최적의 메시지 브로커를 찾아서
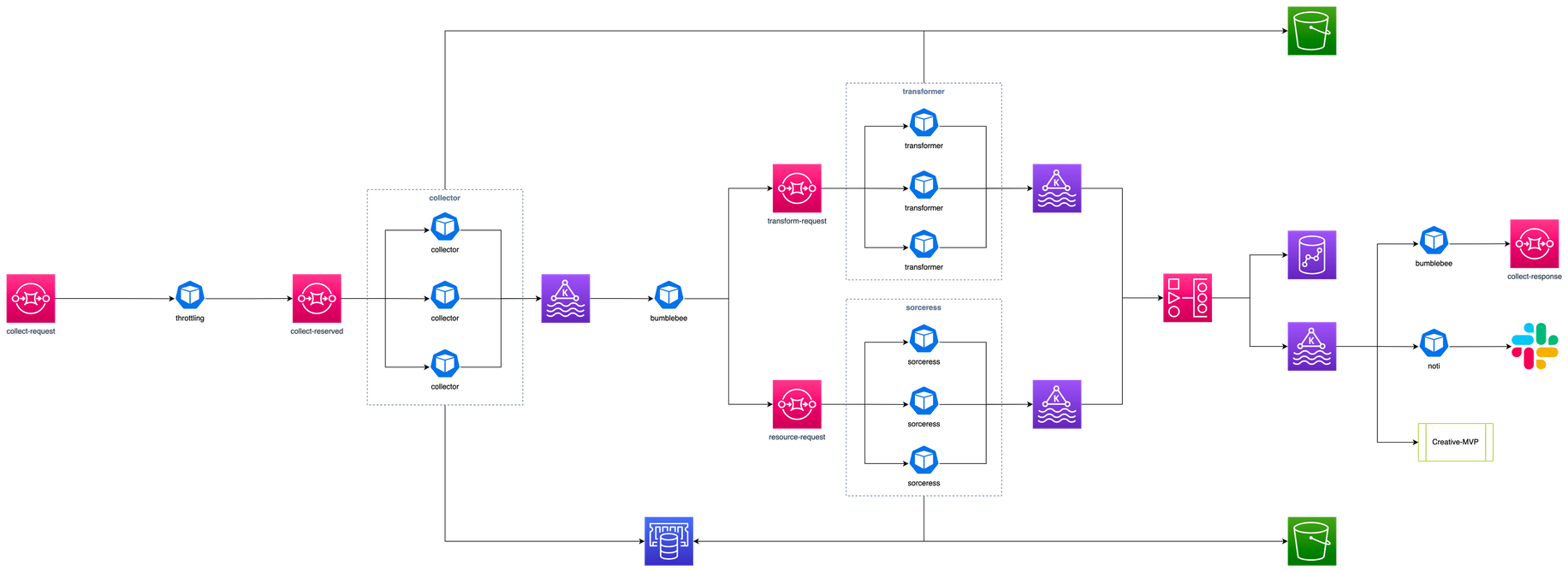
매드업에서는 프리즘이라는 시스템을 사용하여 광고 데이터를 수집하고 있습니다. 프리즘에 대해서는 여기를 참고해 주세요.
프리즘은 여러 마이크로 서비스들로 이루어져 있고, 마이크로 서비스들 간의 통신을 위해 메시지 기반 비동기 통신 방식을 사용하고 있습니다. 따라서 메시지들을 안정적이고 효율적으로 전달할 수 있는 메시지 브로커를 선택하는 것은 매우 중요한 문제입니다. 이 글에서는 프리즘이 발전하는 과정에서 실제로 사용한 메시지 브로커의 변천사를 소개하고자 합니다. 어떠한 이유로 사용하던 메시지 브로커를 변경하게 되었는지 실제 경험에 기반한 내용을 이야기해 보겠습니다.
프리즘을 위한 메시지 브로커가 갖춰야 할 기능 요건들
메시지 브로커를 사용할 때 이상적인 동작은 “정확히 한 번”(Exactly Once) 전달일 것입니다. 하지만 현실적으로는 어렵기 때문에 “최소 한 번”(At Least Once) 전달과 “최대 한 번”(At Most Once) 전달 중에 선택을 하게 됩니다. 프리즘은 메시지를 중복으로 처리해도 문제가 없는 시스템이기 때문에 최소 한 번 전달을 현실적인 목표로 잡았습니다.
프리즘에서 필요한 메시지 브로커가 갖춰야 할 기능 요건들은 다음과 같습니다.
- 안정적인 메시지 전달 (최소 한 번 전달)
프리즘은 쿠버네티스 환경에서 운영되고 있습니다. 쿠버네티스 환경에서 파드의 종료는 배포나 HPA(Horizontal Pod Autoscaling) 등으로 인해 언제든 발생할 수 있기 떄문에, 파드가 종료되는 경우에도 메시지가 유실되지 않고 전달될 수 있어야 합니다. - 유연한 메시지 컨슈머(consumer) 스케일링
프리즘의 각 마이크로 서비스는 HPA를 사용하여 필요에 따라 파드 개수가 적절하게 조정됩니다. 따라서 메시지 컨슈머의 개수가 변하는 경우에도 큰 지연 시간 없이 메시지를 안정적으로 가져올 수 있어야 합니다. - 효율적인 메시지 분배
프리즘에서 수집하는 광고 데이터는 광고주에 따라 사이즈 차이가 크며, 그에 따라 소요되는 수집 시간도 차이가 큽니다. 데이터 사이즈가 작은 광고주의 경우 1분 안에 수집이 끝나기도 하지만, 사이즈가 큰 광고주는 20~30분이 걸리기도 합니다. 이처럼 메시지 처리 시간의 편차가 큰 편이기 때문에 일률적으로 메시지를 분배하는 라운드 로빈(Round Robin)과 같은 방식은 적합하지 않습니다. 여유가 있는 메시지 컨슈머에게 우선적으로 메시지를 전달할 수 있어야 합니다.
실제로는 더 많은 기능 요건들이 있지만, 여기서는 이 글과 관련된 것들만 언급했습니다. 이러한 요건들에 맞는 최적의 메시지 브로커를 한 번에 찾았다면 좋았겠지만 아쉽게도 그러지 못 했습니다. 지금부터는 프리즘 운영 환경에서 실제로 사용했었던 메시지 브로커인 SQS와 카프카, 그리고 현재 사용 중인 RabbitMQ에 대해 얘기해 보겠습니다.
SQS
새로운(v2) 프리즘을 만들면서 처음 사용한 메시지 브로커는 Amazon SQS(Simple Queue Service)였습니다. AWS를 사용하고 있기 때문에 쉽게 적용할 수 있었고, 다른 팀에서도 사용하고 있었기 때문에 큰 고민 없이 선택했습니다. 그리고 현재도 프리즘 외부와 메시지를 주고 받을 때는 사용하고 있지만, 프리즘 내부에서는 사용하고 있지 않습니다. 프리즘 내부에서 SQS를 사용하지 않기로 결정한 가장 큰 이유는 기능 요건 1번 “안정적인 메시지 전달”과 관련이 있습니다.
SQS는 메시지를 수신한 후에 처리가 완료되면 해당 메시지를 삭제해야 합니다. 그리고 메시지의 최소 한 번 전달을 보장하기 위해, 수신 후 삭제되지 않은 상태에서 visibility timeout이 지나면 메시지를 다시 수신하게 됩니다.

이미지 출처: https://docs.aws.amazon.com/ko_kr/AWSSimpleQueueService/latest/SQSDeveloperGuide/sqs-visibility-timeout.html
프리즘에서는 이 visibility timeout 값을 어떻게 설정할지에 대한 고민이 많았습니다. 특히 앞에서 얘기한 것처럼 프리즘의 메시지는 처리하는데 소요되는 시간의 편차가 크기 때문에 적정한 값을 찾는 것이 어려웠습니다. 값을 크게 설정하면, 메시지를 처리하던 파드가 종료되었을 때 다시 메시지를 수신하기까지의 텀이 길어지는 문제가 있습니다. 반대로 값을 작게 설정하면, 메시지를 처리 중인데도 다시 동일한 메시지를 수신하게 되고, 메시지가 중복 처리되는 것을 막기 위해 별도의 처리를 해야 했습니다. 앞에서 언급했던 것처럼 프리즘은 메시지를 중복으로 처리해도 문제가 없긴 하나, 불필요한 자원 사용을 줄이기 위해 중복 처리되지 않도록 했습니다.
이러한 SQS 특성은 비연결성(connectionless) 때문인 것으로 생각됩니다. 메시지 컨슈머와 연결을 유지하고 관리하는 형태가 아니기 때문에, 컨슈머가 종료된 것을 인지하지 못 하고 visibility timeout과 같은 장치가 필요한 것이죠. 아무튼 visibility timeout과 관련된 SQS의 동작 방식으로 인해 애플리케이션이 불필요하게 복잡해지는 것으로 보였고, 그래서 고민 끝에 SQS 대신 카프카를 도입하기로 했습니다.
카프카(Kafka)
카프카를 사용하면서 SQS의 visibility timeout과 관련된 코드들을 삭제할 수 있었습니다. 카프카는 컨슈머 그룹이 각 파티션 별로 가지고 있는 현재 오프셋(offset)을 참조하여 다음에 가져올 메시지를 결정합니다. 어떤 메시지가 처리 중에 문제가 발생하여 해당 오프셋이 커밋되지 않았다면, 다음에 그 메시지를 다시 가져오도록 되어 있어 최소 한 번 전달을 보장하고 있습니다. 또한 브로커가 컨슈머 그룹을 관리하도록 되어 있어, 특정 컨슈머가 의도치 않게 종료되면 리밸런싱을 통해 해당 컨슈머가 메시지를 읽어 들이던 파티션들을 다른 컨슈머에게 할당하게 됩니다.
하지만 카프카를 계속 사용하면서 SQS를 사용할 때는 없었던 새로운 문제들이 등장했습니다.
첫 번째 문제는 컨슈머 그룹 리밸런싱과 관련이 있습니다. 카프카는 컨슈머 그룹에 속한 컨슈머의 개수가 바뀌면 리밸런싱을 통해 파티션을 재분배 합니다. 그런데 메시지 처리가 오래 걸리는 경우, 해당 컨슈머가 리밸런싱 과정에 참여하지 못 하면서 리밸런싱이 상당 시간 지연되는 문제가 있었습니다. 이를 해결하기 위해 메시지를 수신하는 스레드와 처리하는 스레드를 분리하여 리밸런싱 지연 시간을 줄일 수는 있었지만, 그로 인해 다른 문제들이 생겨났고, 그 문제들을 해결하기 위해 애플리케이션은 더 복잡해졌습니다.
두 번째 문제는 카프카의 파티션 구조와 관련이 있습니다. 카프카는 토픽의 메시지들을 파티션들에 나눠서 저장합니다. 예를 들어 토픽이 5개의 파티션을 가지고 있고 총 1000개의 메시지가 저장되어 있다면, 평균적으로 각 파티션은 200개 정도의 메시지를 가지고 있을 것입니다. 그리고 동일한 그룹에 속하는 컨슈머들은 이 파티션들을 나눠서 할당받아 그 안에 있는 메시지들을 순서대로 가져오게 됩니다. 그런데 앞에서 얘기했던 것처럼 프리즘의 메시지는 처리 시간의 편차가 큰 편입니다. 만약 특정 파티션에 처리 시간이 매우 오래 걸리는 메시지가 들어 있다면 어떻게 될까요? 오래 걸리는 메시지 뒤에 있는 메시지들은 처리가 되기까지 상당한 시간을 기다려야 하고, 그러다 보니 해당 파티션을 할당받은 컨슈머만 lag이 증가하는 원치 않는 상황이 발생했습니다.
이러한 문제들 때문에 카프카가 프리즘에 맞는 메시지 브로커인지를 다시 고민하게 되었고, 더 나은 대안으로 RabbitMQ를 선택하게 되었습니다. 그러면 마지막으로 왜 RabbitMQ를 선택했는지 얘기해 보겠습니다.
RabbitMQ
RabbitMQ는 AMQP(Advanced Message Queuing Protocol)를 구현한 메시지 브로커입니다. 많은 특징들이 있지만 여기서는 프리즘에 도입할 때 중요하게 생각했던 점들만 얘기해 보겠습니다.
첫 번째는 최소 한 번 전달을 보장하기 위한 기능입니다. RabbitMQ는 메시지를 수신한 컨슈머가 메시지를 처리한 후 ack(Acknowledge)를 전송해서 처리가 완료되었음을 알리도록 되어 있습니다. 그래서 RabbitMQ 큐에 있는 메시지는 처음에는 ready 상태였다가, 컨슈머로 메시지가 전달되면 unacked로 바뀌게 되고, 컨슈머가 ack를 전송하면 큐에서 삭제됩니다. 만약 컨슈머가 메시지에 대한 ack를 전송하지 못 하고 종료되면, 그 메시지는 다시 ready 상태가 되어 다른 컨슈머에게 전달 됩니다. 그리고 RabbitMQ 브로커와 컨슈머는 연결을 맺고 있습니다. 그래서 컨슈머가 OOM(Out of Memory) 등의 이유로 인해 비정상적으로 종료되어도, 브로커가 연결이 끊어진 것을 감지하고 해당 컨슈머가 처리하고 있던 메시지들을 다시 ready 상태로 변경합니다.
두 번째는 컨슈머들의 스케일링이 쉽습니다. 카프카는 동일한 그룹의 컨슈머 개수를 늘리기 위해서는 파티션 개수를 맞춰서 늘려줘야 합니다. 그리고 컨슈머 개수가 바뀌면 리밸런싱이라는 과정을 통해 파티션들을 컨슈머들에게 재분배하게 되는데, 컨슈머 개수가 자주 바뀌는 경우에는 빈번한 리밸런싱으로 인해 메시지 처리가 지연되는 문제가 있었습니다. 메시지를 처리하는 시간이 짧고 균일하다면 크게 문제가 되지 않지만, 프리즘은 편차가 크다보니 문제가 되었습니다. 하지만 RabbitMQ는 동일한 큐에 대해 컨슈머가 추가, 삭제되는 경우에 별도의 리밸런싱과 같은 작업이 필요하지 않아 컨슈머들의 개수를 빈번하게 변경해도 문제가 없습니다.
세 번째는 메시지를 효율적으로 분배하는 것입니다. 앞에서 언급했던 것처럼 카프카의 경우 메시지들이 파티션들에 나눠서 저장되고, 오프셋을 커밋하는 구조라서 잘못하면 특정 파티션의 메시지들만 처리가 지연되는 문제가 있었습니다. RabbitMQ는 큐에 있는 메시지들이 컨슈머로 전달되고 ack를 받아서 삭제되는 것과 같은 처리가 각 메시지에 대해 개별적으로 이뤄지기 때문에 메시지를 효율적으로 전달할 수 있었습니다.
여기까지 주된 3가지 이유에 대해 얘기해 봤는데, 이에 더해 몇 가지 장점을 더 소개해 보겠습니다.
프리즘은 매드업의 광고사업부를 위한 데이터를 수집하는 것을 넘어, 레버 엑스퍼트를 통해 다양한 고객의 광고 데이터를 수집하고 있습니다. (레버 엑스퍼트는 SaaS 형태로 제공되는 마케팅 업무 자동화 솔루션입니다.)
SaaS에서는 테넌트 간의 격리(isolation)가 중요한 문제인데요. 격리의 수준과 방법은 다양하지만, 여기서는 테넌트 별로 메시지 큐를 분리하는 상황을 얘기해 보겠습니다. 테넌트 ID에 따라 다른 메시지 큐로 메시지를 보내야 하는 기능을 어떻게 쉽게 구현할 수 있을까요? RabbitMQ에는 exchange라는 개념이 존재합니다. 메시지 프로듀서가 exchange로 메시지를 보내면서 라우팅 키를 설정하면, 라우팅 키에 따라 미리 바인딩 된 큐로 메시지가 자동으로 전달됩니다. 테넌트 ID를 라우팅 키로 사용하면, 프로듀서는 exchange에만 메시지를 보내면 되고, exchange가 라우팅 키에 따라 메시지를 해당 큐로 넣어 주기 때문에 매우 편리합니다. 이러한 exchange, 라우팅 기능을 사용하면 메시지를 다양한 형태로 전달할 수 있습니다.
또 다른 장점은 우선순위 큐를 제공한다는 것인데, 큐에 있는 메시지들 중에서 우선순위가 높은 메시지들이 먼저 컨슈머로 전달되어 처리되도록 할 수 있습니다. 이런 우선순위 기능을 사용하면 큐를 분리하지 않고도 우선순위가 높은 요청(e.g. 유료 플랜 고객의 요청)을 먼저 처리하고, 우선순위가 낮은 요청(e.g. 급하지 않은 시스템 내부의 요청)은 나중에 처리되도록 할 수도 있습니다.
글을 마치며
지금까지 프리즘에서 사용하는 메시지 브로커를 왜 변경해왔는지 얘기해 보았습니다. 저희 팀은 SQS, 카프카를 사용했을 때 겪은 문제들을 해결하기 위해 결국 RabbitMQ를 선택했지만, 그것이 RabbitMQ가 SQS, 카프카보다 더 우수하다는 의미는 아닙니다. 단지 프리즘의 요구 사항에 가장 잘 맞았던 것 뿐입니다. 서비스에 따라 요구 사항들이 다를 것이고, 그에 맞는 메시지 브로커가 있을 것입니다. 중요한 것은 어떤 것이 우리에게 가장 적합한지를 잘 찾아가는 것이라고 생각합니다.
이렇게 적고나니 약간의 부끄러움이 밀려옵니다. 처음부터 서비스의 요구 사항들과 각 메시지 브로커의 특징들을 잘 파악해서 최선의 선택을 했다면 얼마나 좋았을까요? 그랬다면 좋았겠지만 현실은 항상 달콤하지만은 않은 것 같습니다. 중요한 것은 현재의 문제를 직시하고, 더나은 대안을 고민하고, 실행에 옮기는 것이 아닐까 생각합니다.
끝으로 저희 팀이 겪은 시행 착오가 누군가에겐 도움이 되기를 바라며 이 글을 마칩니다. 읽어 주셔서 감사합니다.