"따뜻한 색감의 소재 찾아줘" — 자연어로 광고 소재 검색하기
1. 들어가며
인스타그램을 보다보면 나오는 화려한 광고들은 누가 만들까요? 대 AI 시대에도 광고 소재는 여전히 많은 전문가들의 손을 거쳐 제작되고, 또 수명이 다하면 사라집니다. 그렇기 때문에 마케팅 에이전시에서도, 인하우스 마케팅 부서에서도, 주기적으로 레퍼런스를 찾기 위해 반복적으로 아까운 시간을 보내게 됩니다.
LEVER Xpert AI팀은 간단한 질의로 마케터의 상황에 필요한 광고 소재 이미지를 찾을 수 있는 소재 검색을 구현함으로써 레퍼런스 수급이라는 과업을 빠르게 해줄 수 있는 도구를 마련하고자 했습니다. 이 글은 검색의 틀을 처음 구성하며 시도했던 방향과 실험 결과를 기록하고자 합니다.
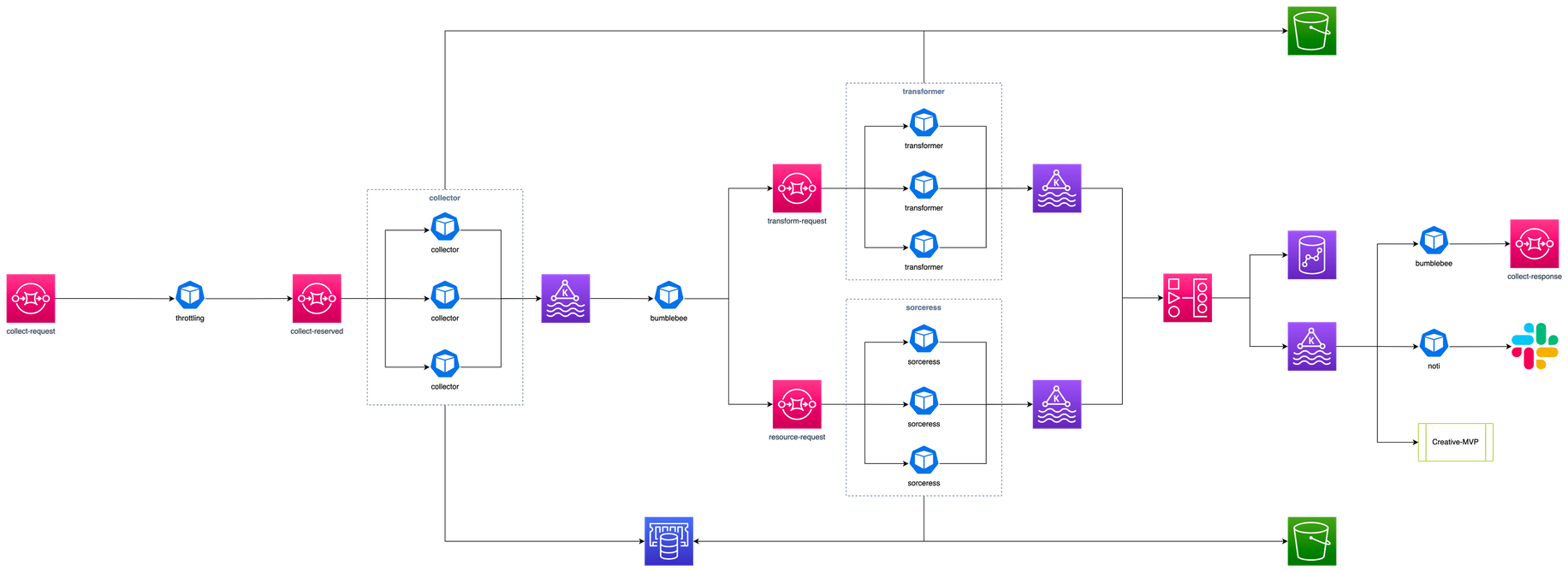
2. 시스템 개요
광고 소재 이미지를 자연어로 검색하는 시스템입니다. 크게 두 개의 파이프라인으로 구성됩니다. Offline Pipeline은 검색 대상 데이터를 미리 준비하고, Online Pipeline은 사용자 질의를 실시간으로 처리합니다.
이어지는 절에서 각 파이프라인과 기술 스택을 자세히 다룹니다.
2.1. Offline Pipeline — 데이터 준비
Offline Pipeline은 사용자 검색에 앞서 실행하는 단계입니다. 광고 소재 이미지를 검색 가능한 형태로 미리 변환해 두는 게 목적입니다.

다음과 같이 구성됩니다.
- Description 추출: LLM이 광고 소재 이미지를 보고 구조화된 설명 텍스트를 생성합니다.
- 이중 인덱싱: Description을 의미 검색용 (Dense)과 키워드 검색용 (Sparse) 두 형태로 변환해 같은 Vector DB에 저장합니다.
2.2. Online Pipeline — 검색 API
Online Pipeline은 사용자 질의가 들어왔을 때 실시간으로 동작합니다. 앞서 준비된 인덱스 위에서 질의를 처리해 결과를 반환합니다.

다음과 같이 구성됩니다.
- 질의 이해: LLM이 자연어 질의를 검색에 적합한 형태로 변환합니다 (e.g., 검색어 추출, 변형 쿼리 생성).
- Hybrid Search: 의미 검색 (Dense)과 키워드 검색 (Sparse)을 동시에 실행해 결과를 결합합니다.
- Reranking: LLM이 검색 결과의 순위를 재평가해 최종 순위를 결정합니다.
2.3. 기술 스택과 다음 섹션 미리보기
기술 스택
- Vector DB: Milvus
- Dense Embedding: Gemini Embedding
- Sparse Search: BM25
- LLM: Gemini (질의 이해, Reranking)
다음 섹션 미리보기
이 시스템을 만들면서 마주친 핵심 결정과 발견을 세 가지 Deep Dive로 풀어냅니다.
- 3장: CLIP 같은 멀티모달 임베딩 대신 Description 기반을 선택한 이유와 trade-off를 다룹니다.
- 4장: 확장 쿼리에 동등 가중치를 주면 원본 의도가 묻히는 문제를 강화학습의 Exploitation vs Exploration 개념으로 풀어냅니다.
- 5장: 직관적으로 옳아 보였던 가설들이 실측에서 반대 방향으로 작동한 사례들을 정리합니다.
3. Deep Dive 1 — 이미지를 ‘검색 가능한 텍스트’로 만들기
3.1. 이미지를 어떻게 검색 가능하게 할 것인가
일반적인 RAG 시스템은 텍스트 문서를 검색 대상으로 삼습니다. 문서를 청크 단위로 잘라 임베딩하고, 자연어 질의를 같은 공간에 매핑해 유사도로 매칭하는 구조가 보편적입니다. 저희가 풀려는 문제는 이와 다르게 검색 대상이 텍스트가 아닌 이미지 (광고 소재)입니다. 마케터는 “따뜻한 색감의 모델컷”처럼 자연어로 질의하는데 그 질의가 향하는 대상은 이미지입니다. 이질적인 두 modality를 어떻게 같은 검색 공간으로 끌어들일지가 시스템 설계의 첫 번째 과제였습니다.
3.2. 두 가지 선택지
이 과제에 접근할 수 있는 길은 크게 두 가지입니다.
접근 A — 이미지 직접 임베딩
CLIP같은 멀티모달 임베딩 모델로 이미지를 벡터화하고, 질의 텍스트도 같은 공간에 임베딩하여 유사도로 매칭하는 방식입니다. 이미지와 텍스트가 사전 학습된 공통 임베딩 공간 위에 놓이므로, 중간 변환 없이 두 modality를 곧바로 비교할 수 있다는 점이 가장 큰 장점입니다.
접근 B — 이미지 → 설명 텍스트 → 임베딩 (Description 기반)
LLM이 이미지를 보고 구조화된 설명 텍스트를 생성한 뒤, 그 텍스트를 임베딩하여 텍스트–텍스트 검색으로 풀어내는 방식입니다. 이미지를 일단 텍스트 공간으로 옮긴 후 그 위에서 기존 RAG의 검색 패턴을 그대로 활용하는 구조입니다. 두 modality를 같은 텍스트 공간으로 통일할 수 있다는 점이 가장 큰 장점입니다.
저희는 접근 B (Description 기반)를 선택했습니다. 이유는 네 가지였습니다.
3.3. Description 기반을 선택한 이유
첫째, 표현력
Description은 이미지의 다면적 특성을 구조화해서 담아냅니다. 광고 소재는 한 가지로 요약되지 않습니다. 소재 형식, 소구하는 바, 등장하는 객체 등 여러 측면이 한 이미지 안에 공존합니다. CLIP같은 멀티모달 임베딩은 이 모든 측면을 하나의 벡터로 압축합니다. 반면 Description은 각 측면을 구분된 텍스트 단위로 풀어낼 수 있습니다. 저희 PoC에서도 한 이미지를 여러 카테고리로 나누어 추출했습니다. 마케터가 카피 문구를 기준으로 검색할 수도 있고 원하는 소재 이미지를 묘사하는 방식으로 검색할 수도 있습니다. 어느 요소가 검색의 기준이 되든 대응할 수 있으려면 이미지를 측면별로 분리해서 표현할 수 있어야 합니다. 이 분리 가능성이 Description 기반의 첫 번째 강점입니다.
둘째, 검색 구조의 유연성
의미 기반과 키워드 기반 검색 양쪽을 모두 활용할 수 있습니다. 자연어의 의미를 포착해야 하는 질의 (Dense)와 고유명사처럼 정확한 키워드 매칭이 필요한 질의 (Sparse)는 서로 다른 검색 방식을 요구합니다. 고유명사는 의미 임베딩만으로는 안정적으로 매칭되지 않습니다. Description 기반은 두 검색을 결합한 Hybrid Search로 자연스럽게 확장됩니다.
셋째, 질의와 같은 텍스트 공간
의미 비교가 직관적입니다. 마케터의 자연어 질의와 Description은 둘 다 한국어 텍스트입니다. “여름철 바캉스를 연상시키는 실사 배경의 연출제품컷”이라는 질의가 들어왔을 때 “해변 리조트 분위기의 청량한 배경”이라는 Description과 의미가 가까운지 판단하는 것은 텍스트 공간 위에서 직접 일어납니다. CLIP 기반 방식은 사전 학습된 공간을 사용하여 마케팅 도메인 특유의 어휘 (e.g., “소구점”, “비포애프터형 광고”)가 어떻게 매핑되는지 통제하기 어렵습니다. 반면 Description 기반 방식은 추출 프롬프트를 통해 도메인 어휘를 직접 주입할 수 있습니다. 검색이 동작하는 의미 공간을 검색 대상 도메인 (마케팅)에 맞춰 조정할 수 있다는 뜻입니다.
넷째, 해석 가능성과 반복 개선의 용이성
어떤 소재가 왜 매칭되었는지 사람이 읽고 판단할 수 있습니다. 그 소재의 Description을 직접 살펴보면 결과 상위에 올라온 이유를 알 수 있습니다. 검색 품질이 기대에 못 미칠 때 원인이 Description의 어떤 표현에 있는지 추적이 가능합니다. 추적된 원인을 통해 모델을 다시 학습시키는 것이 아닌, 추출 프롬프트만 수정하여 표현을 바꿀 수 있어서 개선 사이클이 빨라집니다. CLIP 기반은 모델을 교체하거나 파인튜닝해야 표현 공간을 바꿀 수 있어 반복 개선의 비용이 큽니다.
이 네 가지 강점의 핵심은 이미지라는 modality를 텍스트 공간으로 통일함으로써 검색 대상도 질의도 같은 공간 위에서 다룰 수 있게 된다는 점입니다.
4. Deep Dive 2 — Query Expansion에 강화학습 개념을 적용하다
4.1. 문제 상황
3장에서 Description 기반의 Hybrid Search가 동작하는 환경을 만들었습니다. 그 위에서 다른 종류의 문제가 드러났습니다. 사용자 질의가 짧거나 모호할 때 Recall (검색 결과 상위에 정답이 포함되는 비율)이 눈에 띄게 낮았습니다. 예를 들어 “여름 소재” 같은 2~3 단어짜리 질의는 매칭되는 Description이 제한적이었습니다. 한 이미지의 Description 안에는 “해변 리조트 분위기”, “청량한 파란 하늘”, “자외선 차단” 같은 다양한 표현이 들어있는데, “여름 소재”라는 표면적 어휘로는 이 표현들을 모두 포착하기 어렵습니다. 원본 질의의 표면적 어휘에만 의존해서는 같은 의미를 담은 다양한 Description의 표현을 충분히 잡지 못한다는 것이 핵심 문제였습니다. 이 문제를 풀기 위해 사용자 질의를 검색 직전에 한 번 더 가공하는 단계 (Query Rewrite)를 도입하기로 결정했습니다.
4.2. 세 가지 접근
Query Rewrite에는 크게 세 가지 접근이 알려져 있습니다.
접근 A — Augmentation (쿼리 보강)
원본 질의를 더 자세하게 풀어 한 개의 풍부한 질의로 만드는 방식입니다. e.g., “상품누끼컷” → “배경을 제거하고 상품만 깔끔하게 오려낸 이미지”. 어려운 단어를 풀어주거나 누락된 맥락을 더해 검색에 유리한 형태로 보강합니다.
접근 B — Expansion (쿼리 확장)
원본 질의를 다양한 표현으로 변형하여 여러 개의 쿼리를 만드는 방식입니다. e.g., “여름철 바캉스를 연상시키는 실사 배경의 연출제품컷”
- “해변 리조트 분위기의 실사 배경 연출제품컷”
- “트로피컬 무드가 느껴지는 야외 배경 제품 이미지”
- “수영장이 보이는 여름 휴양지 컨셉 제품컷”
- …
여러 표현으로 동시에 검색하여 어느 한 표현에 매칭이 좌우되지 않도록 합니다.
접근 C — Query Description (HyDE 계열)
원본 질의에 대한 가상의 답변 텍스트를 LLM으로 생성한 뒤, 그 가상 답변으로 검색하는 방식입니다. 검색 대상인 Description과 비슷한 결의 텍스트가 질의 쪽에서 만들어지므로 임베딩 공간 안에서의 거리가 가까워질 수 있다는 직관에서 출발합니다.
비교 결과
같은 평가 환경 (Description 기반 인덱스, Hybrid Search) 위에서 세 가지 접근을 측정했습니다. Recall@30은 검색 결과 상위 30개 안에 정답이 포함되는 비율을 가리킵니다. 본문의 수치는 PoC 환경에서 측정한 값으로, 실제 제품의 최종 성능과는 다를 수 있습니다.
| 접근 | Recall@30 |
|---|---|
| Augmentation | 0.51 |
| Expansion | 0.66 |
| HyDE (Query Description) | 0.59 |
Expansion의 개선 폭이 가장 컸기 때문에 이 접근을 채택했습니다. 직관적으로도 설명됩니다. 광고 소재의 Description은 같은 시각적 의미를 두고도 표현이 매우 다양해질 수 있는 텍스트입니다. 원본 질의 하나만으로 그 다양성을 모두 잡기보다, 여러 변형 쿼리로 의미 공간을 폭넓게 훑는 쪽이 매칭 누락을 줄이는 데 더 효과적이었습니다.
4.3. Expansion 적용에서 마주친 문제
Expansion의 동작은 단순합니다. LLM이 원본 질의를 받아 N개의 변형 쿼리를 생성하고 각 쿼리로 따로 검색해서 나온 결과들을 결합 (fusion)하는 구조입니다.

그런데 단순한 결합 방식에 문제가 있었습니다. 원본과 확장 쿼리에 동등한 가중치를 주면 확장을 아예 쓰지 않은 경우보다 Recall@30이 오히려 낮아졌습니다 (정확한 수치는 4.5절의 표에서 확인할 수 있습니다).
확장 쿼리는 LLM이 원본을 보고 만든 변형이라 사용자 의도와 어긋난 것도 섞입니다. 원본과 같은 가중치로 합치면 이런 어긋난 변형들이 결과를 끌어내려 확장으로 얻은 Recall 향상이 그만큼 줄어듭니다.
4.4. Exploitation vs Exploration
이 시점에서 강화학습의 한 개념이 떠올랐습니다. Exploitation과 Exploration의 trade-off입니다.
- Exploitation: 이미 알고 있는 좋은 선택지를 활용하는 것
- Exploration: 새로운 선택지를 탐색하여 더 좋은 선택지를 발견할 가능성을 키우는 것
강화학습에서 이 둘 사이의 균형을 어떻게 잡느냐가 전체 성능을 결정합니다. 너무 Exploitation만 하면 새로운 가능성을 놓치고, 너무 Exploration만 하면 이미 검증된 좋은 선택을 활용하지 못합니다. Query Expansion의 상황도 정확히 같은 구조였습니다.
- Original Query = Exploitation: 사용자가 명시적으로 표현한 가장 신뢰도 높은 의도
- Expanded Queries = Exploration: 사용자가 명시하지 않은 다양한 표현을 탐색하는 시도
원본 쿼리와 확장 쿼리를 동등하게 결합한다는 것은 Exploitation과 Exploration의 비중을 1:N (N = 확장 쿼리 개수)로 설정해서 Exploration 쪽으로 크게 기울인다는 뜻이 됩니다. 이 비중이 너무 한쪽으로 쏠렸기 때문에 결과가 나빠진 것이라는 가설을 세웠습니다.
4.5. Exploration Weight의 도입
가설을 검증하기 위해 결합 방식을 다음과 같이 바꿨습니다.
원본 쿼리의 결과는 가중치 1.0으로 고정하고, 확장 쿼리들의 결과에는 별도의 가중치 exploration_weight를 부여합니다.
결과 통합은 Weighted RRF (Reciprocal Rank Fusion)로 처리합니다.
여기서 weight_i는 i번째 쿼리에 부여된 가중치 (원본은 1.0, 확장 쿼리는 exploration_weight), rank_i는 그 쿼리에서 해당 문서가 등장한 순위, k는 상위 순위의 영향이 과도해지지 않도록 순위 차이를 완만하게 만드는 상수입니다.
exploration_weight의 정의는 직관적으로 다음과 같습니다.
exploration_weight = 0.0: 확장 쿼리들의 결과를 완전히 무시. 원본 쿼리만 사용 (순수 Exploitation)exploration_weight = 1.0: 원본과 확장 쿼리들에 동등한 가중치 부여. 가장 강한 Exploration0.0 < exploration_weight < 1.0: 원본을 우선시하면서 확장 쿼리의 신호도 일부 반영
최적 weight 탐색
exploration_weight를 0.0부터 1.0까지 0.1 단위로 sweep하여 측정했습니다.
대표 결과 (Recall@30 기준)만 추리면 다음과 같습니다.
exploration_weight |
Recall@30 |
|---|---|
| 0.0 (원본만) | 0.80 |
| 0.2 (채택) | 0.86 |
| 0.5 | 0.83 |
| 0.7 | 0.81 |
| 1.0 (동등 가중치) | 0.77 |
(이 표의 수치는 4.2 이후 환경이 발전된 후속 평가 기준입니다.)
가장 높은 Recall@30을 보인 지점은 exploration_weight = 0.2였습니다.
원본만 쓰는 경우 (0.80)와 동등 가중치인 경우 (0.77) 둘 다 채택값 (0.86)보다 낮습니다.
도입 전후 성능 변화
Exploration Weight 도입의 효과는 두 비교에서 모두 명확하게 드러납니다.
- 원본만 사용 (
exploration_weight = 0.0)과 비교: Recall@30 0.80 → 0.86 (절대값 +0.06, 상대 +7.5%) - 동등 가중치 (
exploration_weight = 1.0)와 비교: Recall@30 0.77 → 0.86 (절대값 +0.09, 상대 +11.7%)
원본 우선 + 확장의 일부 반영이라는 균형 잡힌 설계가 두 극단보다 모두 더 좋은 성능을 만들어냈습니다. 이는 Exploitation과 Exploration의 trade-off라는 강화학습의 익숙한 개념을 검색이라는 전혀 다른 도메인에 그대로 가져와 풀어낸 사례입니다.
5. 예상을 뒤집은 발견들
PoC 진행 중 직관적으로 옳아 보였던 가설들이 실측에서 반대 방향의 결과를 내는 사례가 여러 번 있었습니다. 이 장에서는 그중 두 가지를 정리합니다. 두 사례는 각각 Description과 Query Expansion 영역에서 일어났지만 공통된 패턴을 보여줍니다.
5.1. “더 자세히 설명하면 더 잘 찾을 줄 알았는데”
Description의 품질을 높이기 위한 자연스러운 시도 중 하나는 “더 길게 쓰게 하는 것”이었습니다. 가설은 단순했습니다. 각 카테고리에 더 많은 문장이 들어가면 표현이 풍부해져 다양한 질의에 더 잘 매칭될 것이다.
구체적으로는 Description 추출 프롬프트에 다음과 같은 지침을 추가했습니다.
각 카테고리 내용은 최소 3 문장, 최대 5 문장을 포함해야 합니다.
길이 조건 적용 전후를 Recall@30으로 측정했습니다.
| 지표 | 길이 조건 없음 | 길이 조건 추가 |
|---|---|---|
| Recall@30 | 0.85 | 0.82 (↓) |
결과는 직관과 반대로 Recall@30이 떨어졌습니다.
원인은 다음과 같이 정리됩니다. 문장이 길어질수록 카테고리 안에 핵심 묘사뿐 아니라 부수적인 묘사도 함께 들어갑니다. 검색 임베딩 입장에서 이 부수적인 묘사는 신호가 아니라 노이즈로 작용할 가능성이 큽니다. 풍부함을 더하려던 의도가 매칭 신호를 흐리는 방향으로 작용한 셈입니다.
길이 자체가 답이 아니라는 점이 이 발견의 핵심 교훈이었습니다.
5.2. “Expansion 프롬프트에 Description 어휘 힌트를 주면 더 잘 될 줄 알았는데”
Expansion 자체의 효과를 확인한 뒤, Expansion 프롬프트를 더 다듬으면 추가 개선이 있을 것이라고 기대했습니다. 가설은 다음과 같았습니다. 확장된 쿼리들이 검색 대상인 Description의 어휘·문체와 닮을수록 임베딩 공간 안에서의 거리가 더 가까워져 매칭이 좋아질 것이다.
이 가설에 따라 Expansion 프롬프트에 다음과 같은 지침과 예시를 추가했습니다.
광고 description에 자주 등장하는 어휘와 패턴을 반영하도록 한다.
NDCG@10 (검색 결과 상위 10개의 순위 품질을 평가하는 지표) 기준으로 측정했고 결과는 예상과 정반대였습니다.
| 지표 | 어휘 힌트 없음 | 어휘 힌트 추가 |
|---|---|---|
| NDCG@10 | 0.55 | 0.44 (↓) |
상대 변화 기준 약 -20%. PoC에서 비교한 여러 변형 중에서도 큰 폭의 하락이었습니다.
원인을 추정해보면 다음과 같습니다. “광고 description에 자주 등장하는 어휘/패턴”이라는 지침은 LLM에게 명시적인 어휘 편향을 주문하는 셈입니다. 확장 쿼리들이 일정한 어휘 셋으로 쏠리면 원본 질의가 가졌던 다양한 의미 공간을 폭넓게 훑는 Expansion의 본래 강점이 좁아집니다. 확장의 목적이 “다양한 표현으로 의미 공간을 넓히는 것”이었는데 어휘 힌트는 그 다양성을 오히려 제약하는 방향으로 작용했습니다.
친절해 보였던 힌트가 LLM의 출력을 한 쪽으로 끌어당기는 편향으로 작용한 사례입니다.
5.3. 종합 인사이트 — LLM을 다룰 때 직관이 빗나가는 지점들
두 가지 발견은 서로 다른 영역 (Description, Query Expansion)에서 일어났지만 자세히 보면 공통된 패턴을 공유합니다.
길게, 그리고 친절하게.
LLM 시스템을 더 잘 만들려는 직관적인 시도들이 자주 반대 방향으로 작용했습니다.
- 더 길게: Description에 길이를 강제했더니 Recall이 떨어졌습니다.
- 더 친절하게: Query Expansion에 Description 어휘 힌트를 줬더니 다양성이 사라지고 성능이 떨어졌습니다. 또한 별도의 시도에서 사용자 예상 질의 키워드를 Description 추출 프롬프트의 예시로 삽입했더니, 일부 카테고리에서 키워드 편향이 나타나 일반화가 떨어지는 결과도 함께 관찰됐습니다.
이 사례들은 LLM의 동작 특성에서 공통된 결을 보여줍니다. 긴 텍스트는 신호로 작용하기보다 노이즈로 작용하기 쉽습니다. 친절한 예시는 LLM의 출력을 그 예시의 방향으로 끌어당기는 편향이 됩니다.
이 PoC의 본질이 가설 검증이라는 점에서 반복되는 교훈은 단순합니다. “빠르게 가설을 세우되 실측 없이 그 가설을 채택하지 않는다.” 직관이 빗나가는 지점일수록 더 깊은 통찰이 숨어있을 가능성이 높다는 점이 어쩌면 이 PoC의 가장 큰 수확이었을지도 모릅니다.
6. 마무리
자연어 질의로 광고 소재 이미지를 검색하는 PoC를 진행했습니다. 이 글에서는 그 과정에서 마주친 핵심 결정과 발견을 세 가지 Deep Dive로 풀어냈습니다.
각 Deep Dive가 보여준 교훈은 다음과 같습니다.
3장 — 텍스트 공간으로의 통일이 후속 작업의 기반이 된다
이미지를 텍스트 공간으로 옮긴 덕분에 사용자 질의와 검색 대상이 같은 공간에 놓였고 그 위에서 Hybrid Search를 비롯한 검색 설계가 이어졌습니다. 첫 설계 결정이 이후 모든 선택지를 좌우한 사례입니다.
4장 — 강화학습 개념이 검색 문제의 도구가 된다
Query Expansion의 동등 가중치 문제를 강화학습의 Exploitation vs Exploration trade-off로 풀어냈습니다. 익숙한 개념을 다른 도메인에 적용하는 것만으로도 막혀 있던 문제가 풀리는 경험이었습니다.
5장 — 직관보다 실측을 신뢰한다
길게·친절하게 같은 직관적 시도들이 LLM의 동작 특성과 충돌하면서 반대 방향으로 작용했습니다. LLM은 사람의 직관과 다르게 움직인다는 점이 반복적으로 확인된 발견이었습니다.
이렇게 세 가지 교훈을 정리하며 본 PoC를 마칩니다.
마지막으로 개인적인 소감을 덧붙이자면, 가장 흥미로웠던 건 익숙한 개념이 전혀 다른 문제의 도구가 되는 순간이었습니다. 강화학습의 Exploitation vs Exploration이 검색의 가중치 설계로 이어지는 걸 보면서, 어느 한 분야에서 익힌 개념의 쓰임새가 생각보다 훨씬 멀리까지 닿을 수 있다는 걸 새삼 느꼈습니다. 다음에 마주할 문제에서도 다른 도메인의 도구를 한 번씩 끌어와보는 자세를 잃지 않으려 합니다.
LEVER Xpert AI팀은 마케터가 AI를 통해 수고로운 작업들을 자동화하고 더욱 핵심적인 전략에 집중할 수 있는 제품을 하나씩 만들어나가고자 합니다. 소재 검색은 그 로드맵의 첫 단계로, 앞으로 방대한 데이터와 매드업이 보유한 도메인 지식을 기반으로 다양한 모델과 에이전트를 만들어나가고자 합니다.
열정적인 여정에 함께하고자 하는 분을 찾고 있습니다!
References
- Radford, A., Kim, J. W., Hallacy, C., et al. (2021). Learning Transferable Visual Models From Natural Language Supervision. arXiv:2103.00020.
- Gao, L., Ma, X., Lin, J., & Callan, J. (2022). Precise Zero-Shot Dense Retrieval without Relevance Labels. arXiv:2212.10496.
- Cormack, G. V., Clarke, C. L. A., & Buettcher, S. (2009). Reciprocal Rank Fusion outperforms Condorcet and individual Rank Learning Methods. SIGIR ‘09.