Redshift DW에서 PG DM을 만드는 여정
개요
매드업은 레버에 안정적으로 데이터를 공급하고 광고사업부에게 데이터를 공급하기 위하여 AWS S3에 데이터를 적재합니다. 완전한 raw data 는 아니지만, 각 매체(Facebook, Google 등) 에서 주는 데이터를 그대로 적재 합니다. 그리고 지금까지 이 S3 파일들을 Athena 라는 서비스로 쿼리하여 사용하였습니다.
하지만 Athena가 비용 대비 속도도 느리고 그 쿼리를 람다로 수행하는데 그 람다 역시 쿼리 시간 내내 떠있어야 하는 등 비용적 그리고 효율적인 측면에서 매우 불리했습니다. 그래서, 그 이름도 찬란한 Prism 프로젝트가 태어났습니다. Redshift 서비스를 이용해서 Data Warehouse를 멋지게 구현 해 냈습니다.
이후 우리는 점차 S3 + Athena 조합을 역사의 뒤안길로 보내면서 Redshift 에 붙어 바로 쿼리를 해서 데이터를 수집하는 것을 시작 합니다.
빨간맛 이었던 Redshift와의 첫만남
그렇게 Develop Redshift 에서 쿼리를 해보고 운영으로 Deploy를 했습니다.
그때는 바야흐로, 저녁 늦은 시간.
우선, Redshift 는 PostgreSQL 을 포크하여 구글의 빅쿼리에 버금 가도록 AWS 에서 직접 튜닝하여 제공하고 있는 대용량 데이터 베이스 입니다. 그래서 멋들어지게 여러 테이블을 조인 해서 쿼리를 보았고, 운영 환경의 Redshift에서도 당연히 평균이상의 속도는 보이지 않을까 하는 생각을 했습니다.
쿼리 속도도 속도지만, 레드 시프트는 Hash 조인을 하면서 CPU를 사용량이 높아졌고 이로 인해 Redshift는 스스로를 지키기 위해 Session을 끊어내고 있었습니다.
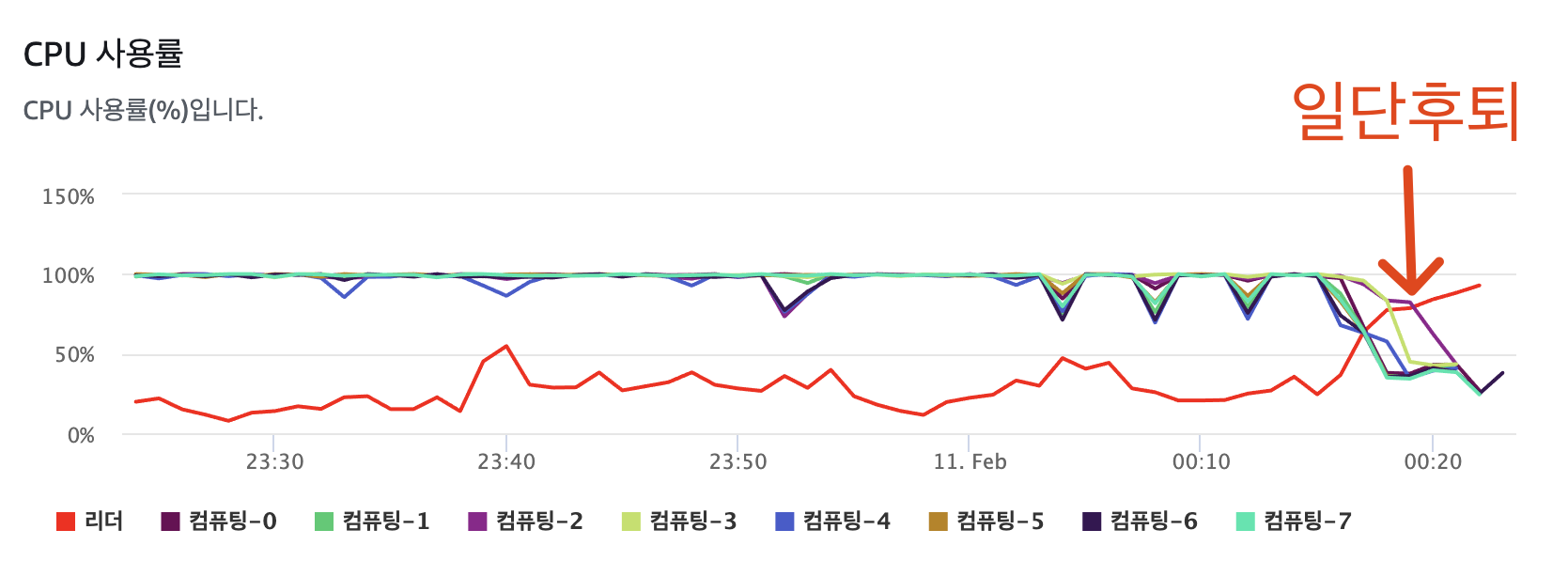
Explain으로 살펴보니 열심히 Hash Join 하여 여러 테이블의 데이터를 잘 서빙하기 위해 레드시프트는 노력하고 있었습니다.
그렇다면 Hash Join은 무엇인가? 왜 우리는 이것을 사용하는가?
사실 Hash Join이 말이 어려워서 그럴듯해 보이는 것이지 사실 조인 기법 중 하나 입니다. Merge Join이 대세였던 시절, 메모리가 한정적이기 때문에 DB가 테이블을 조인하면서 임시로 Disk에 써두었어야만 했었습니다.
그 Disk I/O 가 느리니, Hash Join이 생겼습니다. Join 되는 테이블과 비교하여 해쉬 함수 값에 의해 짝을 이루고 두 테이블 중 작은 테이블이 메모리에 적재 됩니다. 그리고 큰 테이블을 읽어가며 비교합니다. 대부분의 경우 CPU 자원이 넘치기 때문에 해시조인이 유리한 경우가 많은데, 과연 우리에게도 잘 어울리는 것인가, 의문을 가졌습다…. 만!?
결과는 그렇다 입니다. Redshift는 대용량 데이터베이스 답게 분산키, 정렬키 지정이 쉽지 않습니다. 이때 테이블끼리 조인을 할때 이 연결되는 연결고리 (a.client_id = b.client_id 같은) 에 인덱스가 처리되어 있지 않으면 Hash Join이 대부분의 상황에서 유리하기 때문입니다.
아무튼, 개발환경 Redshift에서 하던대로 아무생각 없이 비교적 많은 데이터가 있던 Redshift에게 너무 힘든일을 시켰습니다. 우리는 개발자이니, 우선 상황을 한번 봐야 겠다는 생각이 들어 같은 내용을 가지고 올수 있는 쿼리를 만들어 EXPLAIN으로 살펴보았습니다.
조인해서 가지고 오는 경우의 EXPLAIN
XN Hash Join DS_DIST_NONE (cost=38237.07..156530.04 rows=1 width=266)
" Hash Cond: (((""outer"".ad_set_id)::text = (""inner"".ad_set_id)::text) AND ((""outer"".account_id)::text = (""inner"".account_id)::text) AND (""outer"".collected_at = ""inner"".collected_at))"
-> XN Seq Scan on facebook_ad fa (cost=0.00..118274.62 rows=489 width=147)
Filter: (('2022-01-11'::date = collected_at) AND ('597060991453466'::text = (account_id)::text) AND (account_id IS NOT NULL))
-> XN Hash (cost=38237.07..38237.07 rows=1 width=189)
-> XN Hash Join DS_DIST_NONE (cost=5894.48..38237.07 rows=1 width=189)
" Hash Cond: (((""outer"".campaign_id)::text = (""inner"".campaign_id)::text) AND ((""outer"".account_id)::text = (""inner"".account_id)::text) AND (""outer"".collected_at = ""inner"".collected_at))"
-> XN Seq Scan on facebook_ad_set fas (cost=0.00..32241.10 rows=410 width=120)
Filter: (('2022-01-11'::date = collected_at) AND ('597060991453466'::text = (account_id)::text) AND (account_id IS NOT NULL))
-> XN Hash (cost=5894.41..5894.41 rows=8 width=108)
-> XN Seq Scan on facebook_campaign fc (cost=0.00..5894.41 rows=8 width=108)
Filter: (((account_id)::text = '597060991453466'::text) AND (collected_at = '2022-01-11'::date))
Union ALL 했을때의 EXPLAIN
XN Append (cost=0.00..156438.59 rows=2844 width=104)
" -> XN Subquery Scan ""*SELECT* 1"" (cost=0.00..5894.49 rows=8 width=85)"
-> XN Seq Scan on facebook_campaign fc (cost=0.00..5894.41 rows=8 width=85)
Filter: (((account_id)::text = '597060991453466'::text) AND (collected_at = '2022-01-10'::date))
" -> XN Subquery Scan ""*SELECT* 2"" (cost=0.00..32254.19 rows=1309 width=77)"
-> XN Seq Scan on facebook_ad_set fas (cost=0.00..32241.10 rows=1309 width=77)
Filter: ((collected_at = '2022-01-10'::date) AND ((account_id)::text = '597060991453466'::text))
" -> XN Subquery Scan ""*SELECT* 3"" (cost=0.00..118289.90 rows=1527 width=104)"
-> XN Seq Scan on facebook_ad fa (cost=0.00..118274.62 rows=1527 width=104)
Filter: ((collected_at = '2022-01-10'::date) AND ((account_id)::text = '597060991453466'::text))
서버 주변에 가까운 마트가 필요한데…?
가장 확실한 방법은 데이터마트를 중간에 두는 방법이었습니다. 이것은 확실하지만, 많은 공수가 들었고 당장 해결해 낼 수는 없는 것이기도 했습니다. 하지만, 임시방편 보다는 장기적으로 지속가능한 방법으로 해결해보라는 준(CTO)의 이야기에 바로 시작했습니다.
요구사항?
-
Redshift Spectrum 에는 파티셔닝이란 개념이 있지만, Redshift에는 그런게 없습니다. 그래서 마트를 만들면 우선 월별로 파티셔닝을 하고 싶었습니다. 이 것을 한다 하더라도 전혀 쿼리가 변경되지 않습니다.
-
레버(lever.me) 광고주의 데이터가 아닌 내용들은 쿼리 스캐닝 범위에 포함시키고 싶지 않아서 적재하고 싶지 않았습니다.
-
Redshift가 데이터를 적재하는 빈도와 주기에 맞추어 Redshift에서 우리가 사용하는 데이터만 “슬쩍” 훔처서 달아나고 싶었습니다.
-
혹시 필요하면 그때그때 DW에서 데이터를 가지고 오고 싶었습니다.
-
외래키 조인은 아니더라도 복합인덱스를 이용한 조인을 용이하게 하고 싶었으며, 필요하면 추가 인덱스도 만들고 싶었습니다.
-
Rest API 로 외부에 데이터를 송출할 수 있도록 하고 싶었습니다.
-
Redshift도 실시간으로 매체와 동기화 되지 않기 때문에 즉시 수집 기능이 있습니다. 즉시 수집을 요청하고 결과 콜백을 주는데 그 콜백을 받아주는 API를 이 이 서버 두어 그때그때 해당 내용을 수집하고 싶었습니다.
이 정도의 요구사항들을 수집했습니다.
이제 피버타임.
무조건 시간을 맞추어 끝내야 하는 것은 아니지만, 레버가 자랑하는 기능 중 ‘주간리포트’를 제대로 사용할 수 없는 지금 이 시간을 최대한 줄여야만 했습니다. 가장 중요한 것은 데이터를 잘 적재 하면서 데이터를 잘 조회 되도록 하는 것 입니다.
그리고 고민을 했습니다.
우리가 Redshift에서 필요한 데이터는 일주일에 약 10~11GB 입니다. 점점 늘어날 것 입니다. 이 데이터를 어떻게 가지고 오지?
- Data Mart DB ↔︎ 서버 ↔︎ Redshift
하루 1GB 데이터를 가지고 온다고 하면 서버에서 Redshift로 요청하고 다시 DB로..
쿼리 실행 시간보다, fetching 시간이 길수도 있겠다고 생각했습니다. 그리고 해당 데이터를 메모리에 올려두고 써야 하는 것도 부담이었습니다. 물론 요청할때마다 수 GB 씩 fetching 하는 것은 아니지만, 분명 그럴 일이 나중에 있을 것이라 생각했습니다.
- DB LINK Redshift ↔︎ PostgreSQL(DATA MART) by Procedure
Stored Procedure 를 만들어 DB 링크로 데이터를 빨아드리는 방법이 좋겠다는 생각이 들었습니다.
수백만 로우를 가지고 오는데 1분 정도면 충분했습니다. 프로시저는 그 프로시저 만의 단점들이 있지만, 극복 가능한 단점이라고 생각이 들었습니다.
프로시저의 단점
우리 프로시저는 매우 단순했지만, 모든 액션이 반드시 성공한다는 보장은 없습니다. 프로시저는 어디서 오류가 났는지, 무슨 에러 중인지 알기가 쉽지 않습니다. 그래서 최대한 짧게 짧게 프로시저를 여러개 만드는 것을 고민 했습니다.
그래서 우리가 레드시프트와 동기화 해야 하는 테이블을 8가지 섹션으로 분류했습니다.
-
Facebook
-
Metric Section
-
페이스북 광고 리포트
-
페이스북 액션 리포트
-
페이스북 액션 가치 리포트
-
페이스북 사용자 일별 리포트
-
-
Resource Section
-
페이스북 캠페인
-
페이스북 광고 세트
-
페이스북 광고
-
페이스북 광고 소재
-
광고 소재 Many to Many Relations
-
페이스북 에셋
-
-
-
Google
-
Metric Section
-
구글 광고 그룹 리포트
-
구글 캠페인 리포트
-
구글 키워드 리포트
-
구글 키워드 전환 리포트
-
-
Resource Section
-
구글 캠페인
-
구글 광고그룹
-
구글 광고
-
구글 미디어 파일
-
구글 소재
-
-
-
Naver
-
Metric Section
-
네이버 광고 리포트
-
네이버 광고 전환 리포트
-
네이버 캠페인 리포트
-
네이버 광고 그룹 리포트
-
네이버 키워드 리포트
-
네이버 광고 전환 리포트
-
네이버 쇼핑 상품 리포트
-
-
Resource Section
-
네이버 캠페인
-
네이버 광고그룹
-
네이버 광고
-
-
-
Kakao
-
Metric Section
- 카카오 에셋 리포트
-
Resource Section
-
카카오 캠페인
-
카카오 광고 그룹
-
카카오 에셋
-
-
각 매체당 2개씩 총 8개의 섹션 입니다.
DBLINK를 만들어 줍니다.
CREATE EXTENSION postgres_fdw;
CREATE EXTENSION dblink;
CREATE SERVER redshift_prd
FOREIGN DATA WRAPPER postgres_fdw
-- 매드업엔 SSH터널링 툴인 매드터널이 있는데 여기는 진짜 Redshift Private IP 를 넣어줍니다.
OPTIONS (host '<amazon_redshift _ip>', port '<port>', dbname '<database_name>', sslmode 'require');
편의점이냐.. 마트이냐..?
Data Mart를 구축하려고 했는데 편의점을 구축해야.. 하지 않을까? 테이블안에 컬럼이 너무 많습니다. 하지만, 필요한 컬럼만을 추릴려고 하니, 나중에 다시 필요해 졌을때 테이블 구조를 변경하거나, 프로시저를 변경하기 쉽지 않을 것 같아서, 우선 다 수집하기로 했습니다. DB Link 쿼리는 DB 입장에서 보면 나한테 메타데이터가 없는 테이블을 쿼리하는 것이고 이렇다면 일일히 다 쿼리 하는 컬럼의 데이터 타입을 지정해야 합니다.
아래와 같이요.
SELECT *
FROM dblink('redshift_prd',$REDSHIFT$
SELECT sellerid, sum(pricepaid) sales
FROM sales
WHERE saletime >= '2008-01-01'
AND saletime < '2008-02-01'
GROUP BY sellerid
ORDER BY sales DESC
$REDSHIFT$)
-- 여기 아래 정의 해줘야 합니다. 우리 코끼리DB는 Redshift에 어떤내용이 정의된지 모릅니다.
AS t1 (sellerid int, sales decimal);
수십개나 되는 컬럼에 일일히 이 프로시저를 만들 수가 없기 때문에 파이썬 파일로 프로시저를 자동으로 생성해주는 코드를 만들어 보기로 합니다. 그렇다면 나중에 내가 없어도 이 파일로 수정할 수 있으니까요.
엔지니어는 기본적으로 내가 지금 죽고 없어져도 유지되는 시스템을 만들어야 한다고 생각하니, 유지보수 할 수 있도록 프로시저 제너레이터를 만들었습니다.
기본 개념은 다음과 같습니다.
-
데이터베이스(데이터마트) 를 Redshift 와 동일하게 스키마를 만들어 줍니다.
- Redshift는 매체에서 주는대로 저장하기 때문에 컬럼 이름에 .(period) 가 들어갈 수 있지만, 저희는 전부 그것을 _(underscore)로변환 했습니다.
-
우리 Database metadata를 기준으로 어떤 컬럼이 어떤 데이터 타입을 가지는지 이제 우리는 알 수 있습니다.
-
모델 파일에 있는 모든 클래스를 불러옵니다.
-
그리고 그 클래스로 가서 어떤 컬럼이 있고 어떤 데이터 타입을 가지는지 확인합니다.
그렇게 쿼리를 statement를 만듭니다.
for exc in inspect.getmembers(m, inspect.isclass):
if exc[0].endswith("DM") and exc[0] not in FACEBOOK_EXCEPT:
if getattr(m, exc[0]).__table__.name in create_target.get(target):
vars.append(exc[0])
preassigned_kwarg = ["end", "enable"]
redshift_query_stmt = ""
for v in vars:
model = getattr(m, v)
columns = [c.name for c in model.__table__.columns if c.name not in ["created_at", "updated_at", "id"]]
for i, col_ in enumerate(columns):
if col_ in preassigned_kwarg:
columns[i] = f""""{col_}" {col_+"ed"}"""
redshift_query_stmt += f"""
{v.lower()}_remote_sql = format('
SELECT {", ".join(columns)}
FROM {model.__table__.name.removesuffix("_dm")}
WHERE collected_at >= %L
and collected_at <= %L
and {account_id if 'all' not in model.__table__.name or not target.startswith("naver") else 'customerid'} in (%s)
', start_date_string, end_date_string, ids);
"""
preassigned_kwarg 는 Redshift, 또는 PostgreSQL 에서 사전 정의된 키워드 입니다. end 같은 것은 컬럼이름으로 사용할 수 있지만, “end” 이렇게 쿼리 해줘야 합니다. 왜냐하면 SQL 언어이기 때문입니다. 저런 소소한 ETL을 타이트하게 해줍니다.
CREATE OR REPLACE PROCEDURE rs_{target}_dumps(
account_ids varchar default '0',
start_date varchar default null,
end_date varchar default null
)
language plpgsql
as $$
declare i record;
declare k record;
declare start_date_string text;
declare end_date_string text;
declare ids text;
{declare}
begin
ids := '';
IF account_ids = '0' THEN
raise notice 'is 0';
-- 0일땐 모든 광고계정 모두! 현재 페이스북 기준 약 400여개 하지만 Redshift에는
-- Lever 에서만 광고하는 광고주만 계신 것이 아니기에 조회할 것만 뽑아서 스트링으로 만들어줍니다.
FOR k in (SELECT distinct {account_id} from {account_table})
LOOP
IF LENGTH(ids) = 0 THEN
-- '12345', '12347', '12399' 이런 형태로 만드는 작업입니다.
ids = concat('''', k.{account_id}, '''');
ELSE
ids = concat(ids, ', ', '''', k.{account_id}, '''');
end if;
end loop;
ELSE
FOR k in (SELECT distinct {account_id} from {account_table} where {account_id} in
(SELECT account_id FROM unnest(string_to_array(account_ids, ',')) account_id)))
LOOP
IF LENGTH(ids) = 0 THEN
ids = concat('''', k.{account_id}, '''');
ELSE
ids = concat(ids, ', ', '''', k.{account_id}, '''');
end if;
end loop;
end if;
IF end_date is null then
end_date_string = to_char(now(), 'YYYY-MM-DD');
else
end_date_string = end_date;
end if;
IF start_date is null then
start_date_string = to_char(now() - INTERVAL '{days} DAY', 'YYYY-MM-DD');
else
start_date_string = start_date;
end if;
위에 보시면 {target} {declare} {account_id} {account_table} {days} 이렇게 5개가 Python f string 완성을 위해 이렇게 정의 되어 있습니다. 맞습니다. 위 프로시저 도입부는 변수에 따라 자동으로 작성되는 f string입니다.
-
target프로시저의 고유의 이름을 만들기 위한 변수 입니다. -
declare부분에는 프로시저에서 사용할 변수 이름등이 정의되고 -
account_id는 각각 매체마다 사용하는 광고계정 이름을 사용합니다. 카카오와 페이스북은account_id, 구글과 네이버는customer_id라는 이름을 사용합니다. -
account_table은 각 광고계정이 적재된 데이터마트 DB에 있는 테이블 이름입니다. -
days는start_date와end_date를 둘다 넣지 않았을 경우 기본 몇일을 수집하게 될 프로시저를 만드는가를 결정하는 변수 입니다.
그리고 저는 account_ids에 “1234,4567” 이렇게 오면 1234 와 4567 광고계정만을 검색하고 싶고, 수집하는 시작일과 종료일도 설정하고 싶습니다. 그래서 변수로 account_ids 와 start_date와 end_date를 받아줍니다.
create_target = {
"facebook_metric": [
"facebook_ad_seg_daily_report_dm",
"facebook_ad_action_seg_daily_report_dm",
"facebook_ad_action_values_seg_daily_report_dm",
"facebook_ad_seg_user_daily_report_dm",
],
"facebook_resource": [
"facebook_campaign_dm",
"facebook_ad_set_dm",
"facebook_ad_dm",
"facebook_ad_creative_dm",
"facebook_creative_asset_rel_dm",
"facebook_asset_dm",
],
"naver_resource": [
"naver_all_campaign_list_dm",
"naver_all_adgroup_list_dm",
"naver_all_ad_list_dm"
],
"naver_metric": [
"naver_ad_stat_report_dm",
"naver_ad_conversion_stat_report_dm",
"naver_campaign_master_report_dm",
"naver_adgroup_master_report_dm",
"naver_keyword_master_report_dm",
"naver_ad_conv_report_dm",
"naver_shopping_product_master_report_dm",
],
"kakao_resource": [
"kakao_creative_report_dm"
],
"kakao_metric": [
"kakao_all_campaign_list_dm",
"kakao_all_ad_group_list_dm",
"kakao_creative_report_dm"
],
}
target = "facebook_resource"
이렇게 만든 프로시저는 위 처럼 target변수만 create_target 딕셔너리가 있는 키값으로 바꿔주면 스스로 알아서 해당 이름의 테이블만 골라서 프로시저를 만들게 됩니다.
구글은 아쉽게도 따로 파일을 만들어야만 했습니다. Data Warehouse 에서 매체에서 주는 그대로 가지고 오는 바람에 table 명에 . (period) 가 들어가 있었습니다. ETL를 격하게 해야 하기 때문에 새로운 프로시저 생성 코드를 짤 수 밖에 없었습니다.
짧게 소개 하자면,
google_ad.ad.ad_report 이런 형식으로 컬럼이름에 대중없이 Period 가 찍혀 있었습니다. 도저히 규칙을 찾아내지 못하여, Redshift 테이블 명을 복사해서 리스트로 만들었습니다.
google_ads_ad_group_ad_keyword_conv_seg_report = [
"campaign.advertising_channel_type",
"campaign.advertising_channel_sub_type",
"customer.id",
"customer.descriptive_name",
"campaign.name",
"campaign.id",
...
"ad_group_ad.ad.final_mobile_urls",
"ad_group_ad.ad.final_url_suffix",
"ad_group_ad.ad.final_urls",
"ad_group_ad.ad.id",
"segments.external_conversion_source",
"segments.conversion_action",
"segments.conversion_action_category",
"segments.conversion_action_name",
"segments.date",
"metrics.all_conversions",
"metrics.all_conversions_value",
"collected_at"
]
우리 DM 테이블 컬럼은 저 Period를 모두 Underscore로 변경했기 때문에 우리 테이블 명도, Redshift 테이블 명도 모두 Underscore를 Period로 변경했습니다.
"segments.external_conversion_source" → "segments.external.conversion.source"
그렇게 해서 해시맵을 만들었습니다.
{segments.external.conversion.source": "segments.external_conversion_source"}
이렇게 해서 DM 에 정의된 SQLAlchemy 모델에 정의된 컬럼 이름만으로 Redshift 컬럼 이름을 찾을 수 있었습니다. Redshift 에 접근해서 메타데이터를 받아 올수도 있는데, 쿼리를 해야 함은 물론, 받은 계정에 그곳에 접근 가능한 Access Clearance가 없었기에 이렇게 구현해 냈습니다.
sync_query_stmt += f"""
raise notice '% has started', '{model.__table__.name}';
FOR i in SELECT
*
FROM dblink('redshift_prd', {v.lower()}_remote_sql)
AS t1 (
{", ".join([" ".join(x.split(" ")[-2:]) for x in map_])}
)
LOOP
INSERT INTO
{model.__table__.name}
(
created_at,
updated_at,
{", ".join(dm_name)}
)
VALUES (
current_timestamp,
current_timestamp,
{", ".join(['i.' + k[0] for k in dw_name])}
);
end loop;
"""
위는 DBLink로 Redshift로 보내는 쿼리를 생성하는 부분 입니다.
여기 까지 오는데 사전 작업을 완전 빡세게 한 이유는, Redshift에 쿼리하는 그 쿼리 스테이트먼트 안에 데이터마트 테이블 레코드를 참조 할 수 없었습니다. 이게 Redshift table인지 PostgreSQL table인지 구별을 하지 못합니다. 그래서 사전작업으로 계정 ID 들도 날짜도 text 형태로 다 가공했습니다.
스캐줄러를 만들어 호출
이건 어디서 어떻게 스캐줄러를 만들어 호출해도 좋습니다. 앱에서 해도 되고, 람다로 해도 되고, 무엇으로든 하면 됩니다.
우선 Metrics를 서빙할 앱에 스캐줄러를 구현했습니다.
아래와 같은 Scheduled Job을 정의하고 스캐줄을 관리할 테이블을 만듭니다.
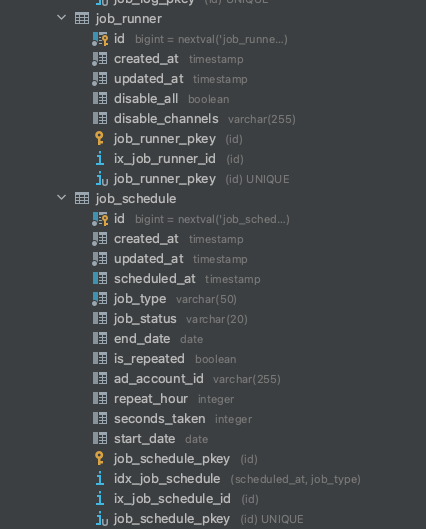
과거에 람다로 Job을 관리할 때도 비슷한 테이블이 있었는데 운영을 하다보니, 지금 수행중인 프로세스를 제외하고 새로 시작하는 모든 Job을 중지하고 싶은 Needs가 있었습니다. 그래서 job_runner 테이블을 만들어서 관리하기로 했습니다.
job_type과 job_status는 Enum이지만, 데이터베이스 native enum은 Fail Point를 늘리기 때문에 사용하지 않았습니다. 이제 스캐줄러를 만들고 드디어 대망의 자동 수집을 시작합니다.
뜻 밖에 복병
사실 8개의 섹션으로 나눈 본능적인 이유에는 프로시저를 작게 쪼갠다는 의미가 가장 큽니다. 작게 쪼개야 한 번에 실행하는 시간도 짧아집니다. 짧아져야, 데이터마트 DB 세션도 너무 길게 잡고 있지 않고, Redshift 에도 우리가 왔다갔다는 흔적이 덜 남게 되기 때문입니다. 하지만, 그 모든 예상을 차치하고, 이것이 신의 한 수가 되는 순간이 여기서 옵니다.
스캐줄을 마구마구 등록해 시작해보니, 서로서로 ShareUpdateExclusiveLock을 걸어 물고 물리는 대전이 일어났습니다.
아래는 PostgreSQL에서 현재 락 현황을 조회할 수 있는 쿼리 입니다.
SELECT
t.relname, l.locktype, page, virtualtransaction, pid, mode, granted
FROM
pg_locks l, pg_stat_all_tables t
WHERE l.relation = t.relid
ORDER BY relation ASC;
곰곰히 생각을 했습니다. 그리고는, 8개 섹션은 고유하게 돌아가는 형태로 구현했습니다.
Facebook Metrics 수집 중에 Google Metrics 수집은 가능하지만, 또 다른 Facebook Metrics 수집은 못하게 막았습니다. 현재 매 시간 1번씩 수행되는 Job이 처리되는 시간은 아래와 같습니다.
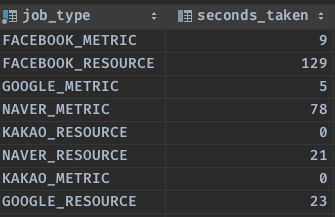
23시경이라고 적었습니다. 하루의 데이터를 가지고 오는데 23시면 사실 그 날 가지고오는 쿼리 중 가장 데이터가 많은 쿼리 일 것입니다. 아침은 더 적겠죠?..
하지만, 데이터가 많아지면 더 느려질까? 글쎄요. 저는 그렇지 않을 것이라 봅니다.
물론 시간 차이는 있겠지만, 눈에 띄는 차이를 줄려면 지금보다 10배 이상은 데이터가 많아져야 할 것이라고 생각합니다. 데이터 양에 따른 소요시간은 뒤에서 다룰 예정입니다.
이렇게 해서 테이블 락을 해결했습니다.
조금더 세세하게 하려면, 지금 데이터 업데이트를 collected_at과 account_id 기준으로 하고 있는데, 2 개만 겹치지 않으면 사실 한 테이블에서 여러 스캐줄러가 작동해도 문제 없습니다. 우리는 프로시저가 작동될 때 이미 어떤 Row를 어떻게 바꿀지 알고 있으니까요. 하지만 이것은, Todo로 남겨서, 2차전에 해결하도록 하고 우선은 이렇게 만들었습니다.
두번째 복병 아닌 복병
끝이라고 생각했을때, 그때가 시작이었습니다.
왜 매번 걸리는 시간이 다를까? Redshift Query시간은 거의 항상 비슷한데, 왜 데이터를 적재하는 시간에서 차이가 이렇게 날까? 많이 나면,, 20~30% 이상? 대체 왜그럴까 고민했습니다.
PostgreSQL에는 Vacuum 이라는 개념이 존재 합니다. PostgreSQL에만 존재합니다. Oracle MariaDB, MySQL, MS-SQL 어디에서도 찾아볼 수 없는 개념이기에 이걸 그냥 간과해버리면, 트랜젝션이 늘어났을 경우 예상과 다르게 행동하는 DB를 보고 PostgreSQL에게 실망(?) 하실 수도 있습니다.
Vacuum 또는 AutoVacuum 이라고 하는데, 말그대로 청소를 하는 것 입니다.
대체로, 2가지 상황에서 작동을 시작합니다.
-
TXID Wraparound 를 방지하기 위해 TXID를 Freeze 할때 입니다. 말은 엄청 어렵지만 개념은 단순합니다. 지금 만난 복병의 상황은 이 상황이 아니기 때문에 이 링크로 대체 합니다. https://www.postgresql.org/docs/9.4/routine-vacuuming.html#VACUUM-FOR-WRAPAROUND Preventing Transaction ID Wraparound Failures 파트를 읽어보시면 왜 주기적으로 이런 행동을 하게되는지, 이런 문제가 생기면 어떻게 되는지 설명되어 있습니다.
-
두 번째 상황은, PostgreSQL에 설정된 임계값 이상의 Dead Tuple 이 발생하게 되면, 이 Dead Tuple 들을 클리닝 하기 위해 AutoVacuum 이 시작됩니다.
이것을 잘 이해하려면 Dead Tuple 이 무엇인지 알아야 하는데, PostgreSQL에는 모든 정보가 Tuple로 저장됩니다. 튜플은 Live Tuple 과 Dead Tuple 로 나뉩니다. 더 이상 참조되지 않는 Tuple이 바로 Dead Tuple 입니다. PostgreSQL*이 MVCC를 사용하면서 여러 버전을 가지고 있기 때문에 생기는 현상입니다.
Row의 여러 버전을 가지고 있으려면? 당연히 기존 Row를 delete 하거나 update 하면 발생하게 됩니다.
PostgreSQL 에서 Update를 하거나 Delete를 하면 아래처럼 작동합니다.
-
FSM** 공간 확보
-
FSM 에 새로운 데이터 쓰기
-
해당 Row/Column 를 바라보고 있는 포인터를 새로 작성한 데이터로 바꾸기.
-
헛? 그렇다면 기존에 포인팅 되고 있던 Row/Column 데이터는..? 이게 바로 Dead Tuple이 됩니다.
PostgreSQL* AWS RDS PostgreSQL은 MVCC(다중버전 동시 제어성)를 사용합니다.
https://aws.amazon.com/ko/blogs/database/understanding-autovacuum-in-amazon-rds-for-postgresql-environments
FSM** Free Space Map
“아, 일단 알겠고, 데드 튜플이 늘어나면 청소한다는 거지?”
맞습니다. Live Tuple 대비 Dead tuple 수가 20% + 50개가 초과하면 Auto Vacuum이 돌기 시작합니다. (20%는 PostgreSQL 기본 값이고, AWS RDS Postgres는 10%가 기본값입니다.)
조금 더 쉽게 말해, 1000개의 데이터가 있는데, 250개의 Dead Tuple 이 있다면? 청소를 시작합니다. 그런데, 이게 왜 복병일까요? Full Vacuum은 Table Lock이 걸리기 때문에 아무것도 할수가 없지만 Auto Vacuum은 기본적인 액션은 제약 없이 계속해서 테이블 사용이 가능합니다(Truncate, Indexing 등은 불가).
오토베큠 설정을 글로벌로 할수도 있지만, 개별 테이블에 섬세하게 작업해 줄 수 있습니다. Dead Tuple 의 비율로 하게 되면 테이블마다 Vacuum에 걸리는 시간도, 리소스도 모두 다르게 됩니다. 그래서 몇가지 종류를 사전에 만들어서 테이블 별로 세팅 했습니다. 여기서 테이블을 파티셔닝 하면, Autovacuum이 파티셔닝된 테이블 단위로만 작동합니다!
아래처럼 설정 하면, Dead Tuple 0% + 20만개 인 경우이니 항상 비슷한 로드를 가진 오토베큠이 돌 수 있도록 처리가 가능합니다. 그래서 이렇게 처리했고, 베큠은 코스트 제한이 있어서(기본값 200) 다 정리를 못해도 코스트를 모두 소진하면 그만 두게 되있습니다.
(autovacuum_analyze_scale_factor = 0.0, autovacuum_vacuum_threshold = 200000)

우리 데이터 마트 DB는 일반적으로 사용하는 DB 같이 사용하지 않고 주기에 맞춰 모든 리소스(CPU, Memory 등)을 총 동원하여 데이터 싱크를 맞춥니다. 사전에 설정된 RDS 기본 세팅은 대부분의 환경에 잘 돌아가게 정의된 값이지, 우리의 목적에 맞게 세팅된 것은 아니라는 생각이 들었습니다.
-
autovacuum_vacuum_cost_delay
-
autovacuum_vacuum_cost_limit
위 두 옵션이 있는데, Vacuum 을 더 빠르게 할수 있습니다. 자주 할수도 있고요. Auto Vacuum 중에는 당연히 청소 안할때보다 퍼포먼스가 약간 줄어 듭니다. 그래서 청소를 시기적절하게 잘 할수 있도록 전략을 강구하시면 더 효과적으로 코끼리를 사용하실 수 있을 것이라 생각합니다.
Vacuum setting은 다음과 같이 확인할 수 있습니다.
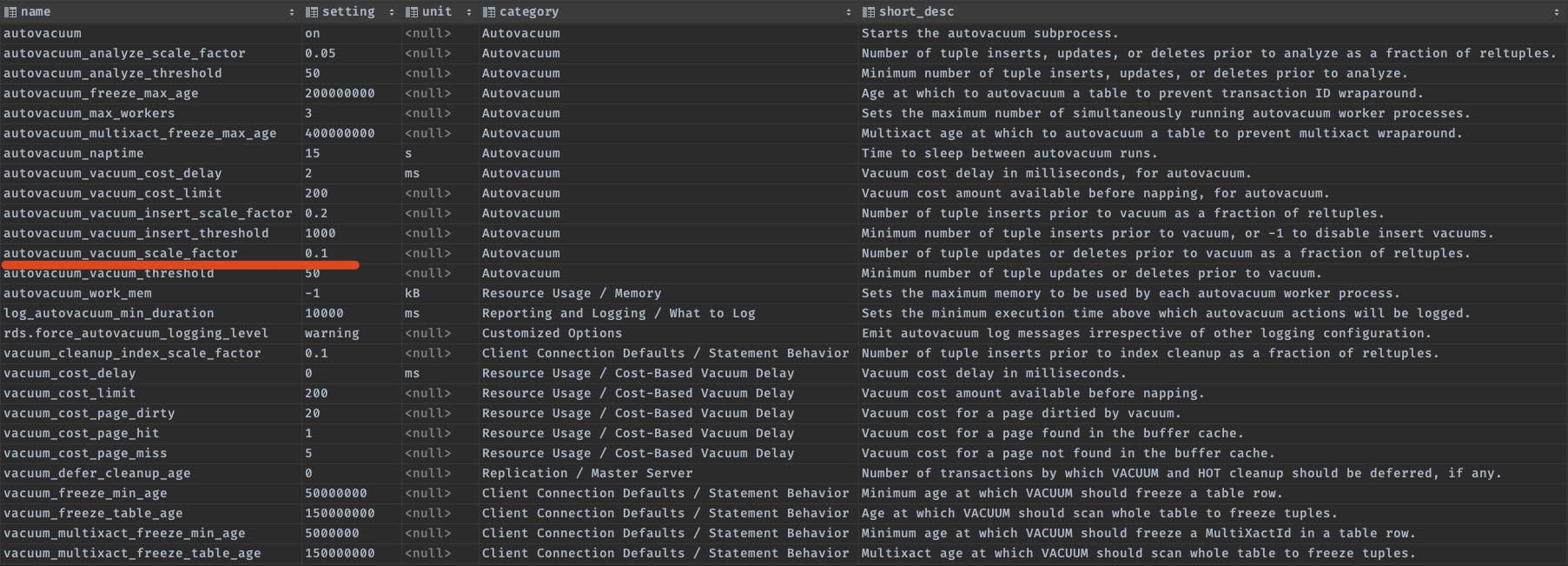
SELECT *
FROM pg_settings
WHERE name LIKE '%vacuum%';
현재 Dead Tuple 과 Live Tuple 현황은 아래 쿼리로 한번 확인해보세요.
FROM pg_stat_all_tables AS s
JOIN pg_namespace AS n
ON s.schemaname = n.nspname
JOIN pg_class AS t
ON t.relname = s.relname
AND t.relnamespace = n.oid
WHERE t.reltuples <> 0 and GREATEST(s.n_dead_tup::float8 - 50.0, 0) / t.reltuples <> 0
ORDER BY dead_ratio DESC;
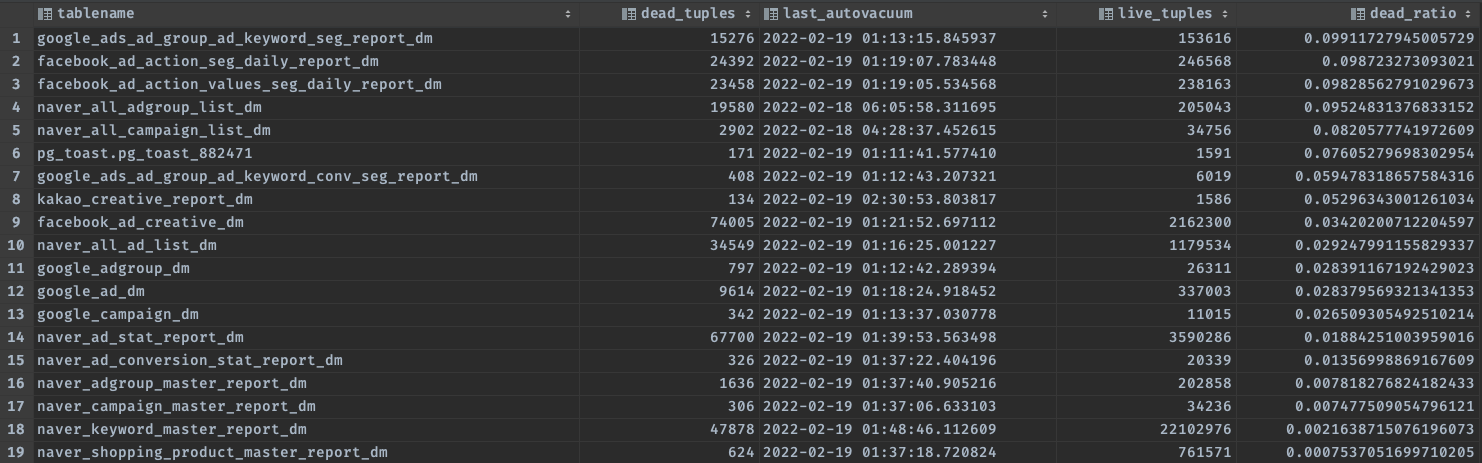
dead_ratio 가 0.1이 넘으면 코끼리가 알아서 청소기를 돌립니다. 청소시간은 길게도 할 수 있고 짧게도 할 수 있습니다. 그 설정 값은 어느정도의 Dead Tuple을 견딜 수 있는 하드웨어이냐가 관건입니다. 이 Auto vacuum 시간 동안 성능 저하를 경험할 수 있습니다. 그래서 이 시간을 보장해주기 위해 스캐줄러를 실행하기전에 해당 테이블이 Vacuum 중인지 확인 하고 vaccuum 중이면 다시 스케줄링 하도록 하였습니다.
수집시간
레버의 모든 광고주 데이터 1주일 분량 수집 시간 (약 500~700만 Rows) - FB, Google
구글 메트릭 : 21초
구글 리소스 : 85초
페북 메트릭 : 76초
페북 리소스 : 7분 25초
레버의 모든 광고주 데이터 2주일 분량 수집 시간 - FB, Google
구글 메트릭 : 30초 (+9초)
구글 리소스 : 96초 (+11초)
페북 메트릭 : 94초 (+18초)
페북 리소스 : 8분 30초 (+1분 5초)
1주일 치 수집 페이스북 리소스 파트를 뜯어보겠습니다.
프로시저에 raise notice를 통해서 내부 수행을 어디까지 했는지 알리게 해두었습니다.
[2022-02-17 19:20:06] [00000] facebook_ad_creative collection has started (4분 18초걸림)
[2022-02-17 19:24:23] [00000] facebook_ad_dm has started (1분 30초 걸림)
[2022-02-17 19:25:53] [00000] facebook_ad_set collection has started (24초 걸림)
[2022-02-17 19:26:17] [00000] facebook_asset collection has started (46초 걸림)
[2022-02-17 19:27:03] [00000] facebook_campaign_dm collection started (3초 걸림)
[2022-02-17 19:27:06] [00000] facebook_creative_asset_rel collection has started (26초 걸림)
[2022-02-17 19:27:32] completed in 7 m 25 s 858 ms
소재 데이터가 가장 많습니다. 일단 일주일치 한번 쿼리하면 기본 30~40만 Row씩 잡힙니다.
오래 걸리는 스캐줄러들은 지속적으로 모니터링 하여 여러개의 프로시저로 쪼갤 예정입니다.
아주~ 쉽게! 우리에겐 프로시저 제너레이터가 있으니까요!
Redshift 부하는요…?
이제야 어떻게 사용해야 하는지 대충 감이 옵니다. Redshift는 와장창 데이터를 크게크게 퍼가는 것을 더 좋아하는 친구였습니다. 여러번의 쿼리 보다는 큰 쿼리를 좋아합니다. 그래서 어플리케이션 레벨에서 그 데이터를 잘 가공해서 사용하시면 될 것 같습니다. 제가 초반에 보여드렸던 EXPLAIN을 보시면, JOIN도 썩 좋은 아이디어가 아니라고 생각합니다.
현재 이렇게 바꾸고 Redshift는 평화롭습니다.
Procedure Watchtower
이제 가장 처음으로 드는 생각은 프로시저를 감시해야 한다는 생각 입니다. 단순한 프로시저지만, 성공이 100%일리가 없습니다. 프로시저는 내부 SQL Syntax 오류가 생겼을 경우 또는 Redshift, PostgreSQL 에 스키마가 예고 없이 변경된 경우 try… except 구문에서 잡힐 것 입니다. 하지만 그 것이 아니라 아래 같은 경우가 더 문제 입니다.
-
자기가 데드락인지도 모르고 Long Running 하는 프로시저
-
REDSHIFT 쿼리 시간이 지연되는 경우
평균시간 보다 오래걸리는 프로시저 처리하기
우리 job_schedules 테이블에 보면 seconds_taken 이라는 컬럼이 있습니다. 직전 수행시간을 적어 둡니다. 그보다 현저히(아직 정확한 수치는 테스트중) 길어 질 경우 아래와 같은 명령어로 해당 PS 찾을 수 있습니다.
select pid, query from pg_stat_activity where state = 'active';
pid | query
---------------------------------------------------------------------------
21221 | select pid, query from pg_stat_activity where state = 'active'
24292 | call collect_facebook_metrics('12345678')
우리는 job_schedules 에 있는 내용으로 해당 PID 를 찾을 수 있고 종료시킬 수 있습니다.
SELECT pg_cancel_backend('12345678');
SELECT pg_terminate_backend('12345678') FROM pg_stat_activity;
pg_cancel_backend 는 해당 PID만 단순하게 죽입니다.
pg_terminate_backend 는 해당 PID와 연관된 모든 상위 연관 Query Process를 죽입니다.
이제 고민해서 정책을 만들어야 합니다.
-
직전 수행시간의 3배 시간이 넘은 순간 Slack Notification 발송
-
DB 정기 유지보수 타임 Job 구동 제외
-
5배가 넘은 순간 Kill 후 해당 job을 리스캐줄
-
연속 실패시 카카오톡 알림 후 리스캐줄링 후 5분간 해당 Job_type 구동금지 반복
프로시저 세부 모니터링
우리는 DB는 서버의 요청을 받기만 한다고 생각합니다. 하지만, PostgreSQL은 프로시저 실행 중간중간에 어디까지 실행했는지 HTTP call을 서버에게 보낼 수 있습니다. 한 프로시저에서 여러 테이블을 동기화 하니 어떤 테이블에서 문제가 생겼는지 알기 위해 동기화 시작전에 Rest call을 서버에게 주도록 설계합니다. 그래봐야 몇번 안되니까요.
PostgreSQL에서는 여러가지 익스텐션을 이용해서 원하는 언어로 함수를 만들 수 있습니다. Python으로 만든 예시를 볼까요?
CREATE OR REPLACE FUNCTION public.py_pgrest(p_url text, p_method text DEFAULT 'GET'::text, p_data text DEFAULT ''::text, p_headers text DEFAULT '{"Content-Type": "application/json"}'::text)
RETURNS text
LANGUAGE plpython3u
AS $function$
import requests, json
try:
r = requests.request(method=p_method, url=p_url, data=p_data, headers=json.loads(p_headers))
except Exception as e:
return e
else:
return r.content
$function$;
하지만 RDS에서는 plpython3 를 지원하지 않습니다. 지원하는 언어나 익스텐션을 보시려면 아래 명령어를 사용해보세요. 길게~ 여러개가 나옵니다.
show rds.extensions;
PLPerl을 지원하긴 하지만… RestCall을 하려면 Perl에서도 Rest::Client 모듈을 사용해야 합니다..
AWS 가 이것을 허용해줄 리가 당연히 없습니다. RDS는 이것을 제대로 구현하기 어려웠습니다.
어찌지..? 하다가 문득 생각 났습니다. AWS는 또 그들의 서비스는 그 안에서 잘 연계해 두었기에, 한번 찾아봤습니다.
신기하게도 aws_lambda 익스텐션이 있었습니다.
CREATE EXTENSION IF NOT EXISTS aws_lambda CASCADE;
CREATE EXTENSION IF NOT EXISTS aws_commons CASCADE;
작업 순서는 다음과 같습니다.
-
Lambda 함수를 만듭니다.
-
람다와 Redis가 Private IP로 서로 접근할 수 있도록 같은 VPC 안에서 작동할 수 있게 해주세요.
-
RDS를 위한 람다 접근이 가능한 IAM 정책을 만들어 줍니다.
-
이 IAM 정책을 가지고 IAM Role(역할)을 만듭니다.
-
이 Role을 RDS에 부여합니다.
-
그리고 아래처럼 호출합니다.
SELECT * FROM aws_lambda.invoke(
:'data-convenience-store-error-123',
'{"body": "헐 facebook_ad 테이블 업데이트 못했어 도와줘!"}'::json
);
아래 문서에 매우 자세한 내용이 담겨 있습니다.
https://docs.aws.amazon.com/ko_kr/AmazonRDS/latest/UserGuide/PostgreSQL-Lambda.html
중요한것은!
이렇게 하면 문제가 생겼을때 어떤 테이블에서 문제가 생겼는지 단숨에 알수 있습니다. 프로시저 내에서 UPDATE로 db 내용을 바꾸는 것은 어렵습니다. 트랜젝션으로 묶여있기 때문입니다. 할 수는 있겠지만, DB 테이블이 아니라 DB 용량등의 문제가 생긴다거다 그 보다 더 상위 레벨에서 문제가 생겼다면, 제대로 인포를 전달할 수 없기 때문에 Redis에 넣어서 분리 보관해줍니다. 어짜피 시간이 지나면 필요없어지는 로그들이니까요.
추후 조금 더 고도화 하면 실패한 테이블 부터 시작하도록 할 수 있습니다.
이 프로시저 모니터링이 배보다 배꼽이 더 큰거 아닌가요?
아.. 아마도.. 그럴 수도 있습니다…. 라고.. 저는 생각합니다… 하지만 그 어떠한 스캐줄러라도 모니터링 도구는 필요합니다. 단순한 작업이라도 매번 성공한다는 보장은 없으니까요. 이렇게 모니터링을 할 수 있다는 것 만으로도 상당히 만족합니다. Sustainability 측면과, 처음에 해결하고 싶었던 문제인 “데이터를 더 잘 쌓고” “더 잘 조회될 수 있는” 시스템을 위한 목적 달성에 일부라고 생각합니다.
고도화
1 라운드가 끝나갑니다. 다음 라운드에서 무엇을 해야 하는지 생각해 볼 시간입니다. 우선 가장 마음에 걸리는 것은 적재방법 입니다. Insert After Delete 이기 때문입니다. update 하고 Redshift에서 없어진 데이터를 어떻게 삭제 해주느냐 의 좋은 방법을 찾는 것이 다음 순서가 될 것입니다.
적재방법
Best Practices 는 현재 데이터를 적재하고 있는 전략을 우선 파악해 보아야 하겠지만, 한 가지 확실한 것은 지금 방법이 Best는 아닐 것 이라는 사실 입니다. 지우고 다시 데이터를 주입하는 순간 테이블은 제가 설정해 둔 인덱스를 다시 정리하기 시작할 것입니다. 그리고 시간이 지나면서 인덱스의 데이터가 파편화 되어 데이터베이스 내에 흩어지게 될것입니다. 그럴때 마다 유지보수를 해주어야 하겠지요. PostgreSQL 은 파티셔닝된 테이블의 리인덱스나 Partioned Indexing을 지원하지 않습니다. 파티션 별로 리인덱싱 해줘야 합니다.
또한, Delete 되는 양이 많아지면 많아질 수록 Vacuum 하는 시간도 오래 걸릴 것입니다. 그래서 저는 지우지 않고 업데이트 하고 싶었습니다. 이는 Redshift 가 현재 데이터를 쌓는 로직에 대해 더 자세한 내용을 공유받아 진행할 예정입니다. 추가적인 혜택(?) 으로는 Delete-Insert 가 아닌, 업데이트를 하면 Cursor를 통해 Pagination이 가능해집니다.
그래서, 뭐가 얼마나 좋아졌어요?
쿼리 시간 단축과, 필요한 데이터를 언제든지 호스를 꽂아 빨아 당겨 사용할 수 있다는 든든함!
Athena를 이용할때 1개의 광고주 페이스북 리소스를 수집하기 위해, Lambda Max Life Span인 900초를 넘겨서 다음 스케줄러로 이관, 이관, 이관 해서 끝도 없이 람다가 돌았습니다. 이제, 20초면 최신 매체에 접근 없이도 광고주 모든 데이터를 최신화 할 수 있습니다.
♾️ → 20초 (퍼포먼스 상승 ♾️ %)
레드시프트 쿼리과 비교하면,
캐시되지 않은 약 10분 소요되는 쿼리 → 30초, 덤으로! 필요한 데이터 프리컴퓨테이션 가능,
실제 쿼리 시간 → Instant!
이제 우리 애플서치로 매체 확장을 해볼까요?
프로시저 제너레이터로 하나만 더 만들면 모든 데이터 준비 끝!
2탄 예고, 한달에 2300만 Row 적재되는 뚱뚱이 테이블 파티셔닝