글쎄요. 일단 안에 맥주, 위스키를 포함해서 다양한 주류가 무료로 제공되고 즐길거리가 꽤 있습니다. 그래도 여전히 비싸다고 생각은 되지만요. 아무튼, 리인벤트 배지가 있으면 무료로 출입이 가능합니다. 이미 그 배지에 re:Play 비용이 포함된 거라서요.
안으로 들어와 보면 크게 세 개의 공간이 있습니다. 라이브 스테이지와 메인 스테이지는 파티 느낌을 그대로 즐길 수 있는 곳입니다. 라이브 연주라던가 클럽 같은 느낌으로요. 아레나는 다양한 게임을 할 수 있는 공간입니다.
https://www.production.club/aws-re-play-2022
여기가 메인 스테이지입니다. 역시 IT 업계분들은 국내외를 떠나서 샤이하게 바라만 보고 계십니다. 가끔 리듬을 타시는 분들도 계셨는데요, 밤이 깊어질수록 열기가 올라서 호응도가 높아집니다. 아래 영상은 너무 초반에 찍은 거라 사람도 없네요.
둠칫둠칫
라이브 스테이지도 분위기를 느껴보세요. 대략 이런 느낌이라고 보시면 됩니다.
스웨그
컨퍼런스에 나왔으면 스웨그를 챙기는 것도 하나의 재미 요소일 겁니다. 이번에 엑스포를 돌아다니며 받은 것들을 한 곳에 모아봤습니다. 입장할 때 받은 후드집업과 텀블러는 찍지 못했네요. 당분간 잠옷 걱정은 없겠습니다. 하하..
Wrap up
지금까지 리인벤트 행사 전반에 대해 살펴봤습니다. 저는 2017년부터 AWS를 사용해 왔는데요. 리인벤트는 처음 와봤습니다. 그래서 감회가 새롭네요. 자, 제게 리인벤트는 어땠을까요? 세션은 어차피 유튜브로 금방 공개되기 때문에 리인벤트 현지에서 세션을 듣는 건 어쩌면 고작 몇 시간(혹은 며칠) 먼저 듣는 겁니다. 그럼에도 현장에서만 느낄 수 있는 몇 가지가 있습니다. 우선 발표자와 함께 호흡하고 있다는 생각, 공간을 가득 채우고 있는 사람들의 뜨거운 열기, Q&A 까지. 이런 것들을 종합하면 집에서 편히 유튜브로 시청하는 것보다 적어도 몇 배는 몰입해서 세션을 들을 수 있게 됩니다. 한국에서도 굳이 (나중에 유튜브 무료로 풀리는) 유료 컨퍼런스를 경쟁하면서 신청해서 듣는 이유가 있는 것이지요.
그리고 엑스포를 통해 다양한 SaaS 업체를 한자리에서 구경하는 건 어쩌면 큰 행운일지도 모릅니다. 또, IT 컨퍼런스 중에 아마도 가장 큰 규모의 컨퍼런스에 참석해서 현장감을 느낄 수 있었던 게 제게는 정말 굉장한 경험이었습니다. AWS 배지를 차고 있는 사람들이 거리에 넘쳐납니다. 외국에 덩그러니 있으면 아무래도 불안한 느낌도 있을 텐데 뭔가 배지가 주는 든든함이 느껴집니다(웃음).
누군가 리인벤트를 추천하느냐고 묻는다면 답변은 “yes!!” 다만, 마음을 열고 리인벤트 자체를 충분히 즐길 준비를 하셔야 합니다. 그렇지 않으면 그냥 관광하러 간 것과 다르지 않을 테니까요. 마음을 열고 사람들에게 대화를 시도해 보세요. 임팩트 있는 경험이 될 겁니다. 🙂
이외에도 재밌는 에피소드가 많았습니다. 에피소드가 궁금하시거나 매드업에서 AWS를 어떻게 활용하고 있는지 궁금하신 분, 또는 어떤 제품을 개발하고 있는지 관심이 생기셨다면 가벼운 커피챗부터 시작해 보세요. 채용문은 항상 열려있습니다. 아래 페이지를 통해 채용 직군을 확인해 보세요. 혹은 저와 연결되고 싶으신 분은 링크드인에서 저를 찾아주세요! 🤞
]]>CaleyMSW - 더 나이스한 목킹을 위한 고민2023-06-11T00:00:00+00:002023-06-11T00:00:00+00:00https://tech.madup.com/mock-service-worker🤔 고민
웹사이트를 개발하다 보면 백엔드와 프론트 간의 개발 속도 차이로 인한 문제와, API 응답 데이터에 의존하는 로직에 대한 테스트 코드 작성이 어려운 문제 등이 자주 발생합니다. 이러한 문제들은 현재 진행 중인 개발에 집중하기 어렵게 만들어줄 뿐 아니라 중복 코드와 같은 불필요한 작업을 초래합니다.
따라서 이번 글에서는 각각의 문제들이 발생하는 원인과 해결책에 대해 자세히 살펴보겠습니다. 함께 읽어보세요!
< 정리 >
백엔드와 프론트 간의 개발속도 차이로 인한 문제
백엔드와 프론트가 동시에 개발하면 발생되는 문제점
API 응답 데이터에 의존을 갖는 로직에 대한 테스트코드 작성
API를 호출하는 Custom hooks 혹은 Component 코드에 대한 테스트 코드 작성
1️⃣ 첫번째 고민
( 백엔드와 프론트 간의 개발속도 차이로 인한 문제 )
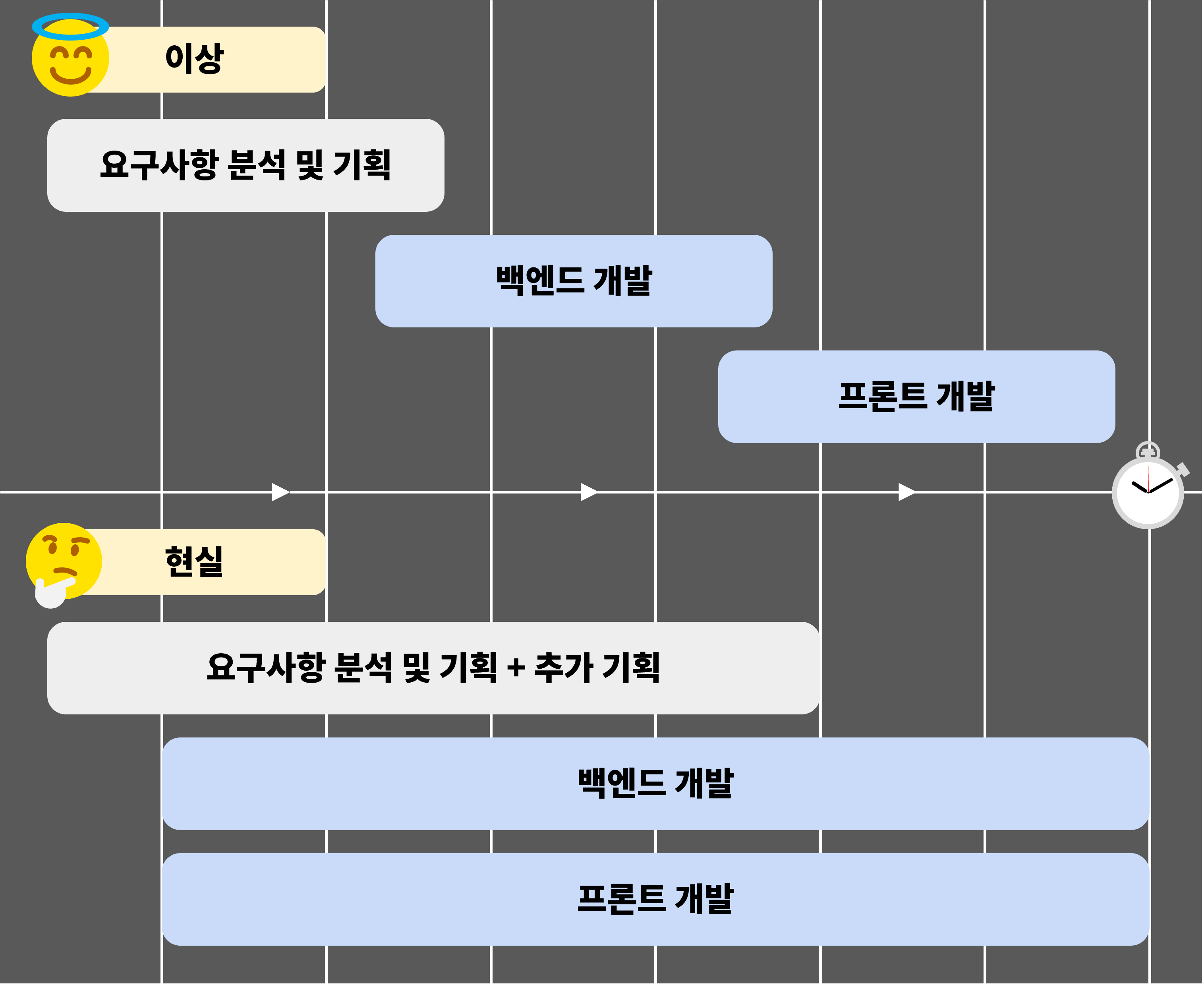
프로적트 개발 계획의 이상과 현실
회사에서는 일반적으로 기획 -> 백엔드 개발 -> 프론트 개발 의 순서로 제품을 개발합니다. 하지만 실제로는 기획 -> 백엔드, 프론트엔드 개발 처럼 백엔드, 프론트엔드 개발이 동시에 진행되는 경우가 많습니다.
이러한 상황에서 발생하는 문제는, 프론트엔드에서 백엔드로부터 제공되는 API 응답 데이터를 기다리면서 화면을 구성해야 한다는 것입니다. 이로 인해 프론트엔드는 API가 완성될 때까지 다음 작업으로 넘어갈 수 없으며, 백엔드는 더 빠른 API 개발에 대한 압박을 받게 됩니다.
다행히도, 개발 커뮤니티에서는 이러한 문제를 해결하기 위해 다양한 방법들을 시도하고 있습니다.
백엔드에서 목업데이터 전달
예를 들어 백엔드에서는 비즈니스 로직 구현 전에 Mockup 데이터를 반환하는 API를 먼저 제공하거나, Postman과 같은 외부 서비스를 이용하여 Mockup 용 API 서버를 제공하는 방법을 사용합니다.
/* MockupData 선언 */constmockupData=[{name:"홍길동",age:28},{name:"고길동",age:48},...]/* Api 호출 대신에 MockupData를 사용 */constresponse=mockupData// fetch(...)
또한, 프론트엔드에서는 Mockup API를 요청하는 대신에 자체적으로 Mockup 데이터를 만들어 사용하는 방법을 사용하기도 합니다.
이와 관련하여 검색을 해보면 다양한 API Mockup 처리 방법들이 나오는 것을 확인할 수 있습니다.
두번째 고민은 API호출 로직이 포함된 코드에 대하여 검증 로직이 필요할때 발생하게 됩니다.
API 를 호출 과 동시에 해당 응답데이터를 가공하는 함수를 작성하거나 혹은 UI컴포넌트 의 결과가 의도한 대로 잘 나오는지 확인해야할 때
프론트엔드에서는 주로 백엔드에서 받아온 데이터로 UI를 그리는 행위가 빈번하기 때문에, 응답 데이터에 의존성을 갖는 컴포넌트 및 함수들이 많습니다.
중요한 로직은 순수 함수 형태로 분리해 의존성을 제거하는 것이 좋지만, 서비스가 복잡해지면 API 호출 관련 의존성을 분리하는 것이 어려워집니다. 따라서, API 호출 관련 의존성이 있는 코드를 테스트할 때는 Mockup 처리를 해야하는 불편함이 생깁니다.
간단한 컴포넌트의 경우 테스트 라이브러리에서 지원하는 Mockup 처리 관련 메서드를 이용하여 충분히 해결이 가능하지만, 프로덕트가 고도화 됨에 따라 비즈니스 로직과 UI 컴포넌트들이 더욱 복잡해지면 Mockup 처리해야 할 대상이 많아지기 때문에 처리가 어려워질 수 있습니다.
/*
모든 Users 정보를 가져오는 부모 컴포넌트
특정 유저정보를 찾아 자식 컴포넌트에게 전달하는 역할
*/constParent=()=>{consttargetId=1const[users,setUsers]=useState([])consttargetUser=users.filter(({id})=>id===targetId)useEffect(()=>{(async()=>{constusers=awaitfetch('http://dev.api.me/users')setUsers(users)})()},[])return<Childuser={targetUser}/>}/*
특정 유저가 남긴 모든 댓글정보를 가져오는 자식 컴포넌트
특정 유저가 남긴 댓글을 모두 보여주는 역할
*/constChild=({user})=>{const[userComments,setUserComments]=useState([])useEffect(()=>{(async()=>{constcomments=awaitfetch(`http://dev.api.me/comments/user/${user.id}`)setUserComments(comments)})()},[])return(<ul>{userComments.map(({content})=>(<li>{content}</li>))}</ul>)}
⚠ 위의 예제코드는 자식 컴포넌트로 내려갈수록 호출되는 API 또한 늘어나는 경우를 이해시켜 드리기위해 제공되었습니다.
위의 코드는 부모 컴포넌트에서 API를 호출하여 자식 컴포넌트에게 데이터를 전달하고, 자식 컴포넌트에서는 해당 데이터를 가공하여 또 다른 API를 호출하는 상황을 보여줍니다. 이 경우 JEST를 사용하여 Mockup 처리를 하려면, 모든 의존하는 API 호출 함수를 상위 컴포넌트부터 하위 컴포넌트까지 파악하여 각각 별도의 Mockup 처리를 해주어야 합니다.
사실 테스트 코드 작성만 해도 상당히 신경써야 할일이 많은 일인데, Mockup 처리 작업으로 인해 온전히 테스트 코드에만 집중하기 힘든 상황에 놓여지게 된 상황인 것이죠… 😅
뿐만 아니라 팀내 여러 프론트엔드 개발자들이 각자 테스트 코드를 작성할 때, 동일한 API에 대해 각자 Mockup 처리하는 중복코드가 발생할 수 있으므로 이러한 중복을 최소화하기 위한 방법 또한 고민해야 합니다.
💡 해결
저희 팀은 두 가지 문제를 해결하기 위해 Mock Service Worker(이하 MSW) 를 도입했습니다. 다양한 대안들이 있음에도 MSW를 선택한 이유는, 앞서 언급한 두 가지 문제를 MSW를 사용하면 모두 해결할 수 있기 때문입니다.
▶️ MSW 란?
이야기에 들어가기 앞서 MSW란 무엇인지 간단하게 살펴보겠습니다.
MSW는 Mock Service Worker 의 약자로 이름에서 아실 수 있듯이 Service Worker 라는 기술을 이용해서 Mockup 작업을 돕는 라이브러리 입니다.
여기서 서비스 워커(Service Worker) 란, 최신 브라우저에서 지원되고 있는 기술로 웹 응용 프로그램, 브라우저, 그리고 (사용 가능한 경우) 네트워크 사이의 프록시 서버 역할을 합니다.
서비스 워커를 이용하면 네트워크 요청이나 응답을 가로채서 조작하는것이 가능한데요, MSW는 이러한 특성을 이용해서 실제 API 요청이 발생했을시 미리 준비해둔 목업 데이터로 대신 응답을 보내는 방식을 사용하고 있습니다.
▶️ 기존 Mockup 처리방식
기존에는 네트워크 요청을 가로채기 위해 각각의 개발자가 네이티브 http, https, XMLHttpRequest 모듈을 다른 함수로 대체하여 Mockup 처리를 하거나, PostMan Mockup Server와 같은 목업서버를 직접 구축하여 테스트할 때 해당 서버에서 응답데이터를 받아 활용하는 방식을 사용했습니다.
▶️ MSW 채택이유
MSW는 기존 방식과는 다르게 네트워크 요청이 발생하면 데이터만 교체하는 방식을 사용하여, 복잡한 처리 없이 서비스워커를 이용해 보다 간단하게 처리할 수 있습니다. 또한, MSW에서는 별도의 프로덕트 내부로직의 수정 없이 브라우저 환경과 테스트 환경(Node)에서 각기 다른 모킹 상태를 만들어 줄 수 있어, 앞서 언급한 두 가지 문제 상황을 해결할 수 있습니다.
또한, API를 만드는 것과 유사하게 개발할 수 있어 사용성 면에서도 큰 비용 없이 활용이 가능합니다. 이러한 이유로 저희 팀은 MSW를 채택하여 사용하게 되었습니다.
[ 채택이유 정리 ]
Mockup 처리가 간단하다
브라우저 및 Node 각 환경별로 목업데이터를 활용할 수 있다.
학습에 큰 어려움이 없다.
📄 MSW 간단문서
▶️ MSW 설치
npm install msw --save-dev# or
yarn add msw --dev
▶️ 서비스 워커 생성
npx msw init public/ --save
Browser 환경에서 API 요청을 가로채기 위해 반드시 필요한 파일
▶️ Handler (aka. Router) 생성
특정 API 경로로 요청이 시작되었을때 우리가 의도한 Mockup Data가 사용되게 하기 위해서는 Mockup 처리를 원하는 API 경로와 이에 따른 Mockup Data를 맵핑하는 과정이 필요합니다.
바로 해당 작업을 처리하는 곳이 Handler 인데요, 해당 코드를 살펴보면 Express 에서 Router를 작성하는 형태와 비슷하게 생긴 것을 확인할 수 있습니다.
코드는 아래와 같습니다.
// src/mocks/handlers.tsimport{rest}from'msw'exportconsthandlers=[/* user id를 이용해서 User 정보를 가져오는 API */rest.get('https://dev.api.me/user/:userId',(req,res,ctx)=>{const{userId}=req.paramsreturnres(ctx.json({id:userId,firstName:'John',age:38,}),)}),]
▶️ Resolver (aka. Services) 생성
Resolver는 위의 Handler에서(req, res, ctx) => {...}형태의 코드를 일컬으며 백엔드에서 API 개발시 작성되는 서비스로직 과 유사합니다. 각 API경로로 들어왔을때 보내진 정보를 갖고 데이터를 가공하여 반환하는 역할을 합니다.
코드는 아래와 같이 작성하며, express 와 동일하게 req, res, ctx 객체 활용이 가능하며, 이곳에서는 API호출시 같이 기입된 parameter, body, header 값에 대한 활용이 가능합니다. 해당 값들은 req객체에 들어가 있으며 자세한 사용법은 아래 코드 혹은 공식문서를 참고 바랍니다.
API의 (req, res, ctx) => {...} 을 resolver.ts 로 분리
// src/mocks/handlers.tsimport{rest}from'msw'import{mockUser}from'./resolvers'exportconsthandlers=[/* user id를 이용해서 User 정보를 가져오는 API */rest.get('https://dev.api.me/user/:userId',mockUser),]
Mock Service Worker(MSW)를 도입하면서 가장 좋았던 경험 중 하나는 초기에 빠른 개발이 가능했다는 것입니다. 이를 통해 개발 초기 스프린트에서 빠르게 실제 서비스가 동작하는 것처럼 구현이 가능했고, 결과물을 바탕으로 미리 디자이너와 기획자의 피드백을 받을 수 있었습니다.
프론트엔드 개발의 가장 큰 고민 중 하나는, 개발자와 디자이너 간의 소통입니다. 종종 개발자와 디자이너가 서로 다른 생각으로 결과물을 만들어내기도 하죠. 이러한 이유 때문에 디자이너 검수 및 피드백을 반영하는 데에도 상당한 시간을 투자해야 하는 경우가 많습니다.
저의경우 이러한 상황에서 MSW도입이 큰 도움이 되었습니다. MSW를 이용하면 API가 나오기 전에 미리 디자인 검수를 받고, 문제가 발생한 부분을 수정할 시간을 가질 수 있습니다. 이렇게 실제 API에 의존하지 않고 화면을 구현하여 빠른 피드백을 받고 이를 토대로 빠른 수정을 통해 디자이너와 개발자 간 생각 차이를 좁혀나갈 수 있었습니다.
▶️ 보다 높아진 테스트 코드에 대한 집중력
프론트엔드 개발 과정에서 가장 큰 문제 중 하나는, 다양한 API 호출이 이뤄지는 복잡한 화면을 테스트하는 것입니다. 이러한 경우에는 UI 테스트를 위해 해당 화면과 관련된 모든 API를 목업처리해야 하는데, 이는 상당히 번거롭고 시간이 많이 소요됩니다.
또한, 목업데이터를 만드는 업무 자체도 중복으로 이뤄지는 경우가 있습니다. 개발자가 복잡한 데이터 구조를 이해하고, 각 API 목업데이터를 만들어야 하는데, 같은 로직을 구현하는 또 다른 개발자가 중복으로 목업데이터를 만들어내는 경우도 많았습니다.
하지만, MSW(Mock Service Worker)를 도입하면 API 자체에 대한 목업처리가 가능해지기 때문에, 이를 통해 팀원 모두가 공통된 목업 데이터를 사용할 수 있게 되었습니다. 또한, 목업 데이터 개발과 테스트 개발을 분리하여 개발할 수 있게 되었고, 각 테스트 코드마다 목업 데이터를 만들며 쏟아야 했던 시간들을 테스트 코드 자체에 더 쏟을 수 있는 환경이 조성되었습니다.
물론 MSW 도입이 목업데이터를 만드는 업무 자체를 없애주진 않았지만, 팀 내 모든 프론트엔드 개발자들이 매 API가 추가될 때마다 목업데이터를 하나씩 서로 추가해 주면서 각 개발자가 부담해야 하는 목업 데이터 개발양이 크게 줄어들 수 있었습니다. 따라서 MSW의 도입으로 더욱 효율적인 개발 환경이 조성되었다는 것을 알 수 있습니다.
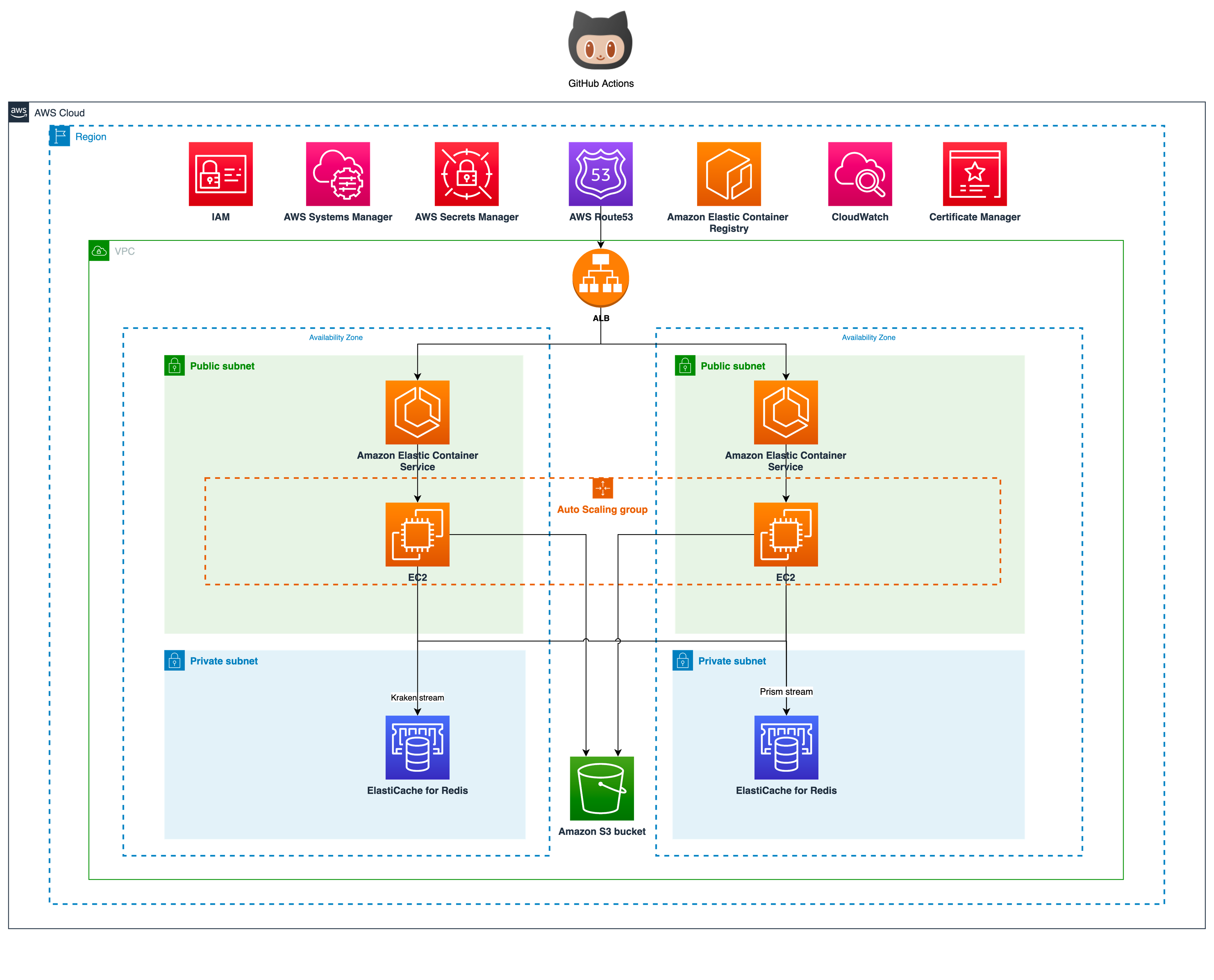
]]>jake매드업의 DMP - 프리즘(prism)을 소개합니다2023-03-19T00:00:00+00:002023-03-19T00:00:00+00:00https://tech.madup.com/prism-intro안녕하세요. Adtech(Advertising technology) 스타트업 매드업 에서 데이터 엔지니어로 일하고 있는 칼리 입니다. 이번 글은 매드업의 Data Management Platform(DMP) - Prism을 소개하는 글입니다. 프리즘을 구축, 운영하며 어떤 고민을 했는지 그리고 앞으로의 방향을 확인해봅니다. 목차는 다음과 같습니다.
매드업에 합류해서 동료들과 함께 구축한 Data Management Platform(DMP)을 Prism(프리즘)이라는 이름으로 사내에 공개(2021-07-01)했습니다. 프리즘은 데이터를 수집/가공/적재/공급하는 전체 파이프라인을 품고 있습니다.
이런 프리즘을 생각하셨다면.... 삐빅 정상입니다 @unsplash
자, 그러면 매드업의 프리즘은 어떤 데이터를 수집할까요? 광고 데이터 입니다. 매드업은 광고주의 광고를 대행하며 더 좋은 성과 지표를 만들기 위해 데이터를 다양한 각도로 분석해서 높은 효율을 낼 수 있도록 고민합니다. ( 더 좋은 성과는 노출, 클릭, 비용 같은 지표가 될 수도 있고 고객에 따라 기타 다른 무언가가 될 수도 있습니다 )
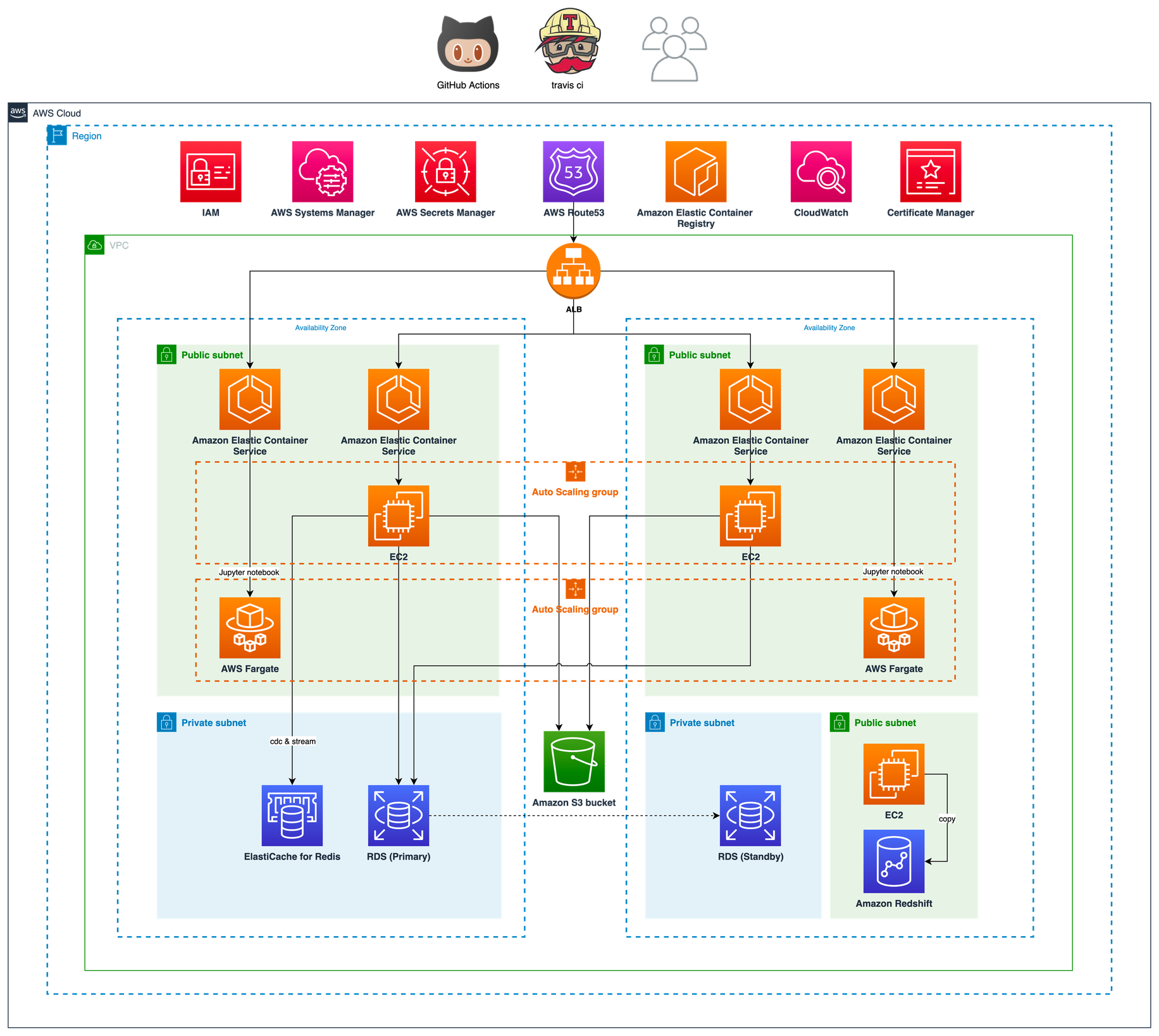
온라인에 공개 가능한 범위의 프리즘 기본 아키텍처는 다음과 같습니다. Python으로 작성된 데이터 수집기(collector)는 매드업 전체 광고주의 매체(Google, Facebook, Naver, Kakao Moment 등) 데이터와 트래커(Appsflyer, Google Analytics 등) 데이터를 주기적으로 수집해서 AWS S3에 적재합니다. 광고주별로 한번에 수집되는 데이터의 크기는 적게는 MiB 단위부터 GiB까지 스펙트럼이 굉장히 넓습니다. 이렇게 대량의 데이터를 수집하기 위해 광고주의 수에 따라 수집기는 수백~때로는 수천개까지 증축 운영 될 수 있는 아키텍처로 구축되어 있습니다. 여기서는 AWS의 대표적인 컨테이너 오케스트레이션 서비스인 Elastic Container Service(ECS)가 사용되었습니다.
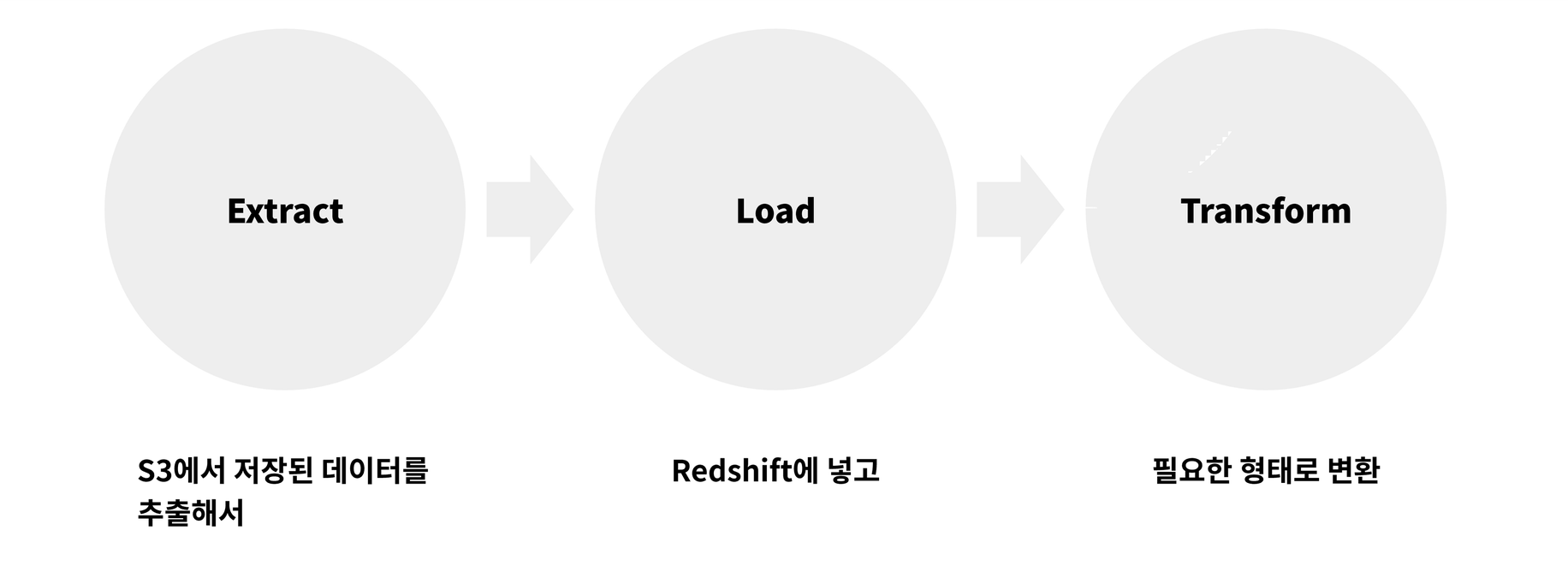
이렇게 수집된 데이터는 ELT(Extract, Load, Transform)를 통해 가공됩니다. S3에 저장되어 있는 Raw 데이터(매체에서 수집한 원본)를 추출해서 Data Warehouse인 Redshift에 Load(Redshift 입장에서는 저장) 하는거죠. 필요한 경우 Load하기 전에 데이터를 사용하기 좋은 형태로 변환(Transform)하기도 합니다. Load된 이후에 쿼리를 통해 새로운 테이블로 다시 내보내기도 하고요.
이런 과정을 IT 용어로는 ELT(Extract, Load, Transform), ETL(Extract, Transform, Load)이라고 부릅니다. 그리고 이런 처리 과정은 Workflow 도구를 사용하면 데이터가 아주 자연스럽게 흘러갈 수 있도록 운영이 가능한데요. 매드업은 Workflow의 대표적인 오픈소스, Apache Airflow 를 사용하고 있습니다.
이쯤에서 프리즘의 전체 아키텍처를 도식화해서 그려놓은 그림을 살펴보시죠.
초기 아키텍처
혹시 “프리즘”에서 스노든의 Prism 이 떠오르셨더라도 정상입니다. 매드업의 모든 데이터가 조회되길 바라는 마음으로 프로덕트 이름을 정했거든요 🙂
프리즘으로 광고 데이터 수집, 적재
광고 데이터에는 아주 중요한 특징이 있는데요, 광고 매체에서 내려주는 데이터가 호출(요청)마다 신선도가 좋아진다는 점입니다. 예를 들어 Google Ads에서 제공하는 2023-03-16(최근 날짜라고 가정) 데이터를 오늘 내려받았을 때와 내일 내려받았을 때 결과가 다를 수 있습니다(아니, 다릅니다. 심지어 한 달 후의 결과도 다릅니다). 이건 광고주가 전환 추적 기간 설정을 했기 때문인데요, 구글뿐만 아니라 다른 대부분의 매체도 유사합니다. 페이스북의 경우는 아래 문구를 확인해주세요. 한 달 가까운 시간 동안 데이터는 계속 업데이트될 겁니다.
Facebook API
이런 특징 때문에 광고 데이터를 Data Warehouse(DW)에 제대로 구축하려면 많은 어려움이 따릅니다. 자체 기술력이 부족하다면 데이터의 “정확성”을 포기하는 것도 방법입니다. 그렇게 되면 아키텍처의 많은 부분들이 간소화되니까요. 이 부분은 컴퓨팅 리소스 절감으로 시작돼서 인프라 비용까지 이어집니다.
보통 DW 구축은 데이터를 쏟아 붓기만 하면 됩니다. 하지만 완벽을 추구하는 조직(회사)라면 광고 데이터를 DW로 제공하기 위해서 필연적으로 columnar database 에 UPSERT 같은 개념(조건이 충족되는 데이터가 존재하면 UPDATE, 없으면 INSERT)이 필요합니다. 하지만 하루 최소 수백 GiB 데이터가 핸들링되어야 하는 DW에 UPSERT라뇨. 대게 이런 경우는 기존 데이터를 전부 날려버리고 Data Lake(DL)로부터 새롭게 적재(TRUNCATE©)하는 방식을 택합니다. 그게 (보통은) 훨씬 빠르고, 비용도 저렴하고, 효율적이니까요 (여기서 비용은 금전적인 부분을 이야기하는게 아니고 아키텍처 유지 비용, 혹은 자원 사용량 등을 나타냅니다). 왜냐하면 데이터 적재 시에 UPSERT를 하려면 비즈니스 로직이 들어가야 합니다. 트랜잭션과 함께 복잡한 시나리오를 고려해야 하고 그 과정에서 데이터 정합성이 깨지기도 합니다. 데이터웨어하우스 입장에서 이건 심각한 문제입니다.
단순히 데이터 분석만을 위한 용도라면 Data Lake(aws S3)에 직접 쿼리(Athena, Spectrum)하는 것도 꽤 좋은 선택입니다. 하지만 우리는 DW를 서비스 레벨로 끌어올리려는 목표를 갖고 있습니다. 그 목표를 이루기 위해 UPSERT의 효과를 얻을 수 있는 여러 가지 처리를 도입했습니다. 부분적으로는 Data Mart(DM)를 운영하고요. - DW, DL 구축에 정답은 없습니다. 서비스 / 분석 / 리포트 영역에서 필요한 데이터를 효율적이고 쉽고 빠르게 제공할 수 있으면 그걸로 된다고 생각합니다. 한편 프리즘(Prism)은 앞서 설명한 광고 데이터의 특성을 극복하고 수백, 수천 종류의 데이터를 병렬로 빠짐없이 수집하고 적절한 처리를 통해 Redshift에 적재합니다(아, DW 선택이 논쟁의 여지는 있지만 사실 저는 BigQuery를 더 사랑해요). 이 과정에서 수백 개의 컨테이너가 오케스트레이션 됩니다.
@unsplash
그 결과 시간당 수십만 개의 파일을 처리해서 Redshift에 적재하게 됐습니다. 용량으로 따지면 수십 GiB에 해당하는 양입니다!
프리즘을 사용하는 모든 서비스에 Near real-time에 가까운 살아있는 데이터를 제공하는 게 우리가 추구하는 프리즘의 최종 모습입니다. 고객과 데이터 사이언티스트에게 데이터는 신선하고 정확할수록 좋습니다. 아무튼, 프리즘 V1은 기반 시스템을 대부분 갖췄지만 본격적으로 데이터가 “콸콸” 흐르기 위해서는 추가적으로 개선해야 하는 포인트가 몇 군데 남아있었습니다. 80% 완성은 공개된 오픈소스와 클라우드 컴퓨팅만 적절히 사용해도 엔지니어링 역량만 어느 정도 갖추고 있다면 충분히 가능합니다. 하지만 그 이상의 디테일을 해내기 위해서는 회사와 엔지니어의 풍부한 경험과 기술력이 뒷받침되어야 하죠. 악마는 디테일에 있으니까요. 앞으로도 재미있는 일이 많이 기다리고 있습니다!
데이터 소비
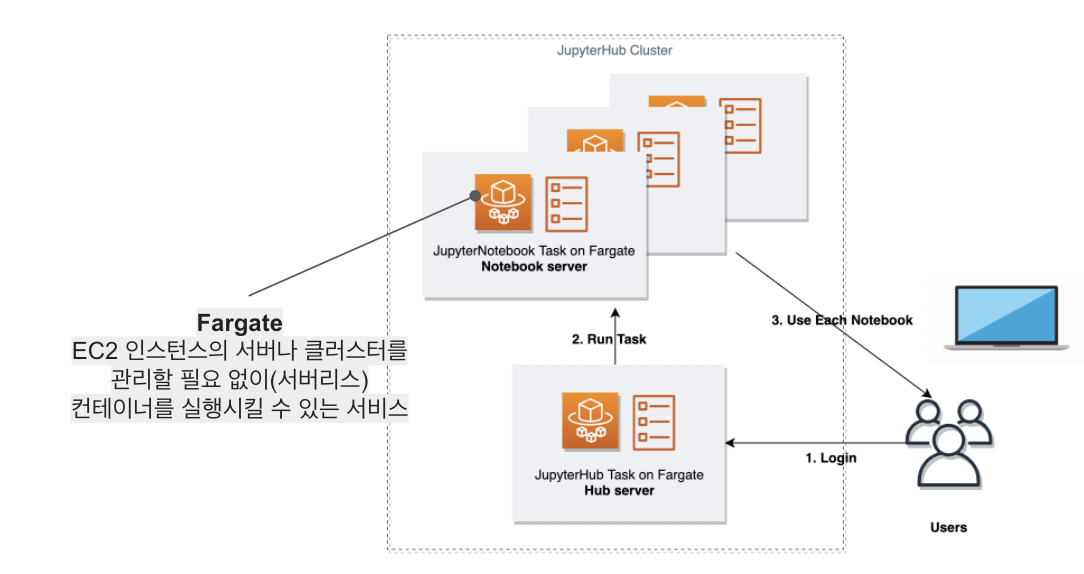
프리즘은 회사 구성원 누구나 유의미한 리포트 자료를 뽑을 수 있도록 데이터를 제공합니다. 프리즘에 있는 데이터는 container orchestration 도구인 AWS Elastic Container Service(AWS ECS) 위에서 동작하는 JupyterHub를 통해 Google Workspace 개인 계정으로 접근할 수 있습니다.
Jupyter Notebook은 Fargate로 실행되기 때문에 데이터 분석을 원하는 내부 사용자가 순간적으로 몰리더라도 리소스 점유와 같은 문제는 발생하지 않습니다. 한편 클라우드 리소스는 모두 Infrastructure as Code(IaC)로 관리되기 때문에 개발 / 스테이징 / 운영 환경을 필요에 따라 빠르게 구축할 수 있습니다. JupyterHub를 ECS에서 서비스하는 건 아마도 매드업이 국내 최초 같습니다. 뭐 물론 아키텍처가 공개되지 않은 사례도 있긴 하겠죠? 이와 관련된 이야기는 다른 글을 통해 공유할 기회가 있을 겁니다.
Wendy's drawing
자, 여기까지의 이야기는 AWS 한국사용자모임에서 광고 데이터 수집을 위한 인프라 구축이란 내용 으로 발표했습니다. 혹시 관심 있으신 분은 영상을 통해 확인하시길 바랍니다. 아래는 프리즘 V1의 한계와 프리즘 V2를 소개합니다. 기술적인 모든 내용을 담기에는 지면이 부족하니 다양한 채널을 통해 연락 주신다면 공개 가능한 부분은 이야기드릴 수 있도록 하겠습니다 🙂
프리즘 V1의 성장 한계
약 1년 넘게 운영한 프리즘은 한계에 다다르게 됩니다. 위에 아키텍처에는 잘 드러나지 않지만 프리즘은 Event Driven Architecture(EDA) 로 구축되어 있습니다. 이벤트 처리는 Redis Stream 으로 사용했습니다. 그리고 Airflow는 EC2 환경에서 동작시켰습니다. 이런 전체적인 아키텍처도 나쁘지 않지만 우리가 앞으로 더 나아가는데 몇 가지 발목 잡히는 부분이 있었습니다. 하나씩 살펴보겠습니다.
프리즘은 아직 한참 더 성장해야 하는데 속도 제한에 걸린 느낌이랄까.. @unsplash
첫 번째는 코드입니다. 대부분의 코드가 동기 방식(synchronous)으로 구현했기 때문에 효율적이지 못한 부분이 있었습니다. 동기방식은 사람이 이해하기 쉽기 때문에 추가 개발을 포함한 유지보수가 안정적이지만 광고주 수에 따라 동시에 데이터를 처리하기 위해 무조건 인스턴스를 늘려야(scale-out)만 하는 아쉬운 부분이 있습니다. 인스턴스를 늘린다는 건 결국 비용과 직결되는 문제인데요. 제대로 된 개발팀을 보유하고 있다면 빠르게 성장하는 스타트업이라도 비용 문제를 같이 해결하면서 전진하는 게 맞다고 생각합니다.
두 번째로 Redis Stream은 개발자에게 약간의 허들이 됩니다. Stream 키의 태생을 이해하고 사용법을 익혀야 하는 거죠.
과거의 내가 그린 건데 뭘 표현하는 건지 모르겠다(…) 그만큼 이해하기 난해하다는 의미
개발자라면 무릇 당연히 그래야 하는 거 아니야?라고 반문하는 분이 계실 수도 있지만 Redis Stream은 그렇게 인기 있는 기술스택이 아닙니다. 백번 양보해서 개발자가 그 기술을 통달한다고 쳐도 큰 경험으로 남기는 어렵다는 겁니다. 더욱이 Redis를 Cluster로 운영하지 않는다면 Stream에 저장된 메시지를 유실할 가능성이 높습니다. 물론 흔한 일은 아니지만요.
세 번째는 ECS입니다. 사실 이미 ECS를 이용해 수십 개의 인스턴스 위에서 수백 개의 tasks(편의상 container라고 생각하셔도 됩니다)를 안정적으로 처리하고 있습니다. 심지어 혹자는 ECS가 EKS 대비 경량화 돼서 비즈니스를 빠르게 빌드업할 수 있다고 이야기할 만큼 나름의 장점도 있는 서비스입니다. 그런데 왜 ECS에서 한계를 느끼냐구요? 우선 조직의 EKS 혹은 Kubernetes 운영 역량에 따라 충분히 ECS에 견줄 만큼 빠르고 간편한 배포와 더불어 안정성 면의 이점도 있을 것이라 판단했습니다. 또한 ECS의 배포 단위 중 하나인 “Service” 단에서는 리소스 제약을 설정할 수 없다는 단점도 있었습니다. Task와 Container에만 가능하죠. 이에 반해 AWS에서 선택 가능한 다른 컨테이너 오케스트레이션 도구인 EKS는 Pod 뿐만 아니라 Namespace 단위로 리소스를 제한할 수 있습니다.
네 번째는 Airflow on EC2입니다. 개인적으로 Airflow와 관련해서 기술적인 대화를 할 기회가 있다면 “Airflow는 충분히 익어서 안정적인 워크플로예요”라고 이야기합니다. 실제로 1년 넘게 EC2로 운영하면서 문제가 된 적은 몇 번 없었습니다. 그 몇 번도 Airflow 자체 문제는 아니었고 disk full 등의 이슈였는데 그건 운영을 잘못해서 그랬던 거죠. 아무튼, EC2에서도 문제는 없었지만 앞으로도 그런다는 보장은 없습니다. 업무시간에 인스턴스에 문제가 생긴다면 사람이 빠르게 대응해서 downtime을 최소화할 수 있을 겁니다. 하지만 새벽이라면? 장애 알람을 받아도 빠른 대응은 어려울 겁니다.
다섯 번째는 Data Warehouse(DW)입니다. 처음 프리즘을 구축할 때는 마케팅 도메인과 DW에 대한 이해가 부족했기 때문에 모든 데이터를 DW에 올리기 위해 무던히 노력했습니다. 사실상 Data Lake(DL)과 DW에 구분이 없을 정도였으니까요. 더욱이 PoC 할 때 좋은 성능을 보여줬던 DC2 노드는 운영 환경에서 꽤나 안타까운 결과를 냈습니다. DB가 안 터지면 다행이었으니까요. 우리가 쌓는(쌓을) 데이터 양을 제가 얕잡아 본건지도 모르겠습니다(웃음)
이외에도 몇 가지 더 이야기할 수 있지만 새로운 프리즘(V2)을 만들어야 하는 가장 큰 이유는 회사에서 준비 중인 새로운 프로덕트의 요구사항을 충족하기 위해서입니다. 중요한 것은 현행 유지 차원이라면 프리즘 V1도 충분히 오랫동안 버틸 수 있을 겁니다. 혹시 시스템에 일시적인 문제가 생기더라도 Self-Healing 될 수 있도록 아키텍처를 설계했거든요. 개발자가 장기 휴가를 떠나도 시스템은 튼튼하게 유지/운영됩니다. 이건 V2에도 여전히 유효할 테니 더 이상의 설명은 생략하고 다음 버전으로 넘어갑니다.
프리즘 V2를 세상 밖으로
위에서 언급한 다섯 가지 이유를 해결하기 위해 고민한 결과를 공유합니다.
첫 번째로 코드는 모두 비동기 방식(asynchronous)으로 수정했습니다. 광고 매체/트래커로부터 데이터를 수집하는 것부터 수집된 데이터를 처리하는 과정, 그리고 S3에 업로드까지 모두 비동기로 구현되었습니다. 그로 인해 인프라에 CPU를 더욱 효율적으로 활용할 수 있게 됐습니다. 이 내용은 PYTHON ASYNCIO를 활용한 효율적인 광고 데이터 수집 에서 자세히 살펴보실 수 있습니다.
두 번째로 Redis Stream 대신 AWS SQS와 Managed Kafka인 MSK를 선택했습니다. 메시지를 넣고 꺼내는 건 클래스로 추상화시켜 두고 개발자는 비즈니스 코드에만 집중할 수 있습니다. 매니지드 서비스인 만큼 안정성이 보장됩니다. 또한 개발과정에서 개발자는 SQS와 MSK를 심도 있게 사용할 수밖에 없는데 이것들은 좋은 경험이 됩니다. SQS는 Visibility Timeout과 Receipt Handle을 제대로 다루는 게 핵심이 될 것이며 MSK는 굳이 설명이 필요 없을 정도로 많은 곳에서 널리 사용되고 있는 서비스이니 당연히 경력에도 도움이 됩니다.
중요한 건 널리 사용하는 기술을 많이 사용해 보고 시야를 넓히는 것
세 번째로 ECS 대신 EKS를 선택했습니다. ECS와 EKS를 비교하는 자료는 많지만 그중에 프리즘이 EKS를 선택해야하는 이유에 해당하는 건 없습니다. EKS로 전환했을 때 가장 큰 장점은 kubectl이라는 강력한 도구를 통해 터미널에서 인프라 환경에 기민하게 대응할 수 있게 된다는 겁니다. 또한 EKS는 Kubernetes 기반으로 온라인에 수많은 best practice가 존재하기 때문에 많은 것을 보고 배우며 적용할 수 있게 됩니다.
네 번째로 EC2에서 운영하던 Airflow를 Amazon Managed Workflows for Apache Airflow(MWAA) 환경으로 옮겼습니다. 매니지드가 주는 안정감을 얻기 위해서입니다. 물론 매니지드 서비스로 넘어가면서 포기하는 것도 있습니다. EC2 환경에서 실행되는 DAG의 Task는 병목 없이 굉장히 빠르게 스케줄 되지만 MWAA 환경의 경우 그렇지 못합니다. 즉, DAG이 많아지고 스케줄 주기가 짧다면 문제가 될 여지가 있습니다. 이건 MWAA가 아니라 Airflow on Kubernetes도 마찬가지입니다. 온라인에는 Airflow를 Kubernetes나 다른 매니지드 서비스로 동작시킨 다양한 성공 사례가 있습니다. 하지만 은탄환1은 없다는 걸 기억하시고 비즈니스 성격에 맞는지 확인하고 적용하시길 바랍니다.
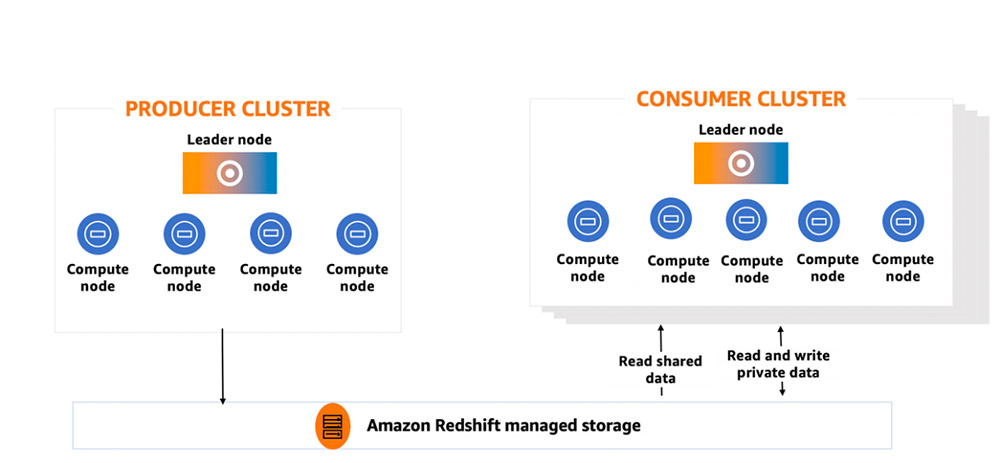
마지막으로 다섯 번째는 여전히 Redshift를 사용하지만 Node Type을 RA3로 변경했습니다. RA3 노드에는 분산형 하드웨어 가속 캐시 AQUA 가 기본탑재 됩니다. AWS 직원의 표현을 빌리자면 “Redshift는 RA3를 기준으로 기원전과 후로 나뉜다” 고 말할 정도입니다. 성능면에서 월등해졌고 DC2 노드(160 GB) 대비 압도적으로 풍부한 스토리지(ra3.xlplus 기준 32 TB)를 보유하게 됩니다. 진짜는 다음입니다. RA3 노드는 managed storage를 통해 다른 클러스터와 데이터를 공유할 수 있습니다. 아래 이미지를 보면 PRODUCER CLUSTER와 CONSUMER CLUSTER는 각자의 컴퓨팅을 침범하지 않게 됩니다. 즉, 설령 어떤 문제가 있어서 한쪽 클러스터가 중단되더라도 다른 쪽 비즈니스에 영향을 주지 않는 것을 의미합니다. 이로써 데이터 분석가는 그들의 클러스터에 마음 편히 쿼리를 실행할 수 있게 됩니다.
여기까지 설명한 내용으로 그림을 그려보면 아래와 같습니다. 여기 그림에는 표현하지 않았지만 비즈니스 목적에 따라 총 두 개의 EKS Cluster가 운영 중입니다. 서비스 애플리케이션으로는 데이터를 수집하는 collector, 수집된 데이터를 변환하는 transformer 그리고 소재 이미지를 처리하는 sorceress 가 있습니다. 또한 collector와 transformer를 연결하는 bumblebee는 MSK에서 꺼내온 메시지를 SQS로 전달하는 가교 역할을 합니다.
간소화 아키텍처
앞으로의 과제
세상에는 무수히 많은 광고 매체와 트래커가 존재합니다. 우선 프리즘을 세계 No.1의 압도적인 광고 데이터 수집기로 발전시키고자 합니다. 필요한 데이터를 적절히 수집하기 위해서 도메인에 대한 이해도 필요합니다. 이를 극복하기 위해 팀에서는 매체 스터디를 꾸준히 진행하고 있습니다. 또한 매체의 API 버전업을 유연하게 대응하기 위한 고민을 하고 있습니다.
회사 비즈니스에서 나오는 모든 데이터와 내부에서 만들어지는 데이터를 프리즘으로 빨아들이고 그걸 토대로 데이터 분석가, 데이터 사이언티스트 혹은 비즈니스 분석가가 유의미한 아웃풋을 만들어낼 수 있도록 기여하고자 합니다. 위에서 소개한 JupyterHub는 사실 작은 규모의 분석에 적합하고 대량의 데이터를 소비하기 위한 분석 플랫폼을 별도로 구축할 계획입니다.
asynchronous로 동작하는 코드에 튜닝이 필요합니다. 컴퓨팅 리소스를 우리 비즈니스에 맞게 사용하기 위해 pod와 container 안에 coroutine 개수를 조정해 나가야 합니다.
튜닝.. 튜닝.. 튜닝… @unsplash
소재 이미지/영상을 다운로드하는 애플리케이션은 현재 EKS Cluster에서 동작중입니다. 현재 소재를 제공하는 매체에 다운로드 트래픽이 부하를 주지 않도록 다운로드 속도를 조절(throttling)하고 있습니다만 이미지 개수가 워낙 많아서 고민입니다. Horizontal Pod Autoscaler(HPA)로 적절히 조율해도 되겠지만 클러스터 노드의 자원을 이쪽이 전부 소진하게 둘 수는 없으니까요. 그래서 아마 App Runner 가 서울리전에 출시되면 옮겨가지 않을까 싶습니다. 어차피 애플리케이션은 dockerize 되어 있기 때문에 환경이 바뀌는 건 전혀 문제가 없습니다. 이처럼 배포한 애플리케이션이 동작하는 환경을 best practice로 생각할 수 있는지 끊임없이 의문을 갖고 개선해 나갈 예정입니다.
마치며…
이번 글에서는 프리즘을 회사차원에서 전반으로 소개했는데요. 다음 글은 개발자가 관심 있을만한 아키텍처와 데이터 파이프라인을 주제로 심도 있게 다뤄보면 좋을 것 같습니다. 사실 이번 글에서 Infrastructure as Code(IaC), Monorepo 등 하고 싶은 이야기는 많았지만 또 다른 기회가 있겠죠?
끝으로 매드업에서는 광고 데이터가 갖고 있는 문제를 함께 풀어나가며 성장하실 분을 찾고 있습니다. 동료는 최고의 복지 중에 하나입니다. 현직자에게는 지원자가, 지원자에게는 현직자가 최고의 복지가 될 수 있도록 팀을 빌딩하고 있습니다. 매드업은 내부적으로 기술적인 토론은 언제든지 환영하는 문화를 갖고 있습니다. 또한 신입사원도 프리즘의 코어와 IaC를 코드 리뷰를 통해 함께 구축해 나갑니다. 수평적인 문화를 지향하고 영어 닉네임을 사용하고 있습니다. 팬데믹에는 전사 재택을 하고 있으며 평시에는 주 2회 자유로운 재택근무가 가능합니다. 이런저런 복지가 더 많지만 지면을 아끼겠습니다. 자세한 복지는 다음 링크를 통해 확인해 주세요. - 매드업 복지
데이터 항해를 함께하길 원하시는 분, 기술적인 대화를 심도 있게 나눠보고 싶으신 분, 매드업이 궁금해서 커피 챗을 원하시는 분은 언제든 편하게 문의해 주세요. We need you :)
[1] : No Silver Bullet – Essence and Accidents of Software Engineering, 1986년 프레드릭 브룩스가 쓴 소프트웨어 공학 논문에 등장해서 주로 소프트웨어에서 사용되는 말로, 모든 문제를 한 번에 해결하는 마법은 없다는 표현.
]]>CaleyPython asyncio를 활용한 효율적인 광고 데이터 수집2022-12-29T00:00:00+00:002022-12-29T00:00:00+00:00https://tech.madup.com/python-asyncio-intro이 글에서는 파이썬 asyncio를 간단히 소개하고, 멀티스레딩에 비해 asyncio가 갖는 장점을 이야기 해보겠습니다.
그리고 제가 속해 있는 Data Platform팀에서 asyncio를 활용해 광고 데이터 수집의 효율을 어떻게 높이고 있는지 소개하고자 합니다.
그러면 이야기를 시작해 볼까요.
asyncio
asyncio는 비동기 I/O 프로그래밍을 위한 파이썬 기본 라이브러리로 파이썬 3.4에서 도입되었고, 3.5에서 async, await 키워드가 추가되면서 더 쉽게 사용할 수 있게 되었습니다.
그러면 비동기(asynchronous) I/O 프로그래밍이란 무엇이고, 왜 필요한 것일까요?
컴퓨터는 프로그램을 실행할 때 CPU, 메모리, 스토리지, 네트워크와 같은 자원들을 사용합니다. 그리고 I/O는 일반적으로 스토리지나 네트워크로부터 데이터를 읽거나 쓰는 작업을 말합니다.
그런데 I/O는 CPU, 메모리에 비해 처리 속도가 매우 느리기 때문에, I/O 바운드 프로세스인 경우에 비효율적인 상황이 생깁니다.
위의 코드는 특정 광고 캠페인의 정보를 가져오는 HTTP API를 1000번 호출하는 상황을 가정하였습니다. 여기서 requests.get으로 요청을 보낸 뒤, 프로그램은 응답을 받기까지 대기하게 됩니다.
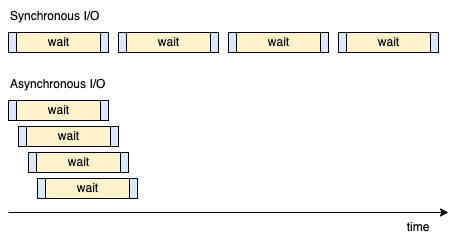
이러한 방식을 동기(synchronous) I/O라고 합니다.
응답을 받기까지 대략 1초가 걸린다고 한다면, 위의 코드가 실행되는 데는 최소 1000초 이상이 필요합니다.
실제로 로컬에 mock server를 구성하고 테스트 해보면 다음과 같습니다.
그리고 이 경우 CPU는 대부분의 시간을 대기 상태(wait state)로 있게 됩니다.
CPU가 네트워크 I/O를 기다리느라 놀고 있는 것이죠. 매우 비효율적인 상황입니다.
만약 위의 상황이 비효율적이라고 느껴지지 않는다면, 음식 배달 주문을 하는 상황을 생각해 보겠습니다.
치킨, 피자, 족발을 각각 전화로 배달 주문하려고 합니다. 어떤식으로 주문을 하시나요?
아마 대부분은 치킨을 주문한 뒤 바로 이어서 피자, 족발을 주문하고 음식이 올 때까지 기다릴 것입니다.
혹시 치킨을 주문한 뒤에 바로 피자를 주문하지 않고, 치킨이 도착할 때까지 기다렸다가 피자를 주문하는 경우가 있을까요? 아마 없을 것입니다.
비동기 I/O도 비슷한 개념입니다. 간단히 말하면 I/O로 인해 대기가 발생했을 때, 완료되기를 기다리는 동안 다른 작업을 수행할 수 있도록 하는 것입니다.
위에서 예시로 든 HTTP API를 1000번 호출하는 상황에 비동기 I/O를 적용하면, API 요청을 보내고 응답을 받기까지 대기하는 동안 다른 API를 호출할 수 있습니다.
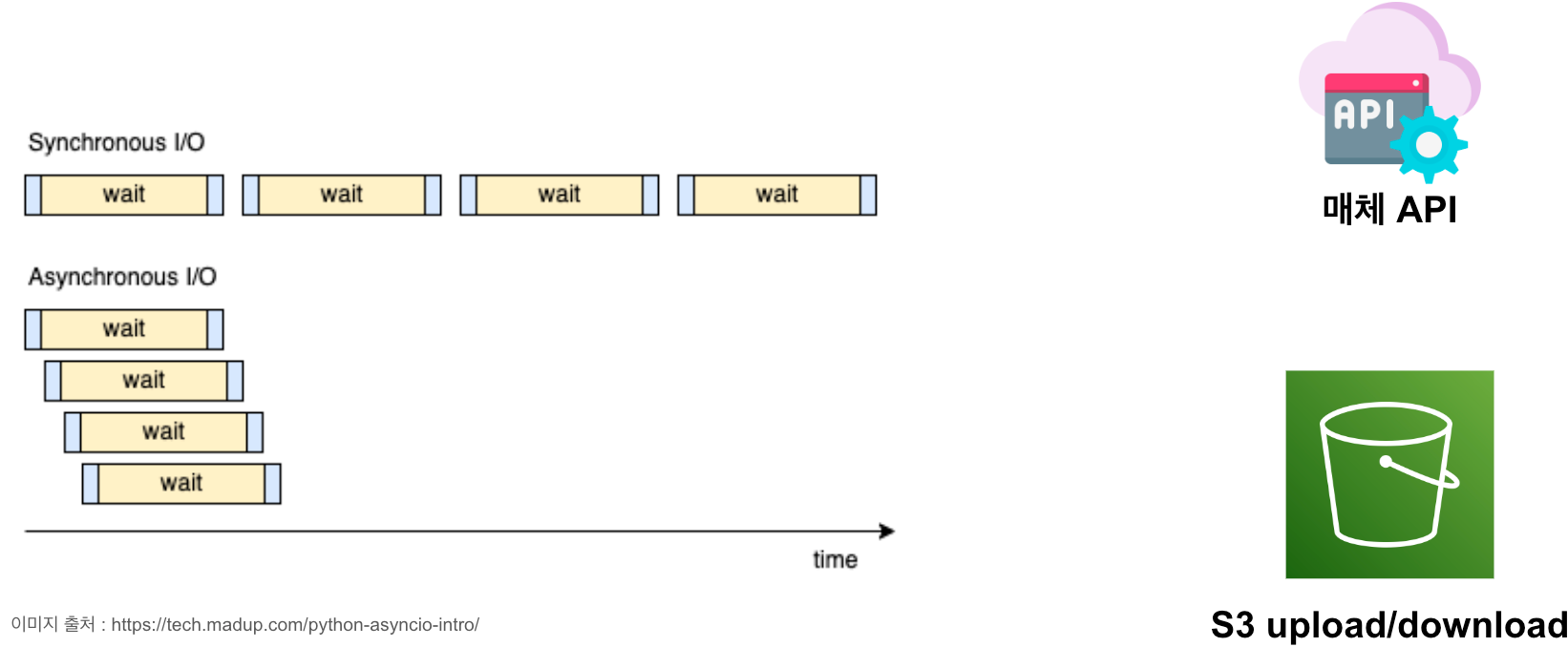
HTTP API를 1000번 호출하는 상황에서 동기와 비동기의 차이를 간략히 도식화 하면 다음과 같습니다.
Synchronous I/O vs Asynchronous I/O
위 그림에서 파란색 부분은 HTTP 요청을 보내고 받는, 코드가 실행되는 부분으로 보시면 되고, 노란색 부분은 서버의 응답을 기다리는 상태입니다.
동기 I/O는 순차적으로 실행되는 반면, 비동기 I/O는 대기 상태에 진입하면 다음 API를 호출하게 됩니다.
따라서 그림에서도 직관적으로 볼 수 있는 것처럼, 비동기 I/O는 실행 시간을 크게 줄일 수 있습니다.
지금까지 비동기 I/O의 장점에 대해 간략하게 살펴보았습니다. 다음으로 asyncio의 기본적인 구성 요소에 대해 간략히 설명하겠습니다.
이벤트 루프
위에서 비동기 I/O에 대해 설명할 때, 대기가 발생하면 완료되기를 기다리는 동안 다른 작업을 수행할 수 있도록 한다고 했습니다.
그렇다면 여러 작업들의 실행을 스케줄링 하는 뭔가가 필요하겠죠? 그게 바로 이벤트 루프입니다.
비동기 함수와 코루틴
비동기 함수는 말 그대로 비동기로 동작하는 함수이며, async def 키워드를 사용하여 정의합니다. 그리고 이러한 비동기 함수를 호출하면 코루틴이 됩니다.
(yield가 포함된 함수를 호출하면 제너레이터가 되는 것과 비슷합니다.)
그러면 코루틴은 무엇일까요? 코루틴은 완료되지 않은 채 일시 정지했던 함수를 다시 시작할 수 있는 기능을 가진 객체입니다.
제너레이터와 비슷하지 않나요? 실제로 파이썬 3.4에서는 제너레이터와 특별한 데커레이터를 통해 asyncio 라이브러리를 사용했었습니다.
그러다 파이썬 3.5에서 async def, await 키워드를 도입하면서 지금의 모습을 갖추게 되었습니다. 그래서 현재의 코루틴을 과거의 제너레이터 기반 코루틴과 구분하기 위해 네이티브 코루틴이라고 부르기도 합니다.
이러한 코루틴은 이벤트 루프에 등록되어 스케줄링에 따라 실행되게 됩니다.
await 키워드
await 키워드는 비동기 함수 안에서만 사용할 수 있는 키워드로 하나의 코루틴을 매개변수로 받으며,
비동기 함수 안에서 (다른 비동기 함수를 호출하여 생성한) 코루틴이 완전히 실행될 때까지 대기하도록 하는 역할을 합니다.
그리고 이벤트 루프에게 있어 await는 다른 코루틴으로 스케줄링 하는 시점이 됩니다.
Future와 Task
Future는 미래에 완료될 어떤 동작의 상태를 나타내기 위한 클래스이며, Future 인스턴스를 통해 이벤프 루프에 등록된 작업의 결과를 받아오거나 작업을 취소할 수 있습니다.
Task는 코루틴을 대상으로 하는 Future의 하위 클래스이며, Task 인스턴스를 통해 (Future와 마찬가지로) 이벤트 루프에 등록된 코루틴의 실행 결과를 받아오거나 코루틴을 동작을 취소할 수 있습니다.
지금까지 asyncio의 기본적인 구성 요소들을 살펴봤습니다. 그러면 asyncio를 적용한 코드를 살펴볼까요?
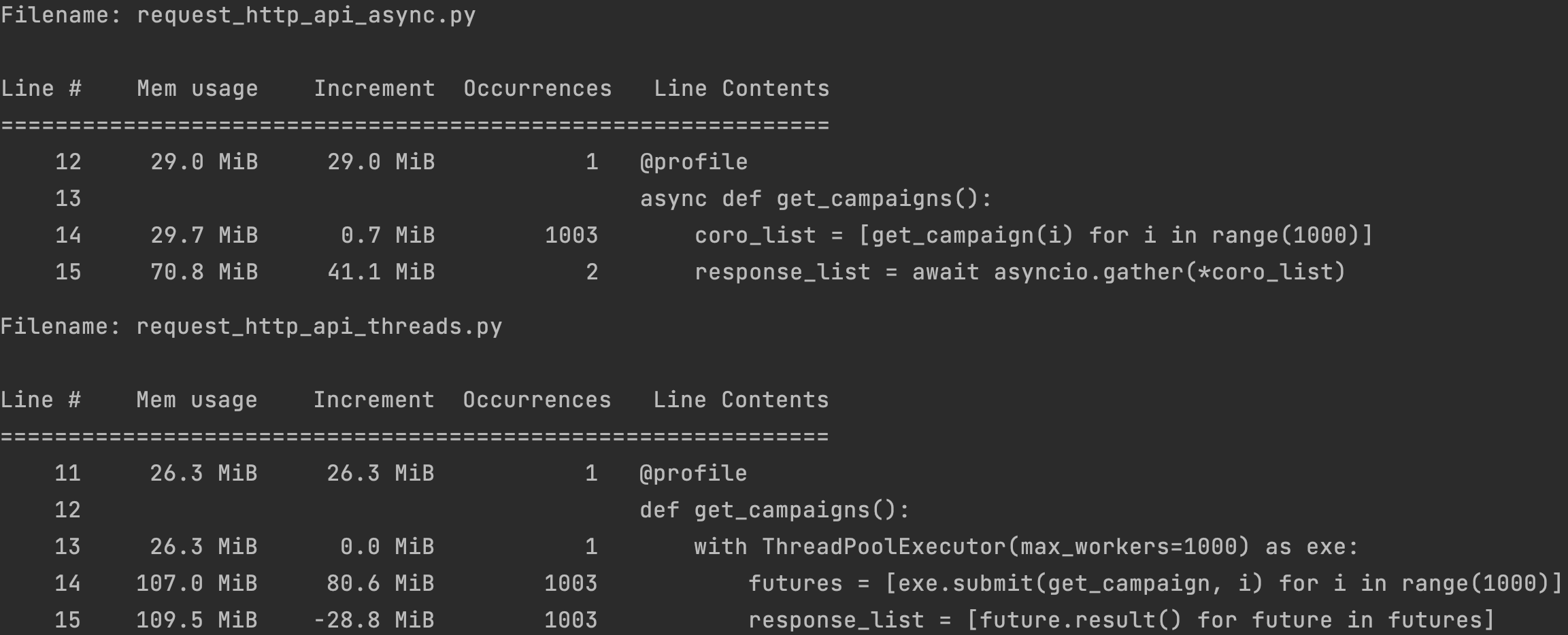
예제 1을 asyncio를 사용한 코드로 바꿔보면 다음과 같습니다.
비동기 HTTP 통신을 위해 aiohttp 라이브러리를 사용했습니다. get_campaign은 aiohttp를 사용해 캠페인 정보를 가져오는 비동기 함수이며, get_campaigns에서 이 비동기 함수를 호출해서 만든 코루틴들의 리스트인 coro_list를 만들었습니다.
즉 campaign_id 0~999까지 각각의 캠페인 정보를 가져오는 코루틴 1000개가 만들어졌습니다. asyncio.gather는 여러 개의 코루틴 또는 태스크를 모아서 처리할 수 있도록 해줍니다.
그래서 await asyncio.gather(*coro_list) 코드는 1000개의 코루틴이 모두 완료될 때까지 대기하게 됩니다.
끝으로 asyncio.run은 이벤트 루프를 새로 만들고 파라미터로 받은 코루틴의 실행이 완료될 때까지 대기하게 되는데, 일반적으로는 asyncio.run(main())과 같이 비동기 프로그램의 main 함수를 실행시키는 역할을 합니다.
여기서 강조하고 싶은 것은 코드에 대한 자세한 설명보다 asyncio를 통해 얼마나 소요 시간을 줄일 수 있는지입니다. 다음은 위의 코드를 실행한 결과입니다.
예제 1에서 1000초가 넘게 걸렸던 소요 시간이 1.55초로 줄었습니다.
이러한 간단한 예제를 통해 네트워크 통신이 많이 발생하는 프로그램에서 왜 asyncio를 사용해야 하는지 알 수 있습니다.
asyncio vs multi-threading
위에서 asyncio를 사용하여 동시에 여러 개의 HTTP 요청을 보내는 것을 살펴보았습니다.
동시에 여러 개의 작업을 실행해야 할 때 많이 사용하는 다른 방법에는 멀티스레딩이 있습니다. 새로운 스레드를 생성하여 병렬로 실행하는 것이죠.
여기서는 멀티스레딩을 사용하는 것과 비교했을 때 asyncio의 장점을 이야기 해보고자 합니다.
물론 모든 경우에 asyncio가 멀티스레딩보다 낫다라고 말하고 싶은 것은 아닙니다. 분명 멀티스레딩이 더 적합한 상황이 존재합니다.
여기서는 네트워크 통신과 같이 I/O가 많이 발생하는 상황을 기준으로 설명하겠습니다.
우선 스레딩과 asyncio 사이에 존재하는 근본적인 차이에 대해 이야기 해보고자 합니다.
스레드는 OS에서 제공하는 기능이며 한 프로세스 내에서 코드를 병렬로 실행하고자 할 때 사용합니다. 이때 각 스레드는 다른 CPU 코어에서 실행될 수 있습니다.
즉 물리적으로 병렬(parallel) 처리가 이뤄집니다. 그래서 계산량이 많은 작업을 병렬로 나눠서 처리할 때도 많이 사용합니다.
하지만 파이썬에서는 GIL(Global Interpreter Lock)이라는 존재 때문에 한 번에 하나의 바이트코드만 실행할 수 있기 때문에 이러한 병렬성에 제한이 있습니다.
asyncio는 OS가 아닌 프로그램 영역에서 제공하는 기능입니다.
하나의 스레드에서 이벤트 루프를 만들고 코루틴 또는 태스크라고 하는 것들을 번갈아가면서 실행하는 것입니다.
스레드처럼 물리적으로 병렬 처리하는 것은 아니기 때문에 asyncio를 사용한다고 해서 계산상의 이점은 없습니다.
대신 asyncio는 I/O가 발생할 때 block 하지 않고 다른 코루틴, 태스크를 실행할 수 있도록 스케줄링 해주기 때문에 여러 I/O 작업들이 동시에(concurrent) 실행되는 것처럼 느끼게 해주는 것입니다.
그러면 스레딩에 비해 asyncio가 가진 장점을 2가지만 이야기 해보겠습니다.
경합 조건(race condition)을 피할 수 있다!
멀티스레딩으로 복잡한 프로그램을 개발해본 분이라면, 경합 조건으로 생긴 버그를 디버깅 하느라 고생했던 적이 있으실 것입니다.
멀티스레딩은 스레드들이 병렬로 실행되기 때문에 공유 자원을 동시에 접근하는 경우에 경합 조건이라는 문제가 생길 수 있습니다.
하지만 asyncio는 물리적 병렬(parallel) 실행이 아닌 논리적 동시(concurrent) 실행이기 때문에, 프로세스 내부에서 발생할 수 있는 대부분의 경합 조건을 쉽게 피할 수 있습니다. 또한 await 키워드를 통해 코루틴 간에 제어가 전환되는 시점을 개발자가 확인할 수 있기 때문에 경합 조건을 피하는데 도움이 됩니다.
이러한 이유로 MSA(Micro Service Architecture) 환경에서 프로세스 외부의 공유 자원에 대해 생길 수 있는 경합 조건도 쉽게 방지할 수 있습니다.
적은 자원 사용량
asyncio는 스레딩에 비해 더 적은 자원을 사용합니다.
스레드는 생성될 때 별도의 스택 메모리 공간을 할당하여 사용하지만, asyncio는 단일 스레드에서 실행되기 때문에 별도의 스택 메모리 공간이 필요하지 않습니다.
또한 CPU 사용에 있어서도 asyncio가 스레딩보다 효율적입니다.
병렬 처리를 위해 1000개의 스레드를 생성했다고 생각해 볼까요. 스레드 개수가 CPU 코어보다 많기 때문에 계속해서 context switching이 발생하게 됩니다.
이러한 context switching은 스레드가 I/O로 인해 block 된 상태에서도 계속해서 발생하며,
OS는 이러한 스레드들을 관리하고 스케줄링 하는데 시간과 자원을 사용하게 됩니다.
asyncio는 단일 스레드에서 실행되기 때문에 이러한 스레드 간의 context switching이 필요하지 않으며, select, poll, epoll과 같은 시스템 콜을 통해 실행 재개가 필요한지를 확인할 수 있어 효율적으로 코루틴 간의 실행을 전환할 수 있습니다.
그러면 예제 2를 멀티스레딩을 사용하도록 수정해볼까요?
수정된 코드와 실행 결과는 다음과 같습니다.
멀티스레딩이 조금(0.22 초) 더 시간이 걸렸습니다. 큰 차이는 아니지만 asyncio가 멀티스레딩보다 조금 빠름을 확인할 수 있었습니다.
time 명령어를 적용해보면 더 많은 정보를 얻을 수 있습니다.
% time python request_http_api_async.py
elapsed time: 1.55 seconds
python request_http_api_async.py 0.56s user 0.17s system 42% cpu 1.743 total
% time python request_http_api_threads.py
elapsed time: 1.77 seconds
python request_http_api_threads.py 0.93s user 0.43s system 72% cpu 1.878 total
위의 결과를 보면, asyncio를 사용하는 코드가 CPU를 더 적게 사용했다는 것을 확인할 수 있습니다.
그러면 메모리 사용량은 어떨까요? memory_profiler를 사용하여 확인한 결과는 다음과 같습니다.
asyncio가 멀티스레딩에 비해 메모리 사용량도 적음을 확인할 수 있습니다.
이러한 차이가 크지 않게 느껴지실 수도 있습니다.
하지만 더 적은 시간과 자원을 사용하면서도 경합 조건과 같은 멀티스레딩을 사용할 때 겪을 수 있는 문제를 피할 수 있게 해 준다는 점에서 asyncio는 충분히 사용할 가치가 있다고 생각합니다.
asyncio를 활용한 광고 데이터 수집
제가 속해 있는 매드업의 Data Platform팀에서는 여러 광고 매체 또는 트래커에서 제공하는 API를 사용하여 광고 성과 지표들을 수집하고 있습니다.
주로 HTTP API를 호출하여 받아온 데이터를 필요에 맞게 가공한 뒤 데이터 웨어하우스에 저장하게 됩니다.
이러한 광고 데이터 수집을 위해 프리즘이란 시스템을 운영하고 있는데, 프리즘은 여러 마이크로 서비스로 구성되어 있습니다.
그중에서 수집을 담당하는 컬렉터와 스로틀링 처리를 하는 스로틀러에서 asyncio를 어떻게 사용하고 있는지 소개하겠습니다.
컬렉터(Collector)
컬렉터는 데이터 수집을 담당하는 서비스입니다.
주된 작업은 HTTP API를 호출한 결과를 파일로 저장하고 AWS S3에 업로드 하는 것입니다.
이러한 작업을 효율적으로 하기 위해 asyncio를 사용하고 있는데,
각 과정을 asyncio 기반 비동기로 처리하기 위해 다음과 같은 라이브러리들을 사용하고 있습니다.
aiohttp: 비동기 HTTP 통신 지원
aiofiles: 비동기 파일 read/write 지원
aiobotocore: 비동기 S3 upload/download를 지원
asyncio를 적용하여 수집 효율을 높이게 되었고, 컬렉터 서비스에 필요한 컨테이너 개수를 줄일 수 있었습니다.
스로틀러(Throttler)
스로틀러는 HTTP API의 호출 제한을 지키기 위해 사용하는 서비스입니다.
광고 매체나 트래커에서 제공하는 API에는 호출 횟수나 간격에 대한 제한이 있는 경우가 있습니다.
예를 들면 어떤 API는 동일한 광고 계정에 대해 5초당 1번만 호출할 수 있다거나, 1시간 동안 60회 이상을 호출하면 안 된다는 식의 제한이 있습니다. 그래서 이러한 제한들을 모두 지키면서 API를 호출하기 위해서는 API를 호출하는 흐름을 제어하는 역할이 필요하고, 그 역할을 스로틀러가 맡고 있습니다.
(스로틀링에 대한 자세한 내용은 어서 와, 광고 데이터 수집은 처음이지? (FEAT. KRAKEN)를 참조 바랍니다.)
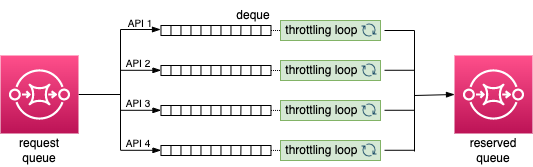
스로틀러가 하는 일을 대략적으로 도식화 하면 위의 그림과 같은데, 프로세스를 간단히 설명하면 다음과 같습니다.
모든 API 호출 요청은 request queue로 들어옵니다.
스로틀러는 queue에서 메시지를 가져온 뒤 API 별로 할당된 deque에 메시지를 넣습니다.
(하나의 deque에는 동일한 API에 대한 호출 요청 메시지가 들어가게 됩니다.)
deque 별로 스로틀링 루프가 할당되어 있는데, 이 루프에서는 deque에서 메시지를 꺼내어 reserved queue로 전송합니다.
스로틀링 루프는 해당 API의 호출 제한을 지키기 위해 deque에서 메시지를 꺼내는 속도를 조절하게 됩니다.
컬렉터는 reserved queue에서 메시지를 꺼내고, API를 호출하여 데이터를 수집합니다.
위의 그림에서는 스로틀링 루프를 4개만 표시했지만, 실제로 필요한 스로틀링 루프는 수천 개가 될 수 있습니다
(매체 또는 트래커 개수 × API 개수 × 광고 계정 개수).
그리고 스로틀링 루프들은 동시에 실행되어야 합니다.
동시 실행을 위해 스레딩을 사용한다면 어떨까요? 스레딩을 사용할 수는 있습니다. 하지만 스레딩은 asyncio에 비해 자원을 많이 사용하게 되고 context switching이 계속 발생하는 것도 비효율적이라고 판단했습니다.
그래서 asyncio를 사용하기로 하였고, 스로틀링 루프에 해당하는 부분을 코루틴으로 만들어 이벤트 루프에서 돌아가도록 했습니다.
asyncio를 적용하여 더 적은 자원으로 스로틀링을 효율적으로 하게 된 것이죠.
글을 마치며
지금까지 비동기 I/O란 무엇인지, 그리고 파이썬에서 비동기 I/O를 사용하기 위한 표준 라이브러리인 asyncio에 대해 간략하게 살펴봤습니다.
그리고 매드업의 Data Platform팀에서 asyncio를 사용해 어떻게 광고 데이터 수집의 효율을 높이고 있는지 소개했습니다.
아마 많은 파이썬 개발자 분들이 이미 asyncio를 사용하고 계실거라 생각합니다.
아직 사용하지 않고 있고 I/O의 비중이 큰 프로그램을 개발하고 계시다면 asyncio를 꼭 사용해 보시면 좋겠습니다.
이 글에서는 지면 관계상 asyncio 라이브러리에 속한 함수들에 대한 자세한 설명보다는 왜 asyncio를 사용해야 하는지에 초점을 맞춰서 설명하고자 했습니다.
다음에 기회가 되면 함수들에 대한 자세한 설명과 함께 asyncio 기반 프로그램을 우아하게 종료하는 방법에 대해서도 다른 글을 통해 소개해 드리도록 하겠습니다.
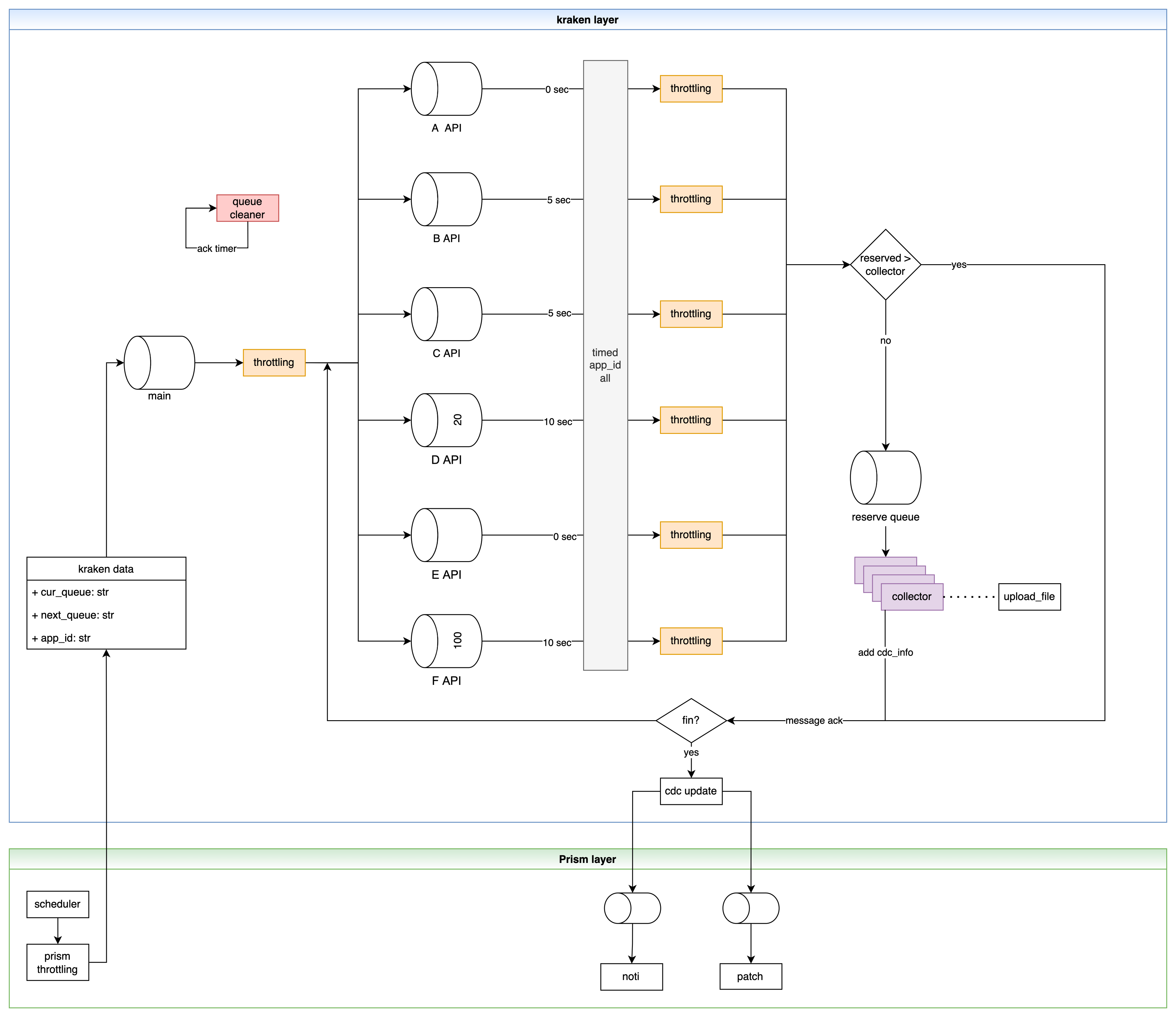
]]>Andy어서 와, 광고 데이터 수집은 처음이지? (feat. kraken)2022-07-01T00:00:00+00:002022-07-01T00:00:00+00:00https://tech.madup.com/kraken-intro이번 글에서는 매드업의 DMP 프리즘의 일부인 크라켄을 소개합니다. 크라켄은 매드업에서 구축한 데이터 수집 플랫폼입니다. API 호출 제약이 상대적으로 빡빡한 매체의 데이터 수집을 담당합니다. API 호출 제약으로 인해 어떤 어려움이 있었는지, 그리고 크라켄은 어떻게 이런 어려움을 극복했는지 알아보겠습니다. 비개발자도 편하게 읽으실 수 있도록 기술적인 내용은 후반부에 짧게 다룹니다.
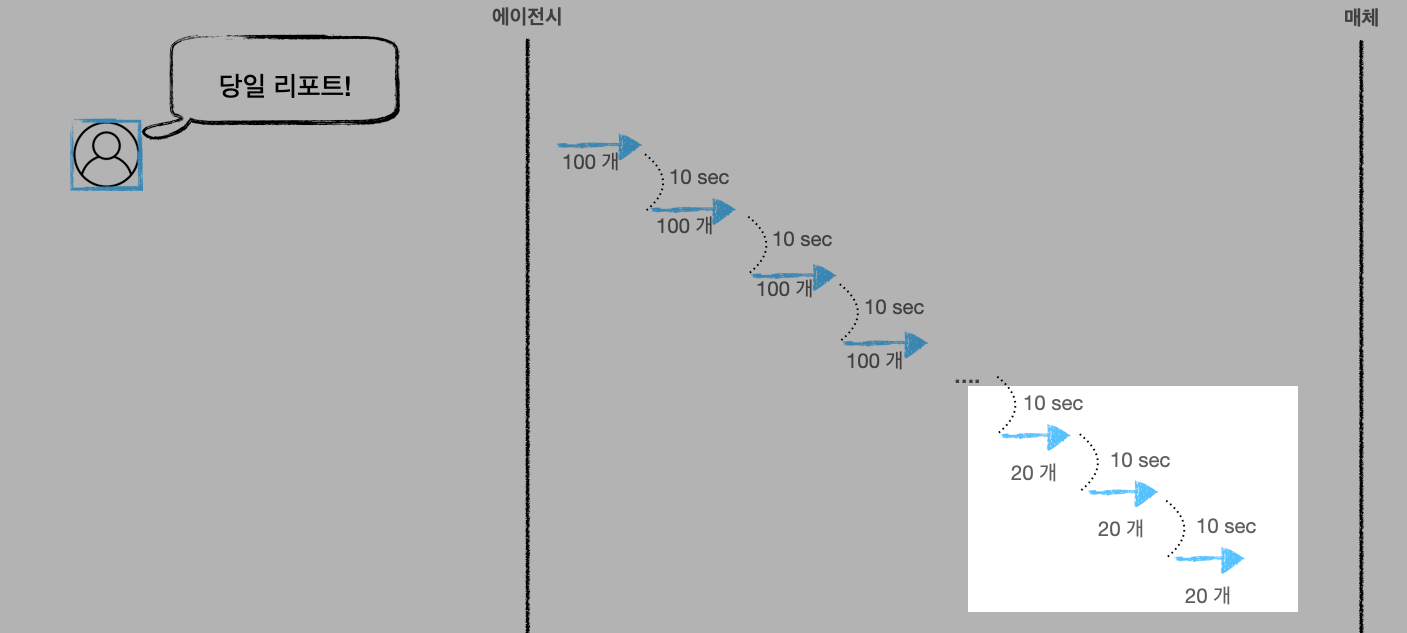
어서 와, 광고 데이터 수집은 처음이지?
구글, 페이스북, 트위터 등 광고 매체로부터 데이터를 내려받는 가장 쉬운 방법은 무엇일까요? 아마도 매체 사이트에서 그들이 제공해주는 data export 기능을 통해 다운로드하는 것 일 겁니다. 하지만 쉬운만큼 사람이 직접 몇 번의 클릭을 해야 하는 등 시간을 투자해야 한다는 단점이 있습니다. 그리고 매우 루틴 한 작업임과 동시에 필터 조건 등 생각 없이 클릭하면 데이터가 기존과 달라질 수도 있습니다.
프로그래밍을 할 줄 안다면 매체에서 제공해주는 API를 사용하는 것도 아주 좋은 방법입니다. API 호출을 구현하면 언제 어떤 환경에서든 필요한 데이터를 자동으로 다운로드할 수 있습니다. 아, 물론 우리 쪽 서버 자원(비용)은 조금 들겠지만요. 하지만 고급 인력(AE)이 데이터 다운로드를 위해 사이트에서 이것저것 클릭하는 시간/비용보다는 저렴할 겁니다. 매번 여러 광고주의 데이터 다운로드를 위해 클릭을 하다 보면 아무래도 사람이다 보니 실수할 여지도 있지 않겠습니까? 더욱이 한 사람이 여러 광고 매체를 다루는 일도 빈번하니까요. 즉, 여러 가지 위험(실수)에 노출됩니다. 이런 이유로 여건만 된다면 데이터를 브라우저를 통해 다운로드하는 방식이 아니라 API를 사용하는 게 훨씬 좋겠습니다.
세상에 쉬운 일은 없다 - “데이터를 호락호락 줄 순 없지!”
그런데 말입니다. API는 개발의 어려움을 차치하더라도 생각보다 깐깐한 경우가 많습니다. 일반적으로 우리가 광고 매체에 리포트 데이터(이하 A)를 요청하면 A를 내려주는 걸 생각할 수 있는데요. 아래 이미지를 살펴보시죠. 여기서는 편의상 캠페인 리포트를 요청했다고 표현했습니다. 캠페인 리포트를 요청하면 캠페인 리포트를 응답 주는 방식입니다. 당연한 내용입니다.
자, 그러면 A를 동시에 5개 요청해보죠. 에이전시에서 관리하는 다섯 개의 광고주 데이터를 요청한다고 가정하는 겁니다. 이 경우도 보통은 잘 줍니다.
동시라고 표현했지만 위에 이미지는 parallel과는 거리가 있죠. 다양한 독자에게 설명하기 위한 개념적인 이미지이므로 개발자님들의 너른 양해 부탁드립니다
그렇다면 A x 500은 어떨까요? 동시에 500개를 요청하는 겁니다. 대부분의 광고 매체는 이런 경우 데이터를 내려주지 않습니다. 왜 그럴까요? 짧은 시간에 이렇게 많은 요청을 보내는 게 정상이 아니라고 판단하기 때문입니다. 혹은 “방금 데이터 내려줬는데 왜 또 요청해?”, “우리 서버는 당신 혼자 쓰는 게 아니야!” 같은 이유가 있습니다. 결국은 자신들의 서버를 보호하려는 목적이죠. 그래서 API는 제약사항이 걸려있는 경우가 많은데요. 그 제약사항은 API 명세(개발을 위해 필요한 문서)를 살펴보면 대부분 잘 나와있습니다. rate limit, call limit 같은 항목으로요. “초당 10개 이상의 요청을 보낼 수 없음”처럼 정확하게 안내해주는 곳이 있는가 하면 “짧은 시간에 여러 요청을 보낼 수 없음”처럼 애매하게 나타내는 곳도 있습니다. “호출 제한이 걸리면 잠시 후에 다시 시도하세요”처럼 API 사용자가 해야 할 조치를 결정하는 데 필요한 정보를 충분히 내려주지 않기도 합니다.
심지어 어떤 매체의 경우 “10초에 1회만 호출 가능” 같은 제약도 있습니다. 여러 광고주의 데이터를 다운로드해야 하는 에이전시 입장에서 이런 시간 제약은 아주 골치 아픕니다. 더욱이 기술력을 갖추지 못한 에이전시라면 늘어나는 광고주 수를 감당하지 못할 겁니다. 이번 글은 바로 이 제약 조건, “10초에 1회만 호출 가능”를 지키면서 늘어나는 광고주 수에도 흔들리지 않고 많은 데이터를 수집할 수 있는 플랫폼에 대한 이야기입니다. 매체에 처음부터 이런 제약이 있었던 것은 아닙니다. (사용자 입장에서는) 매체 API 새 버전이 출시되면서 생긴 제약이었죠.
응, 원래 안 되는 건데 버그가 있었어 (https://devtalk.kakao.com/t/api/110942/6)
아, 그건 그렇고 동시에 500개를 요청해야 하는 상황이 있냐고요? 에이전시 입장에서는 충분히 가능한 상황입니다. 광고주 수가 많을 수도 있고 한 광고주가 운영하는 캠페인이 아주 많을 수도 있으니까요. 아래 그림을 보면 노란색 광고주는 캠페인 리포트 한 개만 받아도 되는 반면 핑크색 광고주는 캠페인 다섯 개를 운영하고 있네요. 전체적으로 보면 광고주는 네 개지만 받아야 하는 캠페인 리포트는 10개인 상황입니다. 이런 계산이면 얼마든지 500개까지 늘어날 수 있죠.
또한 광고 데이터가 확정되는 시간(전환 데이터 등)을 고려하면 당일 데이터뿐만 아니라 과거 데이터도 함께 수집해야 하는 경우가 많습니다. 광고주에게 제공하는 리포트에 정확한 수치를 담기 위해서입니다. 아무튼, 이렇게 동시에 많은 요청을 보내면 앞서 이야기한 이유로 광고 매체는 리포트 데이터를 주는 대신 아래 같은 “에러”를 돌려줍니다.
429 Too Many Requests
여기까지 생각하면 “아, 그러면 적당히 텀을 두고 요청하면 되겠네”라고 생각하실 수 있습니다. 아래처럼 말이죠.
이렇게 시간 간격을 두는 건 좋은 아이디어라고 생각합니다. 일반적으로 throttling과 같은 이름으로 실제 개발에서도 종종 사용하는 방식입니다. 아무튼, 좋은 아이디어라는 건 매체 API 특성을 잘 모를 때는 일입니다. 이 글에서 아직 언급하지 않은 제약이 남아있습니다.
아직 (제약) 한 발 남았다
@네이버 영화 스틸컷
“10초에 1회만 호출 가능”에 더해서 1회 호출로 내려받을 수 있는 데이터 양의 최댓값이 정해져 있습니다. 고로 모든 데이터를 받아오기 위해서는 pagination 처리가 필요합니다. 예를 들어 데이터가 1,000 조각 있다면 한 번에 내려받을 수 있는 건 100개인 상황입니다. 우리가 인터넷에서 흔히 볼 수 있는 게시판을 생각하면 쉽게 이해가 되실 겁니다. 한 페이지에 100개의 데이터만 보이고 “다음 페이지” 버튼을 누르면 다음 100개 항목이 보이는 거죠. 게시판은 조금 올드한 느낌인가요? 그렇다면 모바일에서 많이 사용되는 infinite scroll(쇼핑몰 앱에서 스크롤을 내리면 새로운 아이템 목록이 계속 불러와지는 개념)을 떠올리셔도 좋습니다. 그런데 문제는 다음 페이지 버튼(혹은 스크롤)이 정상적으로 동작하려면 10초가 필요하다는 겁니다. API 제약 사항 때문에요!
일부 매체 API에도 이러한 pagination 개념이 들어가 있습니다. 위에서 예시로 들었던 1,000개의 데이터를 모두 받으려면 산술적으로 생각했을 때 (요청하고 실제 다운로드하는 데 걸리는 시간을 0초로 생각해도) 10번 호출을 해야 합니다. 총 걸리는 시간은 10초에 1회만 호출 가능하니까 100초, 즉 1분 40초가 필요하네요. 그리고 당연한 이야기지만 위에 파란색 광고주의 데이터를 수집하는 도중에 같은 API를 호출하게 되면 에러가 발생합니다. 10초마다 1회 호출해야 하는 제약을 준수하지 않았기 때문이죠. 아래는 에이전시에서 파란색 광고주 데이터를 수집하는 도중에 핑크색 광고주를 위해 API를 추가로 사용한 경우입니다.
여기서 또 다른 문제가 등장합니다. 매드업은 광고주에게 수준 높은 리포트를 제공하기 위해서 이런 API x N개를 호출해서 뽑아낸 데이터를 조합해서 사용합니다. 지금까지는 캠페인 리포트에 대한 이야기만 다뤘는데 광고그룹 리포트도 있을 수 있죠. 여기도 호출 제약이 존재합니다. 이 API는 한 번에 가져올 수 있는 데이터가 20개입니다.
최종 리포트 생성을 위해 필요한 데이터를 위의 이미지처럼 순차적으로 받는 건 가장 기본적인 방법입니다. 에이전시 입장이 아니라면 최선/최고의 방법이기도 하고요. 하지만 여러 광고 계정(광고주)의 정보를 일괄적으로 가급적 빠른 시간 안에 수집해야 하는 매드업 입장에서는 그리 좋은 방식이 아니었습니다. 한 개 광고주 데이터를 모두 받는데 60분 걸린다고 치면, 10개 광고주 데이터를 받는데 필요한 산술적인 시간은 600분입니다. 10시간 이상을 쉬지 않고 수집해야 리포트를 생성할 수 있는 거죠(중간에 에러가 없다는 가정). 더욱이 매드업은 급성장하는 로켓인 만큼 광고주 수도 기하급수적으로 늘고 있기 때문에 새로운 방식이 필요했습니다. 우리가 풀어내야 하는 문제에 욕심을 더해서 모든 데이터가 새벽에 수집돼서 아침에 리포트로 발송되길 원했습니다. 마케팅 에이전시의 새벽 배송이랄까요?
바야흐로, 크라켄의 등장
매드업은 이런 API 제약 상황을 타개해야 했습니다. 우리는 기술 기반의 회사니까요. 매체 데이터 수집에 어려움이 있다고 해서 고객에게 제공되어야 할 리포트에 구멍이 생겨서는 안 되겠죠. 우선 이 미션을 해결하기 위해 매체의 제약사항을 다시 한번 빠르고 정확하게 정리해봤습니다. 그 결과 우리가 극복해야 하는 상황은 정말 괴물같이 느껴졌습니다.
위에서 편의상 “10초에 한 번 호출 가능(이하 A)”이라고 표현했지만 “5초에 한 번 호출 가능(이하 B)”처럼 API 마다 시간 제약이 다릅니다. 또한 최고의 리포트를 제공하기 위해 수집해야 하는 API 종류도 다양합니다. 결정적으로 시간 제약은 언제든 매체 API 업데이트로 바뀔 수 있습니다. 그렇다면 우리가 생각할 수 있는 방법은 parallel 하게 A는 A대로 필요하면 계속 호출(수집)하고 B는 B대로 호출(수집)을 계속해주면 됩니다. 마치 크라켄의 다리 하나하나가 서로 다른 API 종류이고 빨판 간격은 다음 호출에 필요한 시간 간격(제약)과 같습니다. 후술 하겠지만 광고 계정 종류는 중요하지 않습니다. 다양한 API를 통해 수집한 정보는 나중에 한 번에 취합하면 되니까요.
크라켄 컨셉
컨셉을 이해하기 위해 다리를 뜯어봅시다. 크라켄의 다리를 그림으로 표현하면 다음과 같습니다.
빨판이 달려있는 크라켄 다리
이 다리에 빨판 부분은 API 호출을 나타냅니다. 그리고 빨판 간격은 API 호출 간 제약(10초)을 나타내고요. 이런 내용을 추가해주면 아래처럼 표현됩니다. 여기부터 비슷한 그림이 연속으로 추가되므로 잘 따라오셔야 합니다. “이건 문어 다리야”라고 마인드 컨트롤을..
위에 그려진 크라켄 다리는 캠페인 리포트를 처리합니다. 끊임없이 계속 처리합니다. 매체에서 정해준 호출 간격대로 말이죠. 다음으로 우리에게 필요한 건 광고그룹 리포트입니다. 크라켄에 다리를 추가해줍시다.
장난 같지만 여기 추가로 받아야 하는 데이터가 생기면 크라켄에 다리를 추가해주면 됩니다.
데이터가 쌓이기만 해서는 의미가 없습니다. 여기 특정 광고주의 정보를 색칠해보면 아래처럼 표시됩니다.
파란색의 마지막 데이터가 최종적으로 수집되면 해당 정보를 매드업의 Data Warehouse에 저장합니다. 이제 리포트 생성을 위한 데이터 준비는 끝났습니다!
크라켄 아키텍처
이렇게 글을 마무리할까 고민도 했지만 기술적인 내용이 없으면 개발자의 갈증을 채울 수 없겠죠. 크라켄을 구축에 들어간 기술 스택과 아키텍처에 대한 이야기를 해보겠습니다. 모든 구성은 AWS ECS로 구축되어 있습니다. 매체와 직접 통신을 해야하기 때문에 인스턴스는 Public subnet을 이용합니다. Private subnet에 두고 NAT를 연결하는 방법도 있지만 이때는 data transfer 비용을 감수해야 합니다.
크라켄 아키텍처
세부 아키텍처를 살펴보겠습니다. 크라켄을 이루는 컴포넌트로는 매체 API 호출 제약을 조절하는 throttling application과 수집을 담당하는 collect application, 무중단 서비스 목표를 달성하기 위한 checker application으로 나뉘어 있습니다. 모두 python으로 구현되어 있으며 GitHub Actions를 통해 자동 배포됩니다. feature 단위로 배포하고 있기 때문에 필요한 경우 하루에도 수 회 이상 배포되고도 합니다. 최근에는 신규 기능 요청이나 특별한 이슈가 없어서 최근 5번의 스프린트 동안 15회 배포 밖에 없었네요. 🙂
우선 수집해야 하는 광고주 정보는 RDS에서 관리됩니다. 해당 정보를 바탕으로 주기적으로 수집 프로세스가 운영되는데 이는 Event Driven 방식으로 좌측에 있는 Kraken stream(main)를 통해 요청이 들어오게 됩니다.
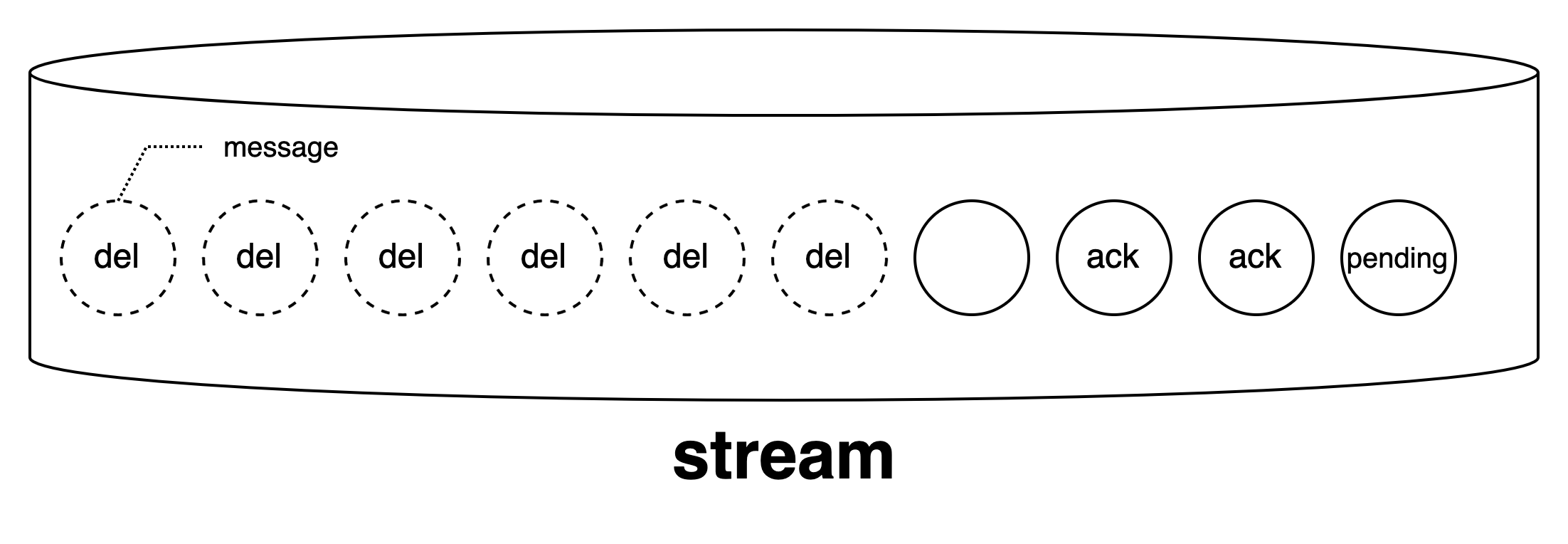
Kraken stream은 AWS ElastiCache for Redis의 stream 타입입니다. Event Driven 방식으로 설계를 할 때 교과서처럼 등장하는 kafka도 함께 고려되었지만 당장 크라켄에 필요한 건 데이터가 정상적으로 수집이 되었다는 message ack 기능이었기 때문에 redis stream으로 충분했습니다. 이해를 돕기 위해 redis stream 방식에 대해 짧게 설명하고 넘어가겠습니다. stream은 들어오는 메시지에 대해 몇 가지 상태를 정의할 수 있습니다. 아래 그림을 봐주세요.
stream으로 처음 메시지가 들어오면 아무 상태도 갖지 않습니다. 위에 텍스트가 없는 빈 원을 보시면 됩니다. 그 상태에서 메시지가 꺼내지면 pending 상태로 기록되고, 메시지 처리가 끝나면 그 결과를 ack로 마킹할 수 있습니다. 끝으로 stream 내에서 메시지를 삭제할 수 있습니다. 삭제되면 존재하지 않는 상태지만 위에 그림에서는 개념상 표현을 위해 del로 표기했습니다. 이렇게 stream의 상태 기록을 통해 매체 데이터가 정상적으로 수집되었는지 크라켄은 판단하게 됩니다.
데이터 수집이 완료되면 이 정보는 Prism stream으로 전달됩니다. 프리즘(prism)은 kraken을 감싸고 있는 더 큰 플랫폼으로 매드업의 DMP(Data Management Platform)입니다. 나중에 다른 글을 통해 프리즘 아키텍처가 상세히 소개될 예정입니다. 매체 서버의 오류나 기타 이유로 수집 중간에 문제가 발생하는 경우 message ack를 처리하지 못하기 때문에 해당 정보를 감시하던 checker application은 지정된 횟수만큼 이를 다시 시도합니다.
한편, kraken stream이 크라켄의 다리 역할을 맡고 있으므로 다리 증설이 필요한 경우 stream key를 추가로 정의해주면 됩니다. 즉, 신규 API 수집이 필요한 경우 stream을 새로 지정해서 사용하게 되는데요. API 마다 endpoint, query param 등 필요한 정보가 다르므로 필연적으로 구현이 필요합니다. 하지만 초기부터 확장을 염두하고 설계/구현했기 때문에 어렵지 않게 신규 API를 붙일 수 있습니다.
마무리
이번 글에서 다루지는 않았지만 매체에는 A 리포트를 수집하려면 B 리포트 정보가 필요하고, B 리포트를 수집하려면 C 리포트가 필요한 경우가 있습니다. 그렇다는 이야기는 크라켄 다리는 완전한 독립이 아니라 서로 인과관계가 있음을 나타냅니다. 사실 크라켄의 핵심 기술은 거기에 있죠. 매체의 API 호출 제약이 나날이 심해지면서 많은 에이전시가 어려움을 겪고 있습니다. 하지만 매드업은 크라켄을 구축함으로 에러 없이 필요한 시점에 정확히 리포트 데이터를 수집하고 있습니다. 그리하여 평소 5~10% 수집 에러가 발생하고 있던 해당 매체의 에러 비율을 0%가 됐습니다.
글의 일부 내용은 실제 매체의 제약과 100% 일치하지 않습니다. 누군가 이 글을 읽는데 어려움이 없도록 편의상 각색한 부분이 존재하기 때문입니다. 예를 들어 캠페인 리포트의 경우 한 번에 5개씩 가져올 수 있으며 5초에 1회 허용됩니다. 또한 이 글이 발행되고 매체가 업데이트되는 경우 더 괴리감이 생길 수도 있습니다. 하지만 크라켄도 매체의 업데이트에 따라서 진화하게 될 겁니다 🙂
소프트웨어 엔지니어가 개발하는 코드는 비즈니스로 연결되어 고객에게 높은 가치를 제공할 때 비로소 빛을 봅니다. 매드업은 함께하는 광고주의 가치가 더욱 빛 날 수 있도록 여러 가지 프로덕트를 개발/운영하고 있습니다. 이런 즐거운 고민을 함께하실 분은 언제든 채용 문을 두드려주세요!
]]>CaleyTypeScript 쓰면서 OpenAPI Generator 는 안 쓴다고?2022-04-07T00:00:00+00:002022-04-07T00:00:00+00:00https://tech.madup.com/openapi-generatorRESTful API 를 이용하는 프론트엔드 개발의 어려움
JavsScript 의 런타임에러가 프론트엔드 개발자들을 오랫동안 괴롭혀 온 것 같이, RESTful API 의 잘못된 사용으로 인한 런타임 오류는 프론트엔드 개발자들의 오랜 골칫거리였습니다. 어쩌면 여전히 많은 개발팀들이 가지고 있는 문제일지도 모르겠습니다.
특별히 API 의 잘못된 사용으로 인한 문제는 기본적으로 프론트엔드 개발자와 백엔드 개발자 사이의 정확하지 않은 커뮤니케이션으로 발생하는 문제로서 백엔드나 프론트엔드의 어떤 로직의 문제가 아니라 단순히 백엔드에서 원하고 기대했던 대로 프론트에서 데이터들을 전달하지 않았거나 프론트에서 원하고 기대하는 대로 백엔드가 데이터를 리턴해 주지 않을 때 발생하는 문제입니다. 이 문제는 서로 간의 추가적인 대화와 협의과정을 발생시키며 개발 비용의 상당 부분을 차지하게 됩니다.
API 앞에 선 TypeScript 의 무력감
그래도 우리에겐 TypeScript 가 있어서 다행입니다. TypeScript 를 이용해 API 의 스펙을 한땀 한땀 타입으로 정의해 두면 API 의 오사용을 많이 막을 수 있을 것입니다. 하지만 시간이 지나면 이마저도 여전히 녹록치 않게 됩니다. 처음에 준비된 API 가 10개 내외 정도라면 별로 문제가 되지 않을 것입니다. 하지만 슬슬 애플리케이션의 규모가 커지고 사용하는 API 들이 수십가지가 넘어가게 되면, 수많은 API 들의 입력과 출력을 한꺼번에 정의하는 것은 여간 귀찮고 힘든 일이 아닐 수 없습니다. 게다가 API 들의 스펙은 우리들의 바램과 달리 비즈니스 요건에 따라 잦은 변경이 발생하게 되며, 이를 정확하게 추적해 가며 일일이 해당 타입들을 재정의 하는 것은 거의 불가능에 가까운 일이 아닐 수 없습니다. 이런 상황 속에서 여러분들은 지금까지 어떻게 대응을 하고 있었나요? 수시로 변경되는 API 인터페이스 앞에서 떠나가는 버스를 바라보듯 그냥 any 타입을 남발하며 손놓고 지내고 있지는 않으셨는지요?
GraphQL 의 등장
GraphQL 은 바로 위와 같은 문제에 대한 근본적인 대안으로 등장하게 되었습니다. 위와 같은 문제로 고민하던 개발자들이 혹시 GraphQL 도입을 결정하고 GraphQL을 경험해 본다면 마치 천국 문이 열린 것 처럼 커다란 황홀함을 느끼게 될 것입니다. 그것은 마치 JavaScript 의 시도 때도 없이 터지는 런타임 에러에 회의감을 느끼던 개발자가 TypeScript 를 만나고 느끼는 희열과 비슷하다고 할 수 있을 것 같습니다.
사실 TypeScript 와 GraphQL 이 해결하는 문제는 비슷합니다. TypeScript 가 타입이 없는 JavaScript 에 정적 타이핑이라는 옷을 입게 해주는 것 같이, GraphQL 은 타입이 없는 API 가 강력한 타입 옷을 입게 해줍니다.
출처: University of Arizona/Heather Roper
무시할 수 없는 GraphQL의 진입장벽
요즘 개발 커뮤니티를 바라보면 프론트엔드 개발에서 TypeScript 의 위상은 지속적으로 견고해 지고 있는 것 같습니다. 하지만 GraphQL 의 성장세는 기대보다는 조금 더딘 것 같습니다. 그것은 아무래도 GraphQL 의 도입을 위한 진입장벽과 학습장벽이 제법 높기 때문이지 않을까요. 그것은 GraphQL 자체의 학습장벽 뿐만 아니라 GraphQL 의 도입은 개인이 홀로 할 수 있는 것이라기 보다 프론트엔드와 백엔드 개발자 사이의 그리고 여러 이해당사자들 간의 공감대와 협의가 필요하기 때문일 것입니다.
출처: https://brunch.co.kr/@realdude/12
또 다른 대안으로서 Swagger 와 OpenAPI Generator
이제야 제가 이 글을 쓰게 된 진짜 이유를 말할 때가 된 것 같습니다. GraphQL은 강력하지만 저는 GraphQL 을 소개하고 도입을 권장하기 위해 이 글을 시작한 것이 아닙니다. 앞서 이야기 드린 데로 현재 GraphQL을 사용하고 있지 않은 팀으로서 GraphQL을 갑자기 도입한다는 것이 얼마나 큰 비용과 리스크가 예상될 지를 잘 알고 있습니다. 이 글을 쓰는 진짜 목적은 RESTful API 를 기반으로 프로젝트를 진행하고 있는 개발팀에게 GraphQL 로의 전향적인 전환이 아니더라도 다소 진입장벽이 낮은 또 다른 대안이 있음을 공유하기 위함입니다.
그것은 바로 Swagger 와 OpenAPI Generator 의 도입인데요. 이제부터 Swagger 와 OpenAPI Generator 가 무엇인지 간단히 소개하고 프론트엔드에서 OpenAPI Generator 를 이용하여 API 의 인터페이스(타입)을 자동으로 생성하는 방법을 알아보고자 합니다. (백엔드에서 Swagger 를 설정하는 내용은 포함되지 않습니다.)
Swagger 와 OpenAPI Generator
Swagger 는 RESTful API 를 보다 편리하고 쉽게 그리고 일관되게 설계하고 개발하는 표준을 제안하고 관련된 자동화 도구들을 제공하는 오픈소스 프로젝트입니다. Swagger 에서 제안하는 RESTful API 표준을 OpenAPI Specification 라고 하고요 줄여서 OAS 라고 부릅니다. OAS 는 다양한 언어와 환경에서 사람과 컴퓨터가 모두 이해하기 쉬운 RESTful API 의 표준 인터페이스를 제안합니다.
그리고 Swagger 는 OAS 규격에 따라 API 를 개발하고 또 API 문서를 자동으로 생성하는 여러가지 도구들을 제공합니다.
OpenAPI Generator 는 Swagger 에서 제공하는 여러가지 자동화 도구들 중 하나입니다. OpenAPI Generator 는 OAS 에 따라 개발된 RESTful API 스펙을 기반으로 클라이언트에서 사용가능한 타입들을 자동으로 생성해 주는 도구입니다.
OAS 의 철학에 따라 OpenAPI Generator 도 다양한 언어와 환경을 모두 지원하지만. 본 문서에서는 특별히 프론트엔드 프로젝트에서 타입스크립트를 사용하는 경우에 한해서 Swagger 에서 제공하는 API 의 타입들을 자동 생성하는 방법에 대하여 간단하게 소개하고자 합니다.
이제 yarn openapi 명령을 수행하면 /models 폴더에 API 의 모델들이 아래와 같이 자동으로 생성됩니다. /models 폴더가 자동으로 생성되는 폴더인 만큼 .gitignore 파일에 /models 경로를 추가해 주는 것 또한 필요할 것 입니다. 필자는 해당 타입들(/models/src/model)이 생성되면 /src/model 경로로 자동복사가 되도록 설정하여 필요한 부분만 실제 코드에서 참조하여 사용을 하고 있습니다.
자동 생성된 API 입출력 관련 타입들
그리고 api 폴더에는 axios 기반의 API 별 호출함수 또한 자동으로 생성이 되는데요. 참고로 저는 개인적으로 이 부분은 프로젝트에서 그대로 사용하기에는 적합하지 않아서 직접 사용을 하고 있지는 않습니다.
자동 생성된 axios 기반 API 호출 함수
반면 자동으로 생성된 API 의 입력 및 출력 타입들을 아래와 같이 API 정의 시, 혹은 다른 필요한 곳에서 적절히 가져다 사용을 하고 있습니다.
API 호출 함수react-query 에서 데이터 타입 정의
주의사항
혹시 백엔드에서 enum 타입 정의시 한글을 사용할 경우 아래와 같이 생성된 모델에 오류가 있을 수 있으므로 주의가 필요합니다.
결론
프론트엔드에서 TypeScript 를 사용하고 있지만, 아직 Swagger 와 OpenAPI Generator 를 사용하고 있지 않다면 꼭 한번 사용해 보시기를 권장합니다. GraphQL 만큼 강력하지는 않더라도 Swagger 는 프론트엔드와 백엔드 개발자 사이의 API 스펙에 대한 커뮤니케이션을 매우 생산적이고 효과적으로 만들어 줄 것입니다. 그리고 OpenAPI Generator 를 이용해 모든 API 의 입출력 타입을 자동생성한다면 API 의 변경을 빠르게 확인하고 프론트에서 API 오사용으로 인한 문제들을 획기적으로 줄여줄 수 있을 것 입니다.
]]>keating선형 모델과 회귀분석의 직관적 이해 (1)2022-04-05T00:00:00+00:002022-04-05T00:00:00+00:00https://tech.madup.com/linear-model-in-statistics-1
18세기 말 인류 최고의 수학자 가우스가 정규분포와 최소제곱법을 만든 이후로, 선형 모델(Linear Model)은 다양한 방향으로 진화했고 발전해왔다.
20세기 이후 컴퓨터 계산과 모델링 기법의 발전에 힘입어, 소위 말하는 “빅데이터” 시대에 복잡한 계산까지 해줄 수 있는 “머신러닝”, ”딥러닝”이 각광을 받고 있다.
데이터 분석가나 데이터 사이언티스트가 되고 싶은, 혹은 이미 현업에 있는 분들의 상당수가 머신러닝, 딥러닝에 열광하고 이를 적극적으로 활용하지만, 선형 모델과 회귀분석에 대해서는 그저 “단순한 것”, “올드 스쿨(Old School)”로 여기는 경향이 많다.
그러나, 220년이 넘도록 선형 모델의 중요성은 이 순간에도 변하지 않았다. 딥러닝을 포함한 모든 최신 기법들은 하늘에서 갑자기 뚝 떨어진 것이 아니다. 이들은 선형 모델에 적당한 커널(Kernel)을 사용해 비선형으로 매핑하거나, Tree Model과 같이 직선으로 파티션을 나눠 비선형 패턴을 만드는, 결국 선형 모델에 트릭을 써서 일반화한 것에 지나지 않기 때문이다. 따라서 비선형 모델링을 잘 하기 위해서는 선형 모델 및, 대표 분석법인 ‘회귀분석’에 대한 이해가 필수적이다.
향후 기회가 될 때마다 데이터 사이언티스트들이 필수적으로 알아야 할 “선형 모델”과 “머신러닝” 기법들에 대해, 개념이나 코드 예제보다는 핵심을 찌를 수 있는 “직관” 위주로 글을 투고하려 한다.
첫 번째 글에서는 “선형 모델”이 무엇인지 살펴보고, 선형 모델을 다루는 대표적인 분석법인 “선형 회귀분석(Linear Regression Analysis)”의 필요성에 대해 소개하겠다.
눈치가 빠른 사람들은 짐작했겠지만, 가장 마지막 (6)을 제외한 (1) ~ (5)는 모두 선형 or 선형으로 변환 가능한 모델이다. 다수는 (1)이 선형이라는 것에는 공감을 하지만, (2) ~ (5)가 선형이라는 것에는 고개를 갸우뚱할 수도 있을 것 같다.
여기에서 선형 모델의 정의에 대해 짚고 넘어가자.
[모델의 선형성]
모델이 “선형(Linear)”이라는 것은, 추정해야 할 파라미터(Parameter)에 대해 “선형변환”을 만족시키는 것으로 정의한다. 이 때, 내가 가지고 있는 변수(Variable)들은 꼭 일차식일 필요가 없다.
[선형변환]
실변수 벡터공간(Vector Space)에서, 벡터 X, Y와 스칼라 a에 대해 다음을 만족하는 함수 T를 선형변환(Linear Transformation)으로 정의한다.
$T(aX + Y) = aT(X) + T(Y)$
여기에서 벡터 X, Y를 각각의 식으로 분리해 계산할 수 있는 성질을 “가산성(Additivity)”이라 하고, 스칼라 a를 식 밖으로 분리할 수 있는 성질을 “동질성(Homogeneity)”이라 한다.
(1)이 선형성을 만족시키는 것은 자명하다. 이는 “다중 선형회귀모델(Multiple Linear Regression Model)”을 나타낸 식이며 다음 글에서 언급할 기회가 있을 것이다.
흔히들, (2)의 경우는 제곱 및 세제곱 항까지 사용했는데 왜 “비선형”이 아니냐고 오해한다. 다시 정리하자면, 모델이 “선형”인지 “비선형”인지는 우리가 추정해야 할 “파라미터”가 일차식인지 확인하면 된다. $\beta$ 값들은 전부 일차식이고, 따라서 이는 변수 벡터 $[1, x, x^2, x^3]$의 선형결합(Linear Combination) 형태로 나타낼 수 있으므로 선형이다. 마찬가지로, 모든 다항식 모델은 “$a * x^{n} + b * x^{n-1} + … + q * x + r * 1$” 꼴로 나타낼 수 있으므로 “선형”이다.
머신러닝에 대해 처음 배우면 가장 먼저 보게 될 그래프 중 하나다. 많은 사람들을 낚았다…
위 그림의 Overfit 케이스도 선형 모델로 나타낼 수 있을까? 정답은 “그렇다”이다.
우리가 중, 고등 수학에서 미지수가 n개인 방정식을 맞추기 위해서는 n개의 식이 필요함을 이미 배웠다. 이에 따라 두 점만 있으면 직선으로 연결할 수 있고, 세 점은 이차함수, 네 점은 삼차함수, … 결정적으로 n-1차 다항식으로 모델링을 하면 n개의 점을 100% 완벽하게 맞출 수 있다.
(물론 이렇게 모델링을 하면 bias는 0으로 만들 수 있어도, variance가 매우 커지게 되어 MSE(Mean Squared Error) 관점에서는 좋지 못한 모델일 것이다.)
$MSE = bias^{2} + variance$
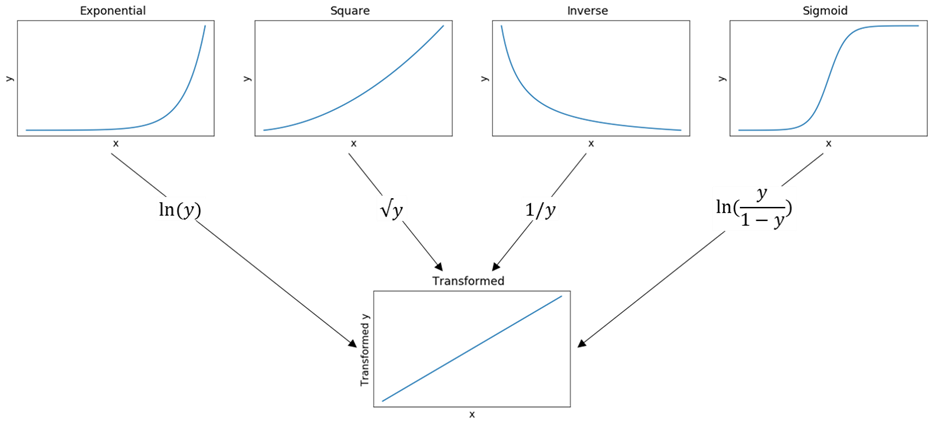
(3)의 경우 겉보기에는 맞춰야 할 파라미터 $\theta$가 지수 꼴로 나타나 있어 비선형으로 보인다. 그러나 양변에 로그를 취하면 $\log(y_{i}) = \log(\theta_{1}) + \theta_{2}x_{i} + \log(\epsilon_{i}) = \beta_{0} + \beta_{1}x_{i} + \epsilon_{i}^{*}$과 같은 식이 되어 변수 벡터 $[1, x]$을 이용해 $\log(y)$를 추정하는 식으로 변형할 수 있다.
(4)의 경우도 마찬가지다. 분모와 분자에 역수를 취하는 트릭을 사용하면, $\frac{1}{f(x, \theta)} = \frac{x_{i} + \theta_{2}}{\theta_{1}x_{i}} = \frac{1}{\theta_{1}} + \frac{\theta_{2}}{\theta_{1}}\frac{1}{x_{i}} = \beta_{0} + \beta_{1}x_{i}$ 식과 같이 선형 꼴로 정리가 가능하다.
(5)는 미분 연산자가 들어가 있는데 왜 선형일까? 놀랍게도 미분과 적분 연산자 또한 선형변환의 성질을 만족시킨다. (고등학교 때 상수항을 미적분 기호 밖으로 자유자재로 빼거나, 두 식들을 따로 분리해서 쉽게 계산을 한 경험이 있을 것이다.)
위 식은 미분방정식에서 가장 쉬운 예시로, 식을 정리하면 (3)과 유사한 지수함수 형태로 정리되어 (3)과 마찬가지로 선형으로 변환이 가능하다.
엄밀하게는 (3) ~ (5) 식은 그 자체로 선형이 아니지만, 간단한 트릭을 사용하면 선형 모델처럼 취급이 가능하다는 뜻에서 “본질적으로 선형인(Intrinsically Linear)” 모델이라고 한다.
항상 참은 아니지만, 선형화가 가능할 경우 선형으로 모델을 변환하면, 아래에서 언급할 선형 모델의 많은 장점을 활용할 수 있어 유리하다.
적절한 트릭을 쓰면 비선형으로 보이는 모델도 선형으로 변환할 수 있다.
(6)은 머신러닝 모델인 서포트 벡터 머신(Support Vector Machine)에서 Gaussian Kernel을 사용한 형태로 대표적 비선형 모델 중 하나다. 추후 머신러닝 모델들에 대해 얘기할 때 중요하게 다룰 것이다.
선형 모델의 장점
선형변환의 대표 성질인 가산성과 동질성을 만족시키는 선형 모델은 매우 중요하다.
복잡한 모델을 쉬운 계산들로 분해할 수 있다: 단순한 변수들의 합과 상수배만으로, 모델들을 기초적으로 분리해 따로 계산이 가능하다. 이러한 특징을 이용해 선형의 특징을 살리면 “계산이 매우 편리하다”.
모델의 해석이 쉽고 직관적이다: 선형변환의 특징 중 “동질성”을 생각해보자. 단순히 변수 x가 a배가 되면, 결과도 a배만큼 커진다. 우리는 선형 모델에서 변수에 multiplier 역할을 하는 파라미터에 관심이 있다. 가령 “내가 광고비를 2배만큼 증액했을 때, 신규 설치는 얼마나 증가할까?”와 같이 내가 집어넣은 변수의 효과의 크기에 관심이 있거나, 혹은 “페이스북 메신저 지면에 광고를 하는 것은 효율에 긍정적일까, 부정적일까?”와 같이 의사결정을 위해 효과의 부호에 관심이 있을 수 있다. 선형 모델을 통해 파라미터를 도출하면 파라미터를 그대로 해석할 수 있기 때문에 모델이 매우 간단하다. ($\frac{\partial y}{\partial \beta_{i}} = c$와 같이 상수로 도출됨을 생각해보자. “뿌린 만큼 거둔다”의 원리가 선형 모델에 숨어있다.)
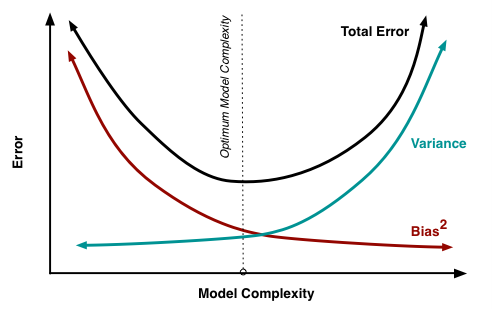
복잡한 패턴을 요구하지 않는 데이터에서 견고(Robust)한 추정이 가능하다: 항상 그렇지는 않지만 (선형 모델에서도 얼마든지 변수에 다항식, Kernel 트릭을 가해 직선이 아닌 “곡선”을 만들 수 있으므로), 일반적으로 복잡한 패턴을 다루기 위해 사용하는 비선형 모델 대비, 선형 모델을 잘 쓰면 오버피팅(Overfitting ; 미래 데이터를 잘 맞추지 못하는 것)을 방지하고 파라미터 및 예측값에 대해 “견고한 추정”을 할 수 있다.
머신러닝에서 강조하는 MSE 분해 식에서도, $bias^{2}$와 $variance$를 동시에 고려하는 것이 중요하다는 것을 보여주고 있다. 꼭 비선형 모델을 써야 하는 데이터가 아닌 이상, 비선형 모델을 무분별하게 쓰는 것은 추정의 variance를 지나치게 높여 MSE를 망치게 하는 원인이 된다. (그렇다고 선형 모델이 bias를 0으로 만들지 못하는 것도 아니다)
이와 같이 선형 모델은 최소 계산비용(Computational Cost)이 비선형 모델 대비 매우 우수하다는 장점이 있고, 더 나아가 특정 조건을 만족할 경우 비선형 모델을 포함해 “가장 좋은” 모델이 될 수도 있는 잠재력도 가지고 있다. 앞으로 선형 모델의 대표적인 분석 기법인 “선형 회귀(Linear Regression)”에서 이를 언급할 것이다.
아마 다들 자연스럽게 “데이터의 개수는 15개, 클릭 수의 평균은 54.7건” 이라고 생각했을 것이다. 이처럼 우리가 평균을 바탕으로 데이터를 요약하고 예측하는 것은 매우 자연스럽다.
새로운 캠페인을 세팅해 클릭 수를 예측해야 한다고 하자. 현재 아무 정보가 없는 상태에서, 새로운 캠페인에서 기대할 수 있는 클릭은 몇 건이라고 생각하는 것이 합리적일까? 지금까지 가지고 있는 정보로는 클릭 수의 평균이 54.7건이었으므로, 새 캠페인의 클릭 수도 약 54.7건이지 않을까? 라고 예측하는 것이 가장 합리적일 것이다.
다들 눈치챘겠지만, 이는 좋은 예측이 아니다. 아무 정보도 없는 상태에서도 누구나 예측할 수 있는, “그나마 최선” 인 숫자인 것이다.
이 “단순 찍기” 모델이 얼마나 못 맞췄는지 측정하기 위해, 맞추지 못한 만큼인 “잔차(Residual)”의 분산을 구해보자. 표본분산 공식 = $\frac{1}{(n-1)}(\epsilon_{i} - E(\epsilon_{i}))^{2}$에 값을 대입하면 약 855.24라는 값이 나온다.
우리는 고등학교에서 변수 x에 적당한 숫자 a를 더하더라도, x의 분산과 (x + a)의 분산은 같다는 것을 배웠다. 우리가 값을 “상수” 값으로만 추정했기 때문에, “단순 찍기” 모델의 분산은 데이터 자체의 분산과 같은 것이다.
잔차의 분산은 우리가 예측하지 못한 “불확실성”이나 다름없다. 모든 통계적 데이터 분석의 목표는 불확실성으로 대표되는, 바로 이 분산을 줄이는 것이다. 에러의 분산을 줄여 좀 더 데이터를 잘 맞추려면 어떻게 해야할까? 데이터를 설명할 수 있는 “정보”가 필요하다.
만약 더미변수(Dummy Variable)로 “레버를 활용한 캠페인”은 T, 그렇지 않으면 F인 정보가 추가로 주어졌다고 하자. 이 변수에 대한 벡터 $X = [T, T, T, F, F, T, F, F, T, F, F, F, F, T, F]$ 라면 이 정보를 활용해 데이터를 조금 더 잘 설명할 수 있다.
두 그룹으로 데이터를 구분해 각각의 평균을 선으로 나타냈다.
“레버 마케팅 유무” 라는 정보에 따라, 각각의 조건부 기댓값(Conditional Expectation)을 계산하였다. 이를 통해 예측한 클릭 수는, 레버 마케팅을 적용한 캠페인은 “평균 68.6건(파란 선)”, 그렇지 않으면 “평균 42.5건(붉은 선)”으로 나타난다. 이는 무정보일 때였을 때 대충 예측한 “54.7건”보다 정확하다.
데이터 분석가, 또는 퍼포먼스 마케터라면, 누구나 엑셀에서 “피벗 테이블”이라는 멋진 기능을 사용해본 경험이 있을 것이다. 그렇다면 피벗 테이블은 왜 쓰는가? 우리는 피벗 테이블에서 성과를 분석할 때 왜 “세그먼트” 단위로 조건들을 나누어 성과를 분리해 측정하는가?
우리는 감각적으로 “세그먼트를 나누어” 성과를 분석하는 것이 더 정확함을 알고 있기 때문이다.
여기서 조건부 분산에 대한 주요 성질을 짚고 가자. 조건부 분산은 아래와 같이 분해가 가능하다.
[조건부 분산의 분해]
변수 $Y, Z$에 대해, $V(Y) = E(V(Y|Z)) + V(E(Y|Z))$가 성립한다.
그런데 분산은 항상 0 이상의 값이므로, 어떤 변수 $Z$가 주어져 $E(Y|Z)$를 계산할 수 있다면, $V(Y|Z)$는 0 이상이므로 $E(V(Y|Z))$ 역시 양수이고, 따라서 $V(E(Y|Z))$는 $V(Y)$보다 작거나 같은 값을 가진다. 결국 $E(E(Y|Z))$는 이중 기댓값 정리(Law of Iterated Expectation)에 의해 $E(Y)$와 같으므로, $E(Y|Z)$는 $E(Y)$와 평균은 같으면서, 분산은 더 작은 좋은 추정량이 된다.
이에 대해 조금 더 상세하게 알고 싶다면 Rao-Blackwell Theorem을 참조하면 된다. 내용은 어렵지만, 정리의 핵심은 파라미터를 잘 추정할 수 있는 “정보”가 주어진다면, “정보”를 조건으로 활용해 조건부 기댓값을 구하는 것이 분산(불확실성)을 줄여주므로 더 합리적이라는 것이다.
실제로 “레버 마케팅 유무”였던 $X$를 정보로 걸었을 때, 잔차의 분산은 673.98로, 무정보 상태에서 단순 평균으로 예측했을 때 잔차의 분산인 855.24 대비 78.8% 수준으로 약 21.2% 개선된 것을 확인할 수 있다. 추후 잔차 분산의 개선율 0.212에 대해 다시 언급할 기회가 있을 것이다.
이처럼 데이터를 설명하거나 예측할 때, 정보 $X$를 바탕으로 한 합리적인 조건부 기댓값(평균)을 구하는 기법을 “회귀분석(Regression Analysis)”이라 한다.
마치며
지금까지 선형 모델의 정의와 회귀분석의 당위성에 대해 알아보았다. 모든 모델과 분석법은 갑자기 태어난 것이 아니라, 쉬운 것에서부터 점차 필요에 의해 발전하며 탄생하였다.
다음 글에서는 다소 어려울 수 있지만, 회귀분석 추정법 및 성질에 대해 다루도록 하겠다.
]]>ronaldRedshift DW에서 PG DM을 만드는 여정2022-04-01T00:00:00+00:002022-04-01T00:00:00+00:00https://tech.madup.com/data-mart-1Redshift to PG Data Convenience Store
개요
매드업은 레버에 안정적으로 데이터를 공급하고 광고사업부에게 데이터를 공급하기 위하여 AWS S3에 데이터를 적재합니다. 완전한 raw data 는 아니지만, 각 매체(Facebook, Google 등) 에서 주는 데이터를 그대로 적재 합니다. 그리고 지금까지 이 S3 파일들을 Athena 라는 서비스로 쿼리하여 사용하였습니다.
하지만 Athena가 비용 대비 속도도 느리고 그 쿼리를 람다로 수행하는데 그 람다 역시 쿼리 시간 내내 떠있어야 하는 등 비용적 그리고 효율적인 측면에서 매우 불리했습니다. 그래서, 그 이름도 찬란한 Prism 프로젝트가 태어났습니다. Redshift 서비스를 이용해서 Data Warehouse를 멋지게 구현 해 냈습니다.
이후 우리는 점차 S3 + Athena 조합을 역사의 뒤안길로 보내면서 Redshift 에 붙어 바로 쿼리를 해서 데이터를 수집하는 것을 시작 합니다.
빨간맛 이었던 Redshift와의 첫만남
그렇게 Develop Redshift 에서 쿼리를 해보고 운영으로 Deploy를 했습니다.
그때는 바야흐로, 저녁 늦은 시간.
우선, Redshift 는 PostgreSQL 을 포크하여 구글의 빅쿼리에 버금 가도록 AWS 에서 직접 튜닝하여 제공하고 있는 대용량 데이터 베이스 입니다. 그래서 멋들어지게 여러 테이블을 조인 해서 쿼리를 보았고, 운영 환경의 Redshift에서도 당연히 평균이상의 속도는 보이지 않을까 하는 생각을 했습니다.
쿼리 속도도 속도지만, 레드 시프트는 Hash 조인을 하면서 CPU를 사용량이 높아졌고 이로 인해 Redshift는 스스로를 지키기 위해 Session을 끊어내고 있었습니다.
Redshift의 힘겨워 하는 모습
Explain으로 살펴보니 열심히 Hash Join 하여 여러 테이블의 데이터를 잘 서빙하기 위해 레드시프트는 노력하고 있었습니다.
그렇다면 Hash Join은 무엇인가? 왜 우리는 이것을 사용하는가?
사실 Hash Join이 말이 어려워서 그럴듯해 보이는 것이지 사실 조인 기법 중 하나 입니다. Merge Join이 대세였던 시절, 메모리가 한정적이기 때문에 DB가 테이블을 조인하면서 임시로 Disk에 써두었어야만 했었습니다.
그 Disk I/O 가 느리니, Hash Join이 생겼습니다. Join 되는 테이블과 비교하여 해쉬 함수 값에 의해 짝을 이루고 두 테이블 중 작은 테이블이 메모리에 적재 됩니다. 그리고 큰 테이블을 읽어가며 비교합니다. 대부분의 경우 CPU 자원이 넘치기 때문에 해시조인이 유리한 경우가 많은데, 과연 우리에게도 잘 어울리는 것인가, 의문을 가졌습다…. 만!?
결과는 그렇다 입니다. Redshift는 대용량 데이터베이스 답게 분산키, 정렬키 지정이 쉽지 않습니다. 이때 테이블끼리 조인을 할때 이 연결되는 연결고리 (a.client_id = b.client_id 같은) 에 인덱스가 처리되어 있지 않으면 Hash Join이 대부분의 상황에서 유리하기 때문입니다.
아무튼, 개발환경 Redshift에서 하던대로 아무생각 없이 비교적 많은 데이터가 있던 Redshift에게 너무 힘든일을 시켰습니다. 우리는 개발자이니, 우선 상황을 한번 봐야 겠다는 생각이 들어 같은 내용을 가지고 올수 있는 쿼리를 만들어 EXPLAIN으로 살펴보았습니다.
조인해서 가지고 오는 경우의 EXPLAIN
XNHashJoinDS_DIST_NONE(cost=38237.07..156530.04rows=1width=266)" Hash Cond: (((""outer"".ad_set_id)::text = (""inner"".ad_set_id)::text) AND ((""outer"".account_id)::text = (""inner"".account_id)::text) AND (""outer"".collected_at = ""inner"".collected_at))"->XNSeqScanonfacebook_adfa(cost=0.00..118274.62rows=489width=147)Filter:(('2022-01-11'::date=collected_at)AND('597060991453466'::text=(account_id)::text)AND(account_idISNOTNULL))->XNHash(cost=38237.07..38237.07rows=1width=189)->XNHashJoinDS_DIST_NONE(cost=5894.48..38237.07rows=1width=189)" Hash Cond: (((""outer"".campaign_id)::text = (""inner"".campaign_id)::text) AND ((""outer"".account_id)::text = (""inner"".account_id)::text) AND (""outer"".collected_at = ""inner"".collected_at))"->XNSeqScanonfacebook_ad_setfas(cost=0.00..32241.10rows=410width=120)Filter:(('2022-01-11'::date=collected_at)AND('597060991453466'::text=(account_id)::text)AND(account_idISNOTNULL))->XNHash(cost=5894.41..5894.41rows=8width=108)->XNSeqScanonfacebook_campaignfc(cost=0.00..5894.41rows=8width=108)Filter:(((account_id)::text='597060991453466'::text)AND(collected_at='2022-01-11'::date))
가장 확실한 방법은 데이터마트를 중간에 두는 방법이었습니다. 이것은 확실하지만, 많은 공수가 들었고 당장 해결해 낼 수는 없는 것이기도 했습니다. 하지만, 임시방편 보다는 장기적으로 지속가능한 방법으로 해결해보라는 준(CTO)의 이야기에 바로 시작했습니다.
요구사항?
Redshift Spectrum 에는 파티셔닝이란 개념이 있지만, Redshift에는 그런게 없습니다. 그래서 마트를 만들면 우선 월별로 파티셔닝을 하고 싶었습니다. 이 것을 한다 하더라도 전혀 쿼리가 변경되지 않습니다.
레버(lever.me) 광고주의 데이터가 아닌 내용들은 쿼리 스캐닝 범위에 포함시키고 싶지 않아서 적재하고 싶지 않았습니다.
Redshift가 데이터를 적재하는 빈도와 주기에 맞추어 Redshift에서 우리가 사용하는 데이터만 “슬쩍” 훔처서 달아나고 싶었습니다.
혹시 필요하면 그때그때 DW에서 데이터를 가지고 오고 싶었습니다.
외래키 조인은 아니더라도 복합인덱스를 이용한 조인을 용이하게 하고 싶었으며, 필요하면 추가 인덱스도 만들고 싶었습니다.
Rest API 로 외부에 데이터를 송출할 수 있도록 하고 싶었습니다.
Redshift도 실시간으로 매체와 동기화 되지 않기 때문에 즉시 수집 기능이 있습니다. 즉시 수집을 요청하고 결과 콜백을 주는데 그 콜백을 받아주는 API를 이 이 서버 두어 그때그때 해당 내용을 수집하고 싶었습니다.
이 정도의 요구사항들을 수집했습니다.
이제 피버타임.
무조건 시간을 맞추어 끝내야 하는 것은 아니지만, 레버가 자랑하는 기능 중 ‘주간리포트’를 제대로 사용할 수 없는 지금 이 시간을 최대한 줄여야만 했습니다. 가장 중요한 것은 데이터를 잘 적재 하면서 데이터를 잘 조회 되도록 하는 것 입니다.
그리고 고민을 했습니다.
우리가 Redshift에서 필요한 데이터는 일주일에 약 10~11GB 입니다. 점점 늘어날 것 입니다. 이 데이터를 어떻게 가지고 오지?
Data Mart DB ↔︎ 서버 ↔︎ Redshift
하루 1GB 데이터를 가지고 온다고 하면 서버에서 Redshift로 요청하고 다시 DB로..
쿼리 실행 시간보다, fetching 시간이 길수도 있겠다고 생각했습니다. 그리고 해당 데이터를 메모리에 올려두고 써야 하는 것도 부담이었습니다. 물론 요청할때마다 수 GB 씩 fetching 하는 것은 아니지만, 분명 그럴 일이 나중에 있을 것이라 생각했습니다.
DB LINK Redshift ↔︎ PostgreSQL(DATA MART) by Procedure
Stored Procedure 를 만들어 DB 링크로 데이터를 빨아드리는 방법이 좋겠다는 생각이 들었습니다.
수백만 로우를 가지고 오는데 1분 정도면 충분했습니다. 프로시저는 그 프로시저 만의 단점들이 있지만, 극복 가능한 단점이라고 생각이 들었습니다.
프로시저의 단점
우리 프로시저는 매우 단순했지만, 모든 액션이 반드시 성공한다는 보장은 없습니다. 프로시저는 어디서 오류가 났는지, 무슨 에러 중인지 알기가 쉽지 않습니다. 그래서 최대한 짧게 짧게 프로시저를 여러개 만드는 것을 고민 했습니다.
그래서 우리가 레드시프트와 동기화 해야 하는 테이블을 8가지 섹션으로 분류했습니다.
Facebook
Metric Section
페이스북 광고 리포트
페이스북 액션 리포트
페이스북 액션 가치 리포트
페이스북 사용자 일별 리포트
Resource Section
페이스북 캠페인
페이스북 광고 세트
페이스북 광고
페이스북 광고 소재
광고 소재 Many to Many Relations
페이스북 에셋
Google
Metric Section
구글 광고 그룹 리포트
구글 캠페인 리포트
구글 키워드 리포트
구글 키워드 전환 리포트
Resource Section
구글 캠페인
구글 광고그룹
구글 광고
구글 미디어 파일
구글 소재
Naver
Metric Section
네이버 광고 리포트
네이버 광고 전환 리포트
네이버 캠페인 리포트
네이버 광고 그룹 리포트
네이버 키워드 리포트
네이버 광고 전환 리포트
네이버 쇼핑 상품 리포트
Resource Section
네이버 캠페인
네이버 광고그룹
네이버 광고
Kakao
Metric Section
카카오 에셋 리포트
Resource Section
카카오 캠페인
카카오 광고 그룹
카카오 에셋
각 매체당 2개씩 총 8개의 섹션 입니다.
DBLINK를 만들어 줍니다.
CREATEEXTENSIONpostgres_fdw;CREATEEXTENSIONdblink;CREATESERVERredshift_prdFOREIGNDATAWRAPPERpostgres_fdw-- 매드업엔 SSH터널링 툴인 매드터널이 있는데 여기는 진짜 Redshift Private IP 를 넣어줍니다.OPTIONS(host'<amazon_redshift _ip>',port'<port>',dbname'<database_name>',sslmode'require');
편의점이냐.. 마트이냐..?
Data Mart를 구축하려고 했는데 편의점을 구축해야.. 하지 않을까? 테이블안에 컬럼이 너무 많습니다. 하지만, 필요한 컬럼만을 추릴려고 하니, 나중에 다시 필요해 졌을때 테이블 구조를 변경하거나, 프로시저를 변경하기 쉽지 않을 것 같아서, 우선 다 수집하기로 했습니다. DB Link 쿼리는 DB 입장에서 보면 나한테 메타데이터가 없는 테이블을 쿼리하는 것이고 이렇다면 일일히 다 쿼리 하는 컬럼의 데이터 타입을 지정해야 합니다.
아래와 같이요.
SELECT*FROMdblink('redshift_prd',$REDSHIFT$SELECTsellerid,sum(pricepaid)salesFROMsalesWHEREsaletime>='2008-01-01'ANDsaletime<'2008-02-01'GROUPBYselleridORDERBYsalesDESC$REDSHIFT$)-- 여기 아래 정의 해줘야 합니다. 우리 코끼리DB는 Redshift에 어떤내용이 정의된지 모릅니다.ASt1(selleridint,salesdecimal);
수십개나 되는 컬럼에 일일히 이 프로시저를 만들 수가 없기 때문에 파이썬 파일로 프로시저를 자동으로 생성해주는 코드를 만들어 보기로 합니다. 그렇다면 나중에 내가 없어도 이 파일로 수정할 수 있으니까요.
엔지니어는 기본적으로 내가 지금 죽고 없어져도 유지되는 시스템을 만들어야 한다고 생각하니, 유지보수 할 수 있도록 프로시저 제너레이터를 만들었습니다.
기본 개념은 다음과 같습니다.
데이터베이스(데이터마트) 를 Redshift 와 동일하게 스키마를 만들어 줍니다.
Redshift는 매체에서 주는대로 저장하기 때문에 컬럼 이름에 .(period) 가 들어갈 수 있지만, 저희는 전부 그것을 _(underscore)로변환 했습니다.
우리 Database metadata를 기준으로 어떤 컬럼이 어떤 데이터 타입을 가지는지 이제 우리는 알 수 있습니다.
모델 파일에 있는 모든 클래스를 불러옵니다.
그리고 그 클래스로 가서 어떤 컬럼이 있고 어떤 데이터 타입을 가지는지 확인합니다.
그렇게 쿼리를 statement를 만듭니다.
forexcininspect.getmembers(m,inspect.isclass):ifexc[0].endswith("DM")andexc[0]notinFACEBOOK_EXCEPT:ifgetattr(m,exc[0]).__table__.nameincreate_target.get(target):vars.append(exc[0])preassigned_kwarg=["end","enable"]redshift_query_stmt=""forvinvars:model=getattr(m,v)columns=[c.nameforcinmodel.__table__.columnsifc.namenotin["created_at","updated_at","id"]]fori,col_inenumerate(columns):ifcol_inpreassigned_kwarg:columns[i]=f""""{col_}" {col_+"ed"}"""redshift_query_stmt+=f"""
{v.lower()}_remote_sql = format('
SELECT {", ".join(columns)}
FROM {model.__table__.name.removesuffix("_dm")}
WHERE collected_at >= %L
and collected_at <= %L
and {account_idif'all'notinmodel.__table__.nameornottarget.startswith("naver")else'customerid'} in (%s)
', start_date_string, end_date_string, ids);
"""
preassigned_kwarg 는 Redshift, 또는 PostgreSQL 에서 사전 정의된 키워드 입니다. end 같은 것은 컬럼이름으로 사용할 수 있지만, “end” 이렇게 쿼리 해줘야 합니다. 왜냐하면 SQL 언어이기 때문입니다. 저런 소소한 ETL을 타이트하게 해줍니다.
CREATEORREPLACEPROCEDURErs_{target}_dumps(account_idsvarchardefault'0',start_datevarchardefaultnull,end_datevarchardefaultnull)languageplpgsqlas$$declareirecord;declarekrecord;declarestart_date_stringtext;declareend_date_stringtext;declareidstext;{declare}beginids:='';IFaccount_ids='0'THENraisenotice'is 0';-- 0일땐 모든 광고계정 모두! 현재 페이스북 기준 약 400여개 하지만 Redshift에는 -- Lever 에서만 광고하는 광고주만 계신 것이 아니기에 조회할 것만 뽑아서 스트링으로 만들어줍니다.FORkin(SELECTdistinct{account_id}from{account_table})LOOPIFLENGTH(ids)=0THEN-- '12345', '12347', '12399' 이런 형태로 만드는 작업입니다.ids=concat('''',k.{account_id},'''');ELSEids=concat(ids,', ','''',k.{account_id},'''');endif;endloop;ELSEFORkin(SELECTdistinct{account_id}from{account_table}where{account_id}in(SELECTaccount_idFROMunnest(string_to_array(account_ids,','))account_id)))LOOPIFLENGTH(ids)=0THENids=concat('''',k.{account_id},'''');ELSEids=concat(ids,', ','''',k.{account_id},'''');endif;endloop;endif;IFend_dateisnullthenend_date_string=to_char(now(),'YYYY-MM-DD');elseend_date_string=end_date;endif;IFstart_dateisnullthenstart_date_string=to_char(now()-INTERVAL'{days} DAY','YYYY-MM-DD');elsestart_date_string=start_date;endif;
위에 보시면 {target}{declare} {account_id} {account_table} {days} 이렇게 5개가 Python f string 완성을 위해 이렇게 정의 되어 있습니다. 맞습니다. 위 프로시저 도입부는 변수에 따라 자동으로 작성되는 f string입니다.
target 프로시저의 고유의 이름을 만들기 위한 변수 입니다.
declare 부분에는 프로시저에서 사용할 변수 이름등이 정의되고
account_id 는 각각 매체마다 사용하는 광고계정 이름을 사용합니다. 카카오와 페이스북은 account_id, 구글과 네이버는 customer_id 라는 이름을 사용합니다.
account_table은 각 광고계정이 적재된 데이터마트 DB에 있는 테이블 이름입니다.
days는 start_date와 end_date를 둘다 넣지 않았을 경우 기본 몇일을 수집하게 될 프로시저를 만드는가를 결정하는 변수 입니다.
그리고 저는 account_ids에 “1234,4567” 이렇게 오면 1234 와 4567 광고계정만을 검색하고 싶고, 수집하는 시작일과 종료일도 설정하고 싶습니다. 그래서 변수로 account_ids 와 start_date와 end_date를 받아줍니다.
이렇게 해서 DM 에 정의된 SQLAlchemy 모델에 정의된 컬럼 이름만으로 Redshift 컬럼 이름을 찾을 수 있었습니다. Redshift 에 접근해서 메타데이터를 받아 올수도 있는데, 쿼리를 해야 함은 물론, 받은 계정에 그곳에 접근 가능한 Access Clearance가 없었기에 이렇게 구현해 냈습니다.
sync_query_stmt+=f"""
raise notice '% has started', '{model.__table__.name}';
FOR i in SELECT
*
FROM dblink('redshift_prd', {v.lower()}_remote_sql)
AS t1 (
{",".join(["".join(x.split("")[-2:]) for x in map_])}
)
LOOP
INSERT INTO
{model.__table__.name}
(
created_at,
updated_at,
{",".join(dm_name)}
)
VALUES (
current_timestamp,
current_timestamp,
{",".join(['i.' + k[0] for k in dw_name])}
);
end loop;
"""
위는 DBLink로 Redshift로 보내는 쿼리를 생성하는 부분 입니다.
여기 까지 오는데 사전 작업을 완전 빡세게 한 이유는, Redshift에 쿼리하는 그 쿼리 스테이트먼트 안에 데이터마트 테이블 레코드를 참조 할 수 없었습니다. 이게 Redshift table인지 PostgreSQL table인지 구별을 하지 못합니다. 그래서 사전작업으로 계정 ID 들도 날짜도 text 형태로 다 가공했습니다.
스캐줄러를 만들어 호출
이건 어디서 어떻게 스캐줄러를 만들어 호출해도 좋습니다. 앱에서 해도 되고, 람다로 해도 되고, 무엇으로든 하면 됩니다.
우선 Metrics를 서빙할 앱에 스캐줄러를 구현했습니다.
아래와 같은 Scheduled Job을 정의하고 스캐줄을 관리할 테이블을 만듭니다.
Scheduler(Job)을 관리하기 위한 스키마 구조
과거에 람다로 Job을 관리할 때도 비슷한 테이블이 있었는데 운영을 하다보니, 지금 수행중인 프로세스를 제외하고 새로 시작하는 모든 Job을 중지하고 싶은 Needs가 있었습니다. 그래서 job_runner 테이블을 만들어서 관리하기로 했습니다.
job_type과 job_status는 Enum이지만, 데이터베이스 native enum은 Fail Point를 늘리기 때문에 사용하지 않았습니다. 이제 스캐줄러를 만들고 드디어 대망의 자동 수집을 시작합니다.
뜻 밖에 복병
사실 8개의 섹션으로 나눈 본능적인 이유에는 프로시저를 작게 쪼갠다는 의미가 가장 큽니다. 작게 쪼개야 한 번에 실행하는 시간도 짧아집니다. 짧아져야, 데이터마트 DB 세션도 너무 길게 잡고 있지 않고, Redshift 에도 우리가 왔다갔다는 흔적이 덜 남게 되기 때문입니다. 하지만, 그 모든 예상을 차치하고, 이것이 신의 한 수가 되는 순간이 여기서 옵니다.
스캐줄을 마구마구 등록해 시작해보니, 서로서로 ShareUpdateExclusiveLock을 걸어 물고 물리는 대전이 일어났습니다.
Facebook Metrics 수집 중에 Google Metrics 수집은 가능하지만, 또 다른 Facebook Metrics 수집은 못하게 막았습니다. 현재 매 시간 1번씩 수행되는 Job이 처리되는 시간은 아래와 같습니다.
하나의 스캐줄러는 얼마나 걸릴까요?
23시경이라고 적었습니다. 하루의 데이터를 가지고 오는데 23시면 사실 그 날 가지고오는 쿼리 중 가장 데이터가 많은 쿼리 일 것입니다. 아침은 더 적겠죠?..
하지만, 데이터가 많아지면 더 느려질까? 글쎄요. 저는 그렇지 않을 것이라 봅니다.
물론 시간 차이는 있겠지만, 눈에 띄는 차이를 줄려면 지금보다 10배 이상은 데이터가 많아져야 할 것이라고 생각합니다. 데이터 양에 따른 소요시간은 뒤에서 다룰 예정입니다.
이렇게 해서 테이블 락을 해결했습니다.
조금더 세세하게 하려면, 지금 데이터 업데이트를 collected_at과 account_id 기준으로 하고 있는데, 2 개만 겹치지 않으면 사실 한 테이블에서 여러 스캐줄러가 작동해도 문제 없습니다. 우리는 프로시저가 작동될 때 이미 어떤 Row를 어떻게 바꿀지 알고 있으니까요. 하지만 이것은, Todo로 남겨서, 2차전에 해결하도록 하고 우선은 이렇게 만들었습니다.
두번째 복병 아닌 복병
끝이라고 생각했을때, 그때가 시작이었습니다.
왜 매번 걸리는 시간이 다를까? Redshift Query시간은 거의 항상 비슷한데, 왜 데이터를 적재하는 시간에서 차이가 이렇게 날까? 많이 나면,, 20~30% 이상? 대체 왜그럴까 고민했습니다.
PostgreSQL에는 Vacuum 이라는 개념이 존재 합니다. PostgreSQL에만 존재합니다. Oracle MariaDB, MySQL, MS-SQL 어디에서도 찾아볼 수 없는 개념이기에 이걸 그냥 간과해버리면, 트랜젝션이 늘어났을 경우 예상과 다르게 행동하는 DB를 보고 PostgreSQL에게 실망(?) 하실 수도 있습니다.
두 번째 상황은, PostgreSQL에 설정된 임계값 이상의 Dead Tuple 이 발생하게 되면, 이 Dead Tuple 들을 클리닝 하기 위해 AutoVacuum 이 시작됩니다.
이것을 잘 이해하려면 Dead Tuple 이 무엇인지 알아야 하는데, PostgreSQL에는 모든 정보가 Tuple로 저장됩니다. 튜플은 Live Tuple 과 Dead Tuple 로 나뉩니다. 더 이상 참조되지 않는 Tuple이 바로 Dead Tuple 입니다. PostgreSQL*이 MVCC를 사용하면서 여러 버전을 가지고 있기 때문에 생기는 현상입니다.
Row의 여러 버전을 가지고 있으려면? 당연히 기존 Row를 delete 하거나 update 하면 발생하게 됩니다.
PostgreSQL 에서 Update를 하거나 Delete를 하면 아래처럼 작동합니다.
FSM** 공간 확보
FSM 에 새로운 데이터 쓰기
해당 Row/Column 를 바라보고 있는 포인터를 새로 작성한 데이터로 바꾸기.
헛? 그렇다면 기존에 포인팅 되고 있던 Row/Column 데이터는..? 이게 바로 Dead Tuple이 됩니다.
맞습니다. Live Tuple 대비 Dead tuple 수가 20% + 50개가 초과하면 Auto Vacuum이 돌기 시작합니다. (20%는 PostgreSQL 기본 값이고, AWS RDS Postgres는 10%가 기본값입니다.)
조금 더 쉽게 말해, 1000개의 데이터가 있는데, 250개의 Dead Tuple 이 있다면? 청소를 시작합니다. 그런데, 이게 왜 복병일까요? Full Vacuum은 Table Lock이 걸리기 때문에 아무것도 할수가 없지만 Auto Vacuum은 기본적인 액션은 제약 없이 계속해서 테이블 사용이 가능합니다(Truncate, Indexing 등은 불가).
오토베큠 설정을 글로벌로 할수도 있지만, 개별 테이블에 섬세하게 작업해 줄 수 있습니다. Dead Tuple 의 비율로 하게 되면 테이블마다 Vacuum에 걸리는 시간도, 리소스도 모두 다르게 됩니다. 그래서 몇가지 종류를 사전에 만들어서 테이블 별로 세팅 했습니다. 여기서 테이블을 파티셔닝 하면, Autovacuum이 파티셔닝된 테이블 단위로만 작동합니다!
아래처럼 설정 하면, Dead Tuple 0% + 20만개 인 경우이니 항상 비슷한 로드를 가진 오토베큠이 돌 수 있도록 처리가 가능합니다. 그래서 이렇게 처리했고, 베큠은 코스트 제한이 있어서(기본값 200) 다 정리를 못해도 코스트를 모두 소진하면 그만 두게 되있습니다.
우리 데이터 마트 DB는 일반적으로 사용하는 DB 같이 사용하지 않고 주기에 맞춰 모든 리소스(CPU, Memory 등)을 총 동원하여 데이터 싱크를 맞춥니다. 사전에 설정된 RDS 기본 세팅은 대부분의 환경에 잘 돌아가게 정의된 값이지, 우리의 목적에 맞게 세팅된 것은 아니라는 생각이 들었습니다.
autovacuum_vacuum_cost_delay
autovacuum_vacuum_cost_limit
위 두 옵션이 있는데, Vacuum 을 더 빠르게 할수 있습니다. 자주 할수도 있고요. Auto Vacuum 중에는 당연히 청소 안할때보다 퍼포먼스가 약간 줄어 듭니다. 그래서 청소를 시기적절하게 잘 할수 있도록 전략을 강구하시면 더 효과적으로 코끼리를 사용하실 수 있을 것이라 생각합니다.
dead_ratio 가 0.1이 넘으면 코끼리가 알아서 청소기를 돌립니다. 청소시간은 길게도 할 수 있고 짧게도 할 수 있습니다. 그 설정 값은 어느정도의 Dead Tuple을 견딜 수 있는 하드웨어이냐가 관건입니다. 이 Auto vacuum 시간 동안 성능 저하를 경험할 수 있습니다. 그래서 이 시간을 보장해주기 위해 스캐줄러를 실행하기전에 해당 테이블이 Vacuum 중인지 확인 하고 vaccuum 중이면 다시 스케줄링 하도록 하였습니다.
수집시간
레버의 모든 광고주 데이터 1주일 분량 수집 시간 (약 500~700만 Rows) - FB, Google
구글 메트릭 : 21초 구글 리소스 : 85초
페북 메트릭 : 76초 페북 리소스 : 7분 25초
레버의 모든 광고주 데이터 2주일 분량 수집 시간 - FB, Google
구글 메트릭 : 30초 (+9초) 구글 리소스 : 96초 (+11초)
페북 메트릭 : 94초 (+18초) 페북 리소스 : 8분 30초 (+1분 5초)
1주일 치 수집 페이스북 리소스 파트를 뜯어보겠습니다.
프로시저에 raise notice를 통해서 내부 수행을 어디까지 했는지 알리게 해두었습니다.
[2022-02-17 19:20:06] [00000] facebook_ad_creative collection has started (4분 18초걸림)[2022-02-17 19:24:23] [00000] facebook_ad_dm has started (1분 30초 걸림)[2022-02-17 19:25:53] [00000] facebook_ad_set collection has started (24초 걸림)[2022-02-17 19:26:17] [00000] facebook_asset collection has started (46초 걸림)[2022-02-17 19:27:03] [00000] facebook_campaign_dm collection started (3초 걸림)[2022-02-17 19:27:06] [00000] facebook_creative_asset_rel collection has started (26초 걸림)[2022-02-17 19:27:32] completed in 7 m 25 s 858 ms
소재 데이터가 가장 많습니다. 일단 일주일치 한번 쿼리하면 기본 30~40만 Row씩 잡힙니다.
오래 걸리는 스캐줄러들은 지속적으로 모니터링 하여 여러개의 프로시저로 쪼갤 예정입니다.
아주~ 쉽게! 우리에겐 프로시저 제너레이터가 있으니까요!
Redshift 부하는요…?
이제야 어떻게 사용해야 하는지 대충 감이 옵니다. Redshift는 와장창 데이터를 크게크게 퍼가는 것을 더 좋아하는 친구였습니다. 여러번의 쿼리 보다는 큰 쿼리를 좋아합니다. 그래서 어플리케이션 레벨에서 그 데이터를 잘 가공해서 사용하시면 될 것 같습니다. 제가 초반에 보여드렸던 EXPLAIN을 보시면, JOIN도 썩 좋은 아이디어가 아니라고 생각합니다.
현재 이렇게 바꾸고 Redshift는 평화롭습니다.
Procedure Watchtower
이제 가장 처음으로 드는 생각은 프로시저를 감시해야 한다는 생각 입니다. 단순한 프로시저지만, 성공이 100%일리가 없습니다. 프로시저는 내부 SQL Syntax 오류가 생겼을 경우 또는 Redshift, PostgreSQL 에 스키마가 예고 없이 변경된 경우 try… except 구문에서 잡힐 것 입니다. 하지만 그 것이 아니라 아래 같은 경우가 더 문제 입니다.
자기가 데드락인지도 모르고 Long Running 하는 프로시저
REDSHIFT 쿼리 시간이 지연되는 경우
평균시간 보다 오래걸리는 프로시저 처리하기
우리 job_schedules 테이블에 보면 seconds_taken 이라는 컬럼이 있습니다. 직전 수행시간을 적어 둡니다. 그보다 현저히(아직 정확한 수치는 테스트중) 길어 질 경우 아래와 같은 명령어로 해당 PS 찾을 수 있습니다.
pg_terminate_backend 는 해당 PID와 연관된 모든 상위 연관 Query Process를 죽입니다.
이제 고민해서 정책을 만들어야 합니다.
직전 수행시간의 3배 시간이 넘은 순간 Slack Notification 발송
DB 정기 유지보수 타임 Job 구동 제외
5배가 넘은 순간 Kill 후 해당 job을 리스캐줄
연속 실패시 카카오톡 알림 후 리스캐줄링 후 5분간 해당 Job_type 구동금지 반복
프로시저 세부 모니터링
우리는 DB는 서버의 요청을 받기만 한다고 생각합니다. 하지만, PostgreSQL은 프로시저 실행 중간중간에 어디까지 실행했는지 HTTP call을 서버에게 보낼 수 있습니다. 한 프로시저에서 여러 테이블을 동기화 하니 어떤 테이블에서 문제가 생겼는지 알기 위해 동기화 시작전에 Rest call을 서버에게 주도록 설계합니다. 그래봐야 몇번 안되니까요.
PostgreSQL에서는 여러가지 익스텐션을 이용해서 원하는 언어로 함수를 만들 수 있습니다. Python으로 만든 예시를 볼까요?
이렇게 하면 문제가 생겼을때 어떤 테이블에서 문제가 생겼는지 단숨에 알수 있습니다. 프로시저 내에서 UPDATE로 db 내용을 바꾸는 것은 어렵습니다. 트랜젝션으로 묶여있기 때문입니다. 할 수는 있겠지만, DB 테이블이 아니라 DB 용량등의 문제가 생긴다거다 그 보다 더 상위 레벨에서 문제가 생겼다면, 제대로 인포를 전달할 수 없기 때문에 Redis에 넣어서 분리 보관해줍니다. 어짜피 시간이 지나면 필요없어지는 로그들이니까요.
추후 조금 더 고도화 하면 실패한 테이블 부터 시작하도록 할 수 있습니다.
이 프로시저 모니터링이 배보다 배꼽이 더 큰거 아닌가요?
아.. 아마도.. 그럴 수도 있습니다…. 라고.. 저는 생각합니다… 하지만 그 어떠한 스캐줄러라도 모니터링 도구는 필요합니다. 단순한 작업이라도 매번 성공한다는 보장은 없으니까요. 이렇게 모니터링을 할 수 있다는 것 만으로도 상당히 만족합니다. Sustainability 측면과, 처음에 해결하고 싶었던 문제인 “데이터를 더 잘 쌓고” “더 잘 조회될 수 있는” 시스템을 위한 목적 달성에 일부라고 생각합니다.
고도화
1 라운드가 끝나갑니다. 다음 라운드에서 무엇을 해야 하는지 생각해 볼 시간입니다. 우선 가장 마음에 걸리는 것은 적재방법 입니다. Insert After Delete 이기 때문입니다. update 하고 Redshift에서 없어진 데이터를 어떻게 삭제 해주느냐 의 좋은 방법을 찾는 것이 다음 순서가 될 것입니다.
적재방법
Best Practices 는 현재 데이터를 적재하고 있는 전략을 우선 파악해 보아야 하겠지만, 한 가지 확실한 것은 지금 방법이 Best는 아닐 것 이라는 사실 입니다. 지우고 다시 데이터를 주입하는 순간 테이블은 제가 설정해 둔 인덱스를 다시 정리하기 시작할 것입니다. 그리고 시간이 지나면서 인덱스의 데이터가 파편화 되어 데이터베이스 내에 흩어지게 될것입니다. 그럴때 마다 유지보수를 해주어야 하겠지요. PostgreSQL 은 파티셔닝된 테이블의 리인덱스나 Partioned Indexing을 지원하지 않습니다. 파티션 별로 리인덱싱 해줘야 합니다.
또한, Delete 되는 양이 많아지면 많아질 수록 Vacuum 하는 시간도 오래 걸릴 것입니다. 그래서 저는 지우지 않고 업데이트 하고 싶었습니다. 이는 Redshift 가 현재 데이터를 쌓는 로직에 대해 더 자세한 내용을 공유받아 진행할 예정입니다. 추가적인 혜택(?) 으로는 Delete-Insert 가 아닌, 업데이트를 하면 Cursor를 통해 Pagination이 가능해집니다.
그래서, 뭐가 얼마나 좋아졌어요?
쿼리 시간 단축과, 필요한 데이터를 언제든지 호스를 꽂아 빨아 당겨 사용할 수 있다는 든든함!
Athena를 이용할때 1개의 광고주 페이스북 리소스를 수집하기 위해, Lambda Max Life Span인 900초를 넘겨서 다음 스케줄러로 이관, 이관, 이관 해서 끝도 없이 람다가 돌았습니다. 이제, 20초면 최신 매체에 접근 없이도 광고주 모든 데이터를 최신화 할 수 있습니다.
♾️ → 20초 (퍼포먼스 상승 ♾️ %)
레드시프트 쿼리과 비교하면,
캐시되지 않은 약 10분 소요되는 쿼리 → 30초, 덤으로! 필요한 데이터 프리컴퓨테이션 가능, 실제 쿼리 시간 → Instant!