어서 와, 광고 데이터 수집은 처음이지? (feat. kraken)
이번 글에서는 매드업의 DMP 프리즘의 일부인 크라켄을 소개합니다. 크라켄은 매드업에서 구축한 데이터 수집 플랫폼입니다. API 호출 제약이 상대적으로 빡빡한 매체의 데이터 수집을 담당합니다. API 호출 제약으로 인해 어떤 어려움이 있었는지, 그리고 크라켄은 어떻게 이런 어려움을 극복했는지 알아보겠습니다. 비개발자도 편하게 읽으실 수 있도록 기술적인 내용은 후반부에 짧게 다룹니다.
어서 와, 광고 데이터 수집은 처음이지?
구글, 페이스북, 트위터 등 광고 매체로부터 데이터를 내려받는 가장 쉬운 방법은 무엇일까요? 아마도 매체 사이트에서 그들이 제공해주는 data export 기능을 통해 다운로드하는 것 일 겁니다. 하지만 쉬운만큼 사람이 직접 몇 번의 클릭을 해야 하는 등 시간을 투자해야 한다는 단점이 있습니다. 그리고 매우 루틴 한 작업임과 동시에 필터 조건 등 생각 없이 클릭하면 데이터가 기존과 달라질 수도 있습니다.
프로그래밍을 할 줄 안다면 매체에서 제공해주는 API를 사용하는 것도 아주 좋은 방법입니다. API 호출을 구현하면 언제 어떤 환경에서든 필요한 데이터를 자동으로 다운로드할 수 있습니다. 아, 물론 우리 쪽 서버 자원(비용)은 조금 들겠지만요. 하지만 고급 인력(AE)이 데이터 다운로드를 위해 사이트에서 이것저것 클릭하는 시간/비용보다는 저렴할 겁니다. 매번 여러 광고주의 데이터 다운로드를 위해 클릭을 하다 보면 아무래도 사람이다 보니 실수할 여지도 있지 않겠습니까? 더욱이 한 사람이 여러 광고 매체를 다루는 일도 빈번하니까요. 즉, 여러 가지 위험(실수)에 노출됩니다. 이런 이유로 여건만 된다면 데이터를 브라우저를 통해 다운로드하는 방식이 아니라 API를 사용하는 게 훨씬 좋겠습니다.
세상에 쉬운 일은 없다 - “데이터를 호락호락 줄 순 없지!”
그런데 말입니다. API는 개발의 어려움을 차치하더라도 생각보다 깐깐한 경우가 많습니다. 일반적으로 우리가 광고 매체에 리포트 데이터(이하 A)를 요청하면 A를 내려주는 걸 생각할 수 있는데요. 아래 이미지를 살펴보시죠. 여기서는 편의상 캠페인 리포트를 요청했다고 표현했습니다. 캠페인 리포트를 요청하면 캠페인 리포트를 응답 주는 방식입니다. 당연한 내용입니다.
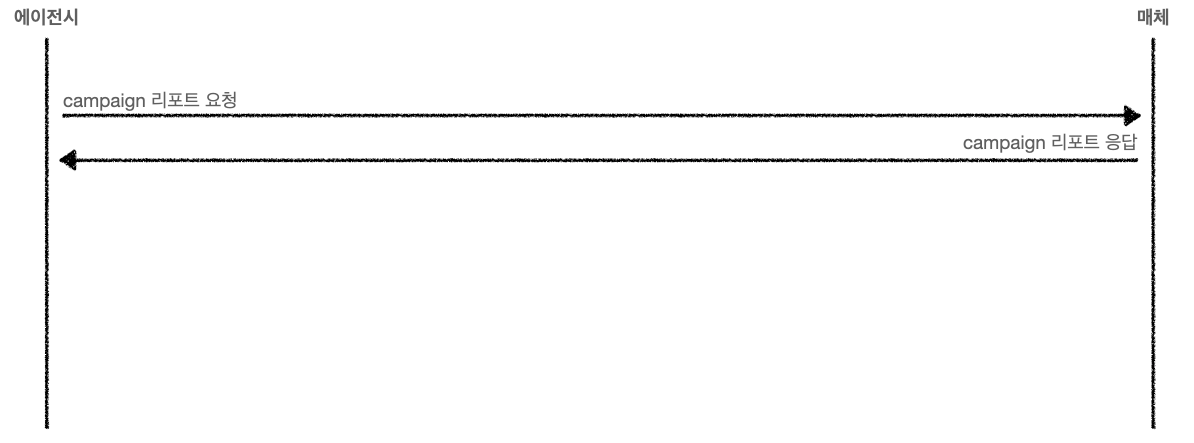
자, 그러면 A를 동시에 5개 요청해보죠. 에이전시에서 관리하는 다섯 개의 광고주 데이터를 요청한다고 가정하는 겁니다. 이 경우도 보통은 잘 줍니다.

그렇다면 A x 500은 어떨까요? 동시에 500개를 요청하는 겁니다. 대부분의 광고 매체는 이런 경우 데이터를 내려주지 않습니다. 왜 그럴까요? 짧은 시간에 이렇게 많은 요청을 보내는 게 정상이 아니라고 판단하기 때문입니다. 혹은 “방금 데이터 내려줬는데 왜 또 요청해?”, “우리 서버는 당신 혼자 쓰는 게 아니야!” 같은 이유가 있습니다. 결국은 자신들의 서버를 보호하려는 목적이죠. 그래서 API는 제약사항이 걸려있는 경우가 많은데요. 그 제약사항은 API 명세(개발을 위해 필요한 문서)를 살펴보면 대부분 잘 나와있습니다. rate limit, call limit 같은 항목으로요. “초당 10개 이상의 요청을 보낼 수 없음”처럼 정확하게 안내해주는 곳이 있는가 하면 “짧은 시간에 여러 요청을 보낼 수 없음”처럼 애매하게 나타내는 곳도 있습니다. “호출 제한이 걸리면 잠시 후에 다시 시도하세요”처럼 API 사용자가 해야 할 조치를 결정하는 데 필요한 정보를 충분히 내려주지 않기도 합니다.
심지어 어떤 매체의 경우 “10초에 1회만 호출 가능” 같은 제약도 있습니다. 여러 광고주의 데이터를 다운로드해야 하는 에이전시 입장에서 이런 시간 제약은 아주 골치 아픕니다. 더욱이 기술력을 갖추지 못한 에이전시라면 늘어나는 광고주 수를 감당하지 못할 겁니다. 이번 글은 바로 이 제약 조건, “10초에 1회만 호출 가능”를 지키면서 늘어나는 광고주 수에도 흔들리지 않고 많은 데이터를 수집할 수 있는 플랫폼에 대한 이야기입니다. 매체에 처음부터 이런 제약이 있었던 것은 아닙니다. (사용자 입장에서는) 매체 API 새 버전이 출시되면서 생긴 제약이었죠.

아, 그건 그렇고 동시에 500개를 요청해야 하는 상황이 있냐고요? 에이전시 입장에서는 충분히 가능한 상황입니다. 광고주 수가 많을 수도 있고 한 광고주가 운영하는 캠페인이 아주 많을 수도 있으니까요. 아래 그림을 보면 노란색 광고주는 캠페인 리포트 한 개만 받아도 되는 반면 핑크색 광고주는 캠페인 다섯 개를 운영하고 있네요. 전체적으로 보면 광고주는 네 개지만 받아야 하는 캠페인 리포트는 10개인 상황입니다. 이런 계산이면 얼마든지 500개까지 늘어날 수 있죠.
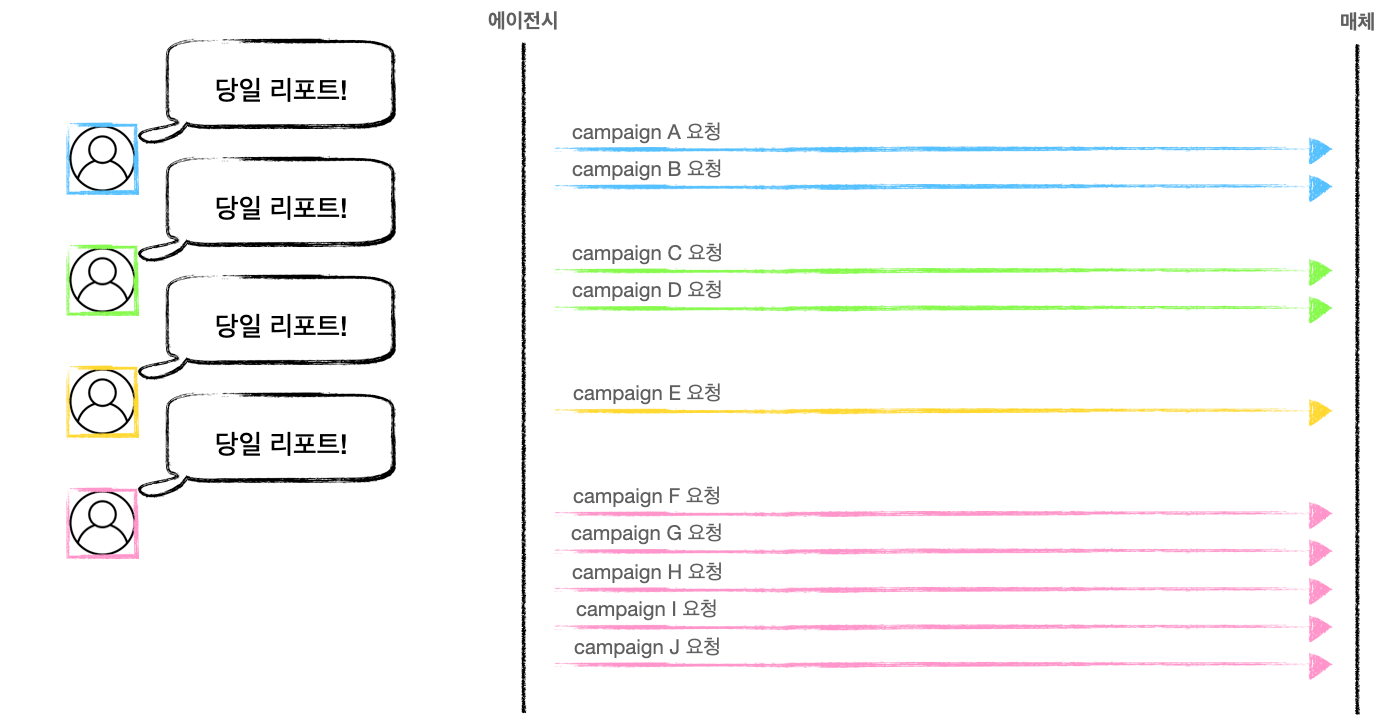
또한 광고 데이터가 확정되는 시간(전환 데이터 등)을 고려하면 당일 데이터뿐만 아니라 과거 데이터도 함께 수집해야 하는 경우가 많습니다. 광고주에게 제공하는 리포트에 정확한 수치를 담기 위해서입니다. 아무튼, 이렇게 동시에 많은 요청을 보내면 앞서 이야기한 이유로 광고 매체는 리포트 데이터를 주는 대신 아래 같은 “에러”를 돌려줍니다.
429 Too Many Requests
여기까지 생각하면 “아, 그러면 적당히 텀을 두고 요청하면 되겠네”라고 생각하실 수 있습니다. 아래처럼 말이죠.
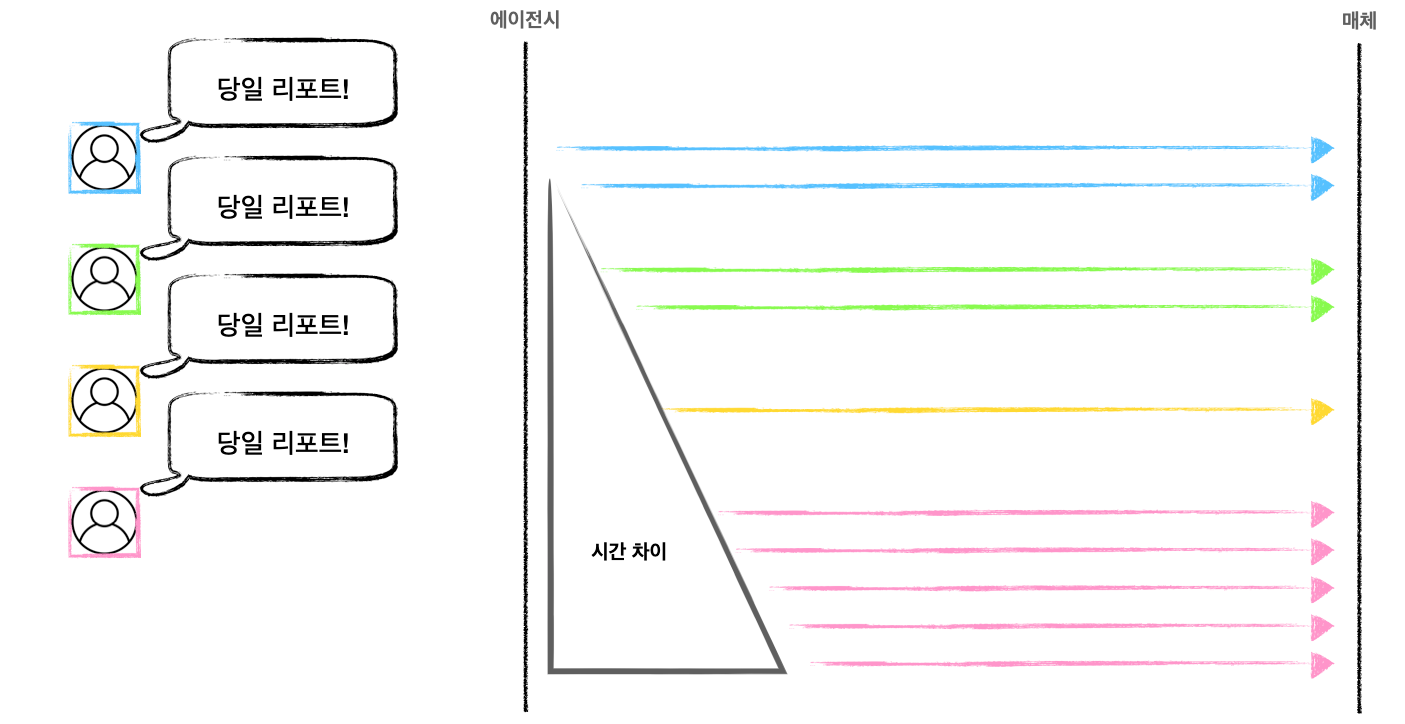
이렇게 시간 간격을 두는 건 좋은 아이디어라고 생각합니다. 일반적으로 throttling과 같은 이름으로 실제 개발에서도 종종 사용하는 방식입니다. 아무튼, 좋은 아이디어라는 건 매체 API 특성을 잘 모를 때는 일입니다. 이 글에서 아직 언급하지 않은 제약이 남아있습니다.
아직 (제약) 한 발 남았다

“10초에 1회만 호출 가능”에 더해서 1회 호출로 내려받을 수 있는 데이터 양의 최댓값이 정해져 있습니다. 고로 모든 데이터를 받아오기 위해서는 pagination 처리가 필요합니다. 예를 들어 데이터가 1,000 조각 있다면 한 번에 내려받을 수 있는 건 100개인 상황입니다. 우리가 인터넷에서 흔히 볼 수 있는 게시판을 생각하면 쉽게 이해가 되실 겁니다. 한 페이지에 100개의 데이터만 보이고 “다음 페이지” 버튼을 누르면 다음 100개 항목이 보이는 거죠. 게시판은 조금 올드한 느낌인가요? 그렇다면 모바일에서 많이 사용되는 infinite scroll(쇼핑몰 앱에서 스크롤을 내리면 새로운 아이템 목록이 계속 불러와지는 개념)을 떠올리셔도 좋습니다. 그런데 문제는 다음 페이지 버튼(혹은 스크롤)이 정상적으로 동작하려면 10초가 필요하다는 겁니다. API 제약 사항 때문에요!
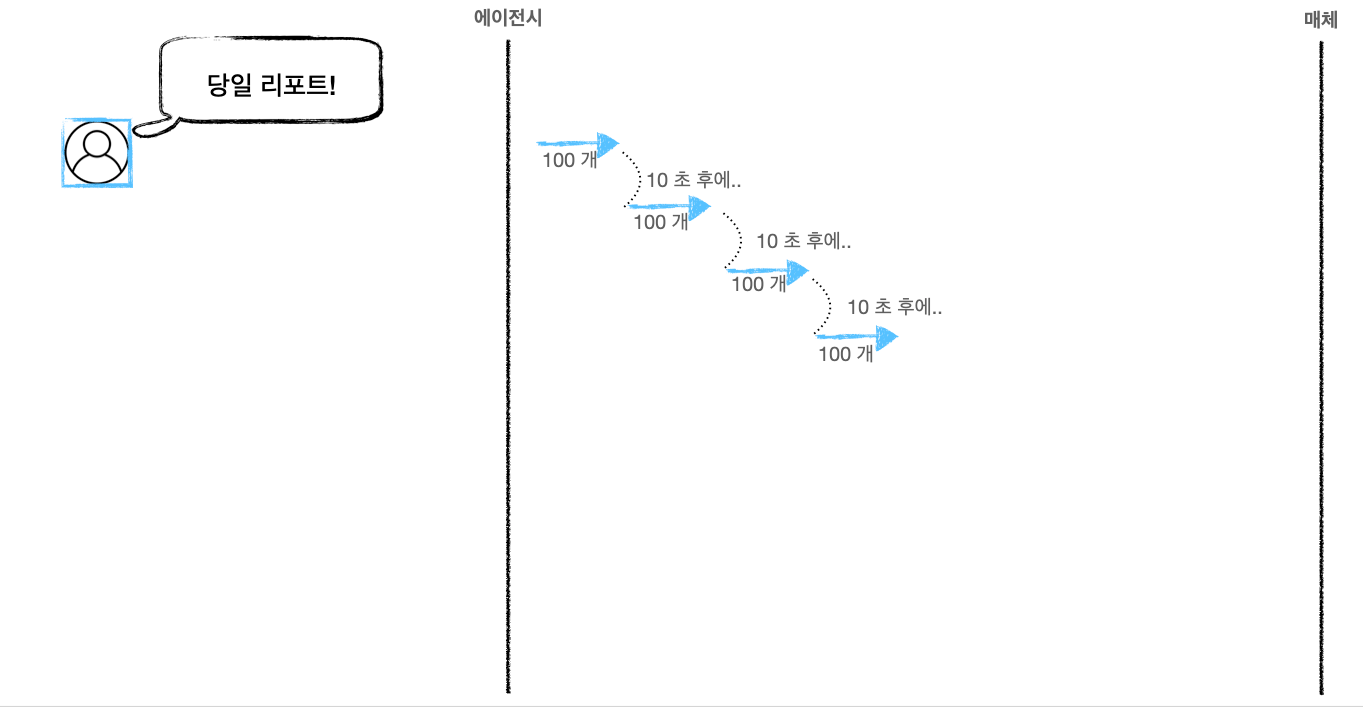
일부 매체 API에도 이러한 pagination 개념이 들어가 있습니다. 위에서 예시로 들었던 1,000개의 데이터를 모두 받으려면 산술적으로 생각했을 때 (요청하고 실제 다운로드하는 데 걸리는 시간을 0초로 생각해도) 10번 호출을 해야 합니다. 총 걸리는 시간은 10초에 1회만 호출 가능하니까 100초, 즉 1분 40초가 필요하네요. 그리고 당연한 이야기지만 위에 파란색 광고주의 데이터를 수집하는 도중에 같은 API를 호출하게 되면 에러가 발생합니다. 10초마다 1회 호출해야 하는 제약을 준수하지 않았기 때문이죠. 아래는 에이전시에서 파란색 광고주 데이터를 수집하는 도중에 핑크색 광고주를 위해 API를 추가로 사용한 경우입니다.
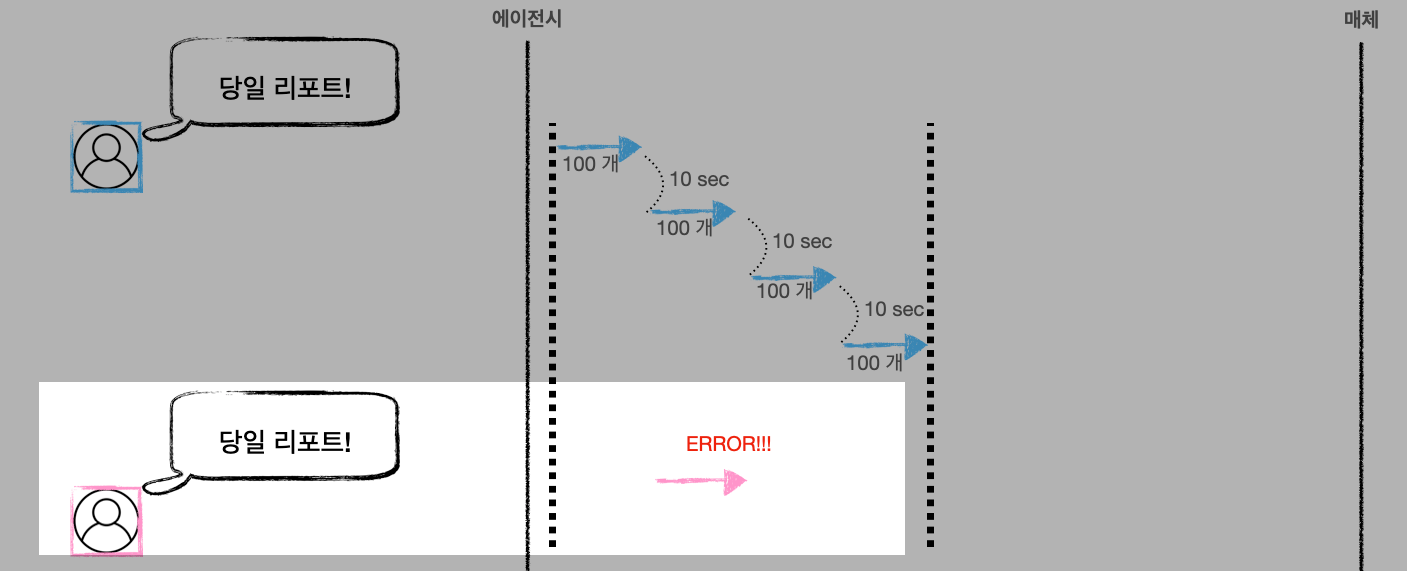
여기서 또 다른 문제가 등장합니다. 매드업은 광고주에게 수준 높은 리포트를 제공하기 위해서 이런 API x N개를 호출해서 뽑아낸 데이터를 조합해서 사용합니다. 지금까지는 캠페인 리포트에 대한 이야기만 다뤘는데 광고그룹 리포트도 있을 수 있죠. 여기도 호출 제약이 존재합니다. 이 API는 한 번에 가져올 수 있는 데이터가 20개입니다.
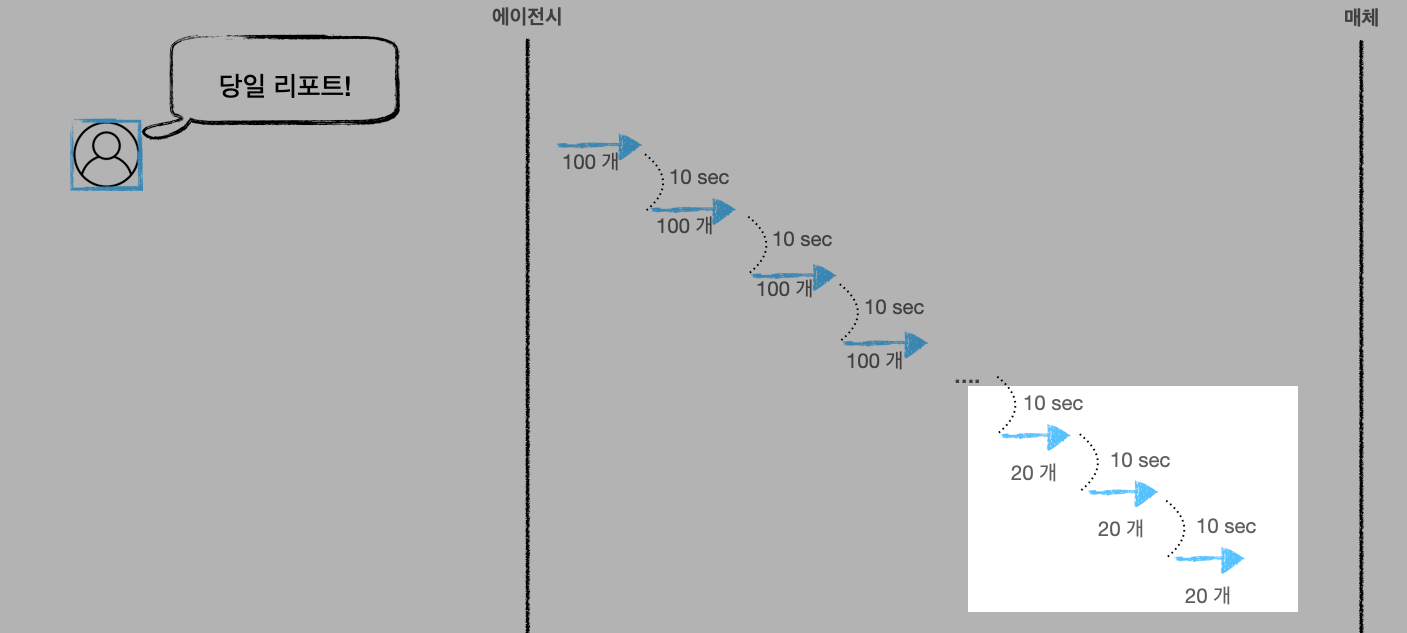
최종 리포트 생성을 위해 필요한 데이터를 위의 이미지처럼 순차적으로 받는 건 가장 기본적인 방법입니다. 에이전시 입장이 아니라면 최선/최고의 방법이기도 하고요. 하지만 여러 광고 계정(광고주)의 정보를 일괄적으로 가급적 빠른 시간 안에 수집해야 하는 매드업 입장에서는 그리 좋은 방식이 아니었습니다. 한 개 광고주 데이터를 모두 받는데 60분 걸린다고 치면, 10개 광고주 데이터를 받는데 필요한 산술적인 시간은 600분입니다. 10시간 이상을 쉬지 않고 수집해야 리포트를 생성할 수 있는 거죠(중간에 에러가 없다는 가정). 더욱이 매드업은 급성장하는 로켓인 만큼 광고주 수도 기하급수적으로 늘고 있기 때문에 새로운 방식이 필요했습니다. 우리가 풀어내야 하는 문제에 욕심을 더해서 모든 데이터가 새벽에 수집돼서 아침에 리포트로 발송되길 원했습니다. 마케팅 에이전시의 새벽 배송이랄까요?
바야흐로, 크라켄의 등장
매드업은 이런 API 제약 상황을 타개해야 했습니다. 우리는 기술 기반의 회사니까요. 매체 데이터 수집에 어려움이 있다고 해서 고객에게 제공되어야 할 리포트에 구멍이 생겨서는 안 되겠죠. 우선 이 미션을 해결하기 위해 매체의 제약사항을 다시 한번 빠르고 정확하게 정리해봤습니다. 그 결과 우리가 극복해야 하는 상황은 정말 괴물같이 느껴졌습니다.

위에서 편의상 “10초에 한 번 호출 가능(이하 A)”이라고 표현했지만 “5초에 한 번 호출 가능(이하 B)”처럼 API 마다 시간 제약이 다릅니다. 또한 최고의 리포트를 제공하기 위해 수집해야 하는 API 종류도 다양합니다. 결정적으로 시간 제약은 언제든 매체 API 업데이트로 바뀔 수 있습니다. 그렇다면 우리가 생각할 수 있는 방법은 parallel 하게 A는 A대로 필요하면 계속 호출(수집)하고 B는 B대로 호출(수집)을 계속해주면 됩니다. 마치 크라켄의 다리 하나하나가 서로 다른 API 종류이고 빨판 간격은 다음 호출에 필요한 시간 간격(제약)과 같습니다. 후술 하겠지만 광고 계정 종류는 중요하지 않습니다. 다양한 API를 통해 수집한 정보는 나중에 한 번에 취합하면 되니까요.
크라켄 컨셉
컨셉을 이해하기 위해 다리를 뜯어봅시다. 크라켄의 다리를 그림으로 표현하면 다음과 같습니다.
이 다리에 빨판 부분은 API 호출을 나타냅니다. 그리고 빨판 간격은 API 호출 간 제약(10초)을 나타내고요. 이런 내용을 추가해주면 아래처럼 표현됩니다. 여기부터 비슷한 그림이 연속으로 추가되므로 잘 따라오셔야 합니다. “이건 문어 다리야”라고 마인드 컨트롤을..
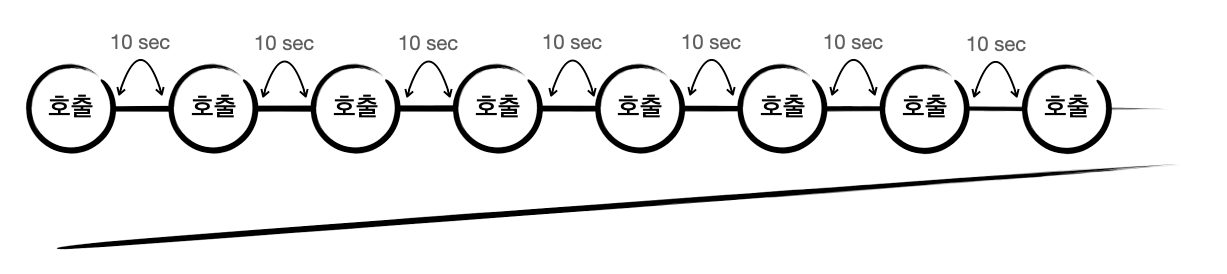
위에 그려진 크라켄 다리는 캠페인 리포트를 처리합니다. 끊임없이 계속 처리합니다. 매체에서 정해준 호출 간격대로 말이죠. 다음으로 우리에게 필요한 건 광고그룹 리포트입니다. 크라켄에 다리를 추가해줍시다.
장난 같지만 여기 추가로 받아야 하는 데이터가 생기면 크라켄에 다리를 추가해주면 됩니다.
데이터가 쌓이기만 해서는 의미가 없습니다. 여기 특정 광고주의 정보를 색칠해보면 아래처럼 표시됩니다.
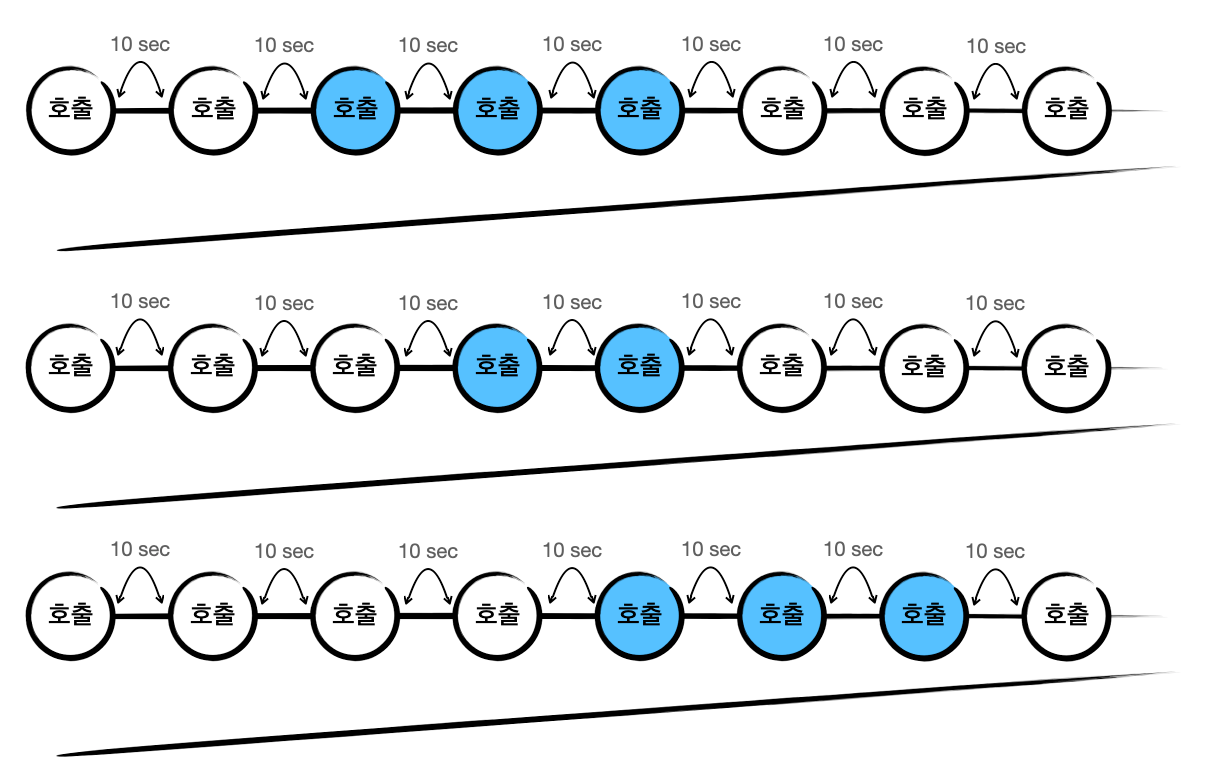
파란색의 마지막 데이터가 최종적으로 수집되면 해당 정보를 매드업의 Data Warehouse에 저장합니다. 이제 리포트 생성을 위한 데이터 준비는 끝났습니다!
크라켄 아키텍처
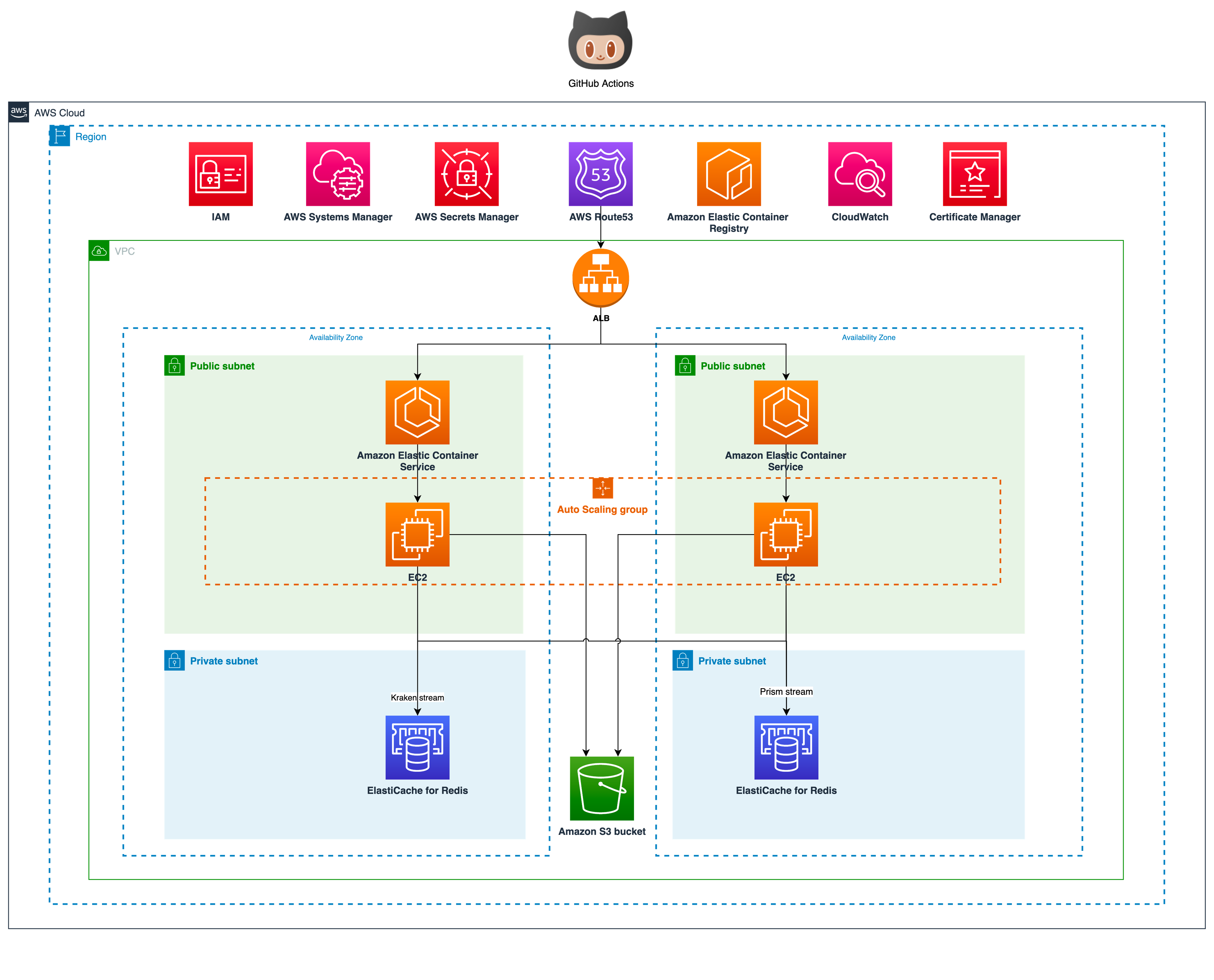
이렇게 글을 마무리할까 고민도 했지만 기술적인 내용이 없으면 개발자의 갈증을 채울 수 없겠죠. 크라켄을 구축에 들어간 기술 스택과 아키텍처에 대한 이야기를 해보겠습니다. 모든 구성은 AWS ECS로 구축되어 있습니다. 매체와 직접 통신을 해야하기 때문에 인스턴스는 Public subnet을 이용합니다. Private subnet에 두고 NAT를 연결하는 방법도 있지만 이때는 data transfer 비용을 감수해야 합니다.
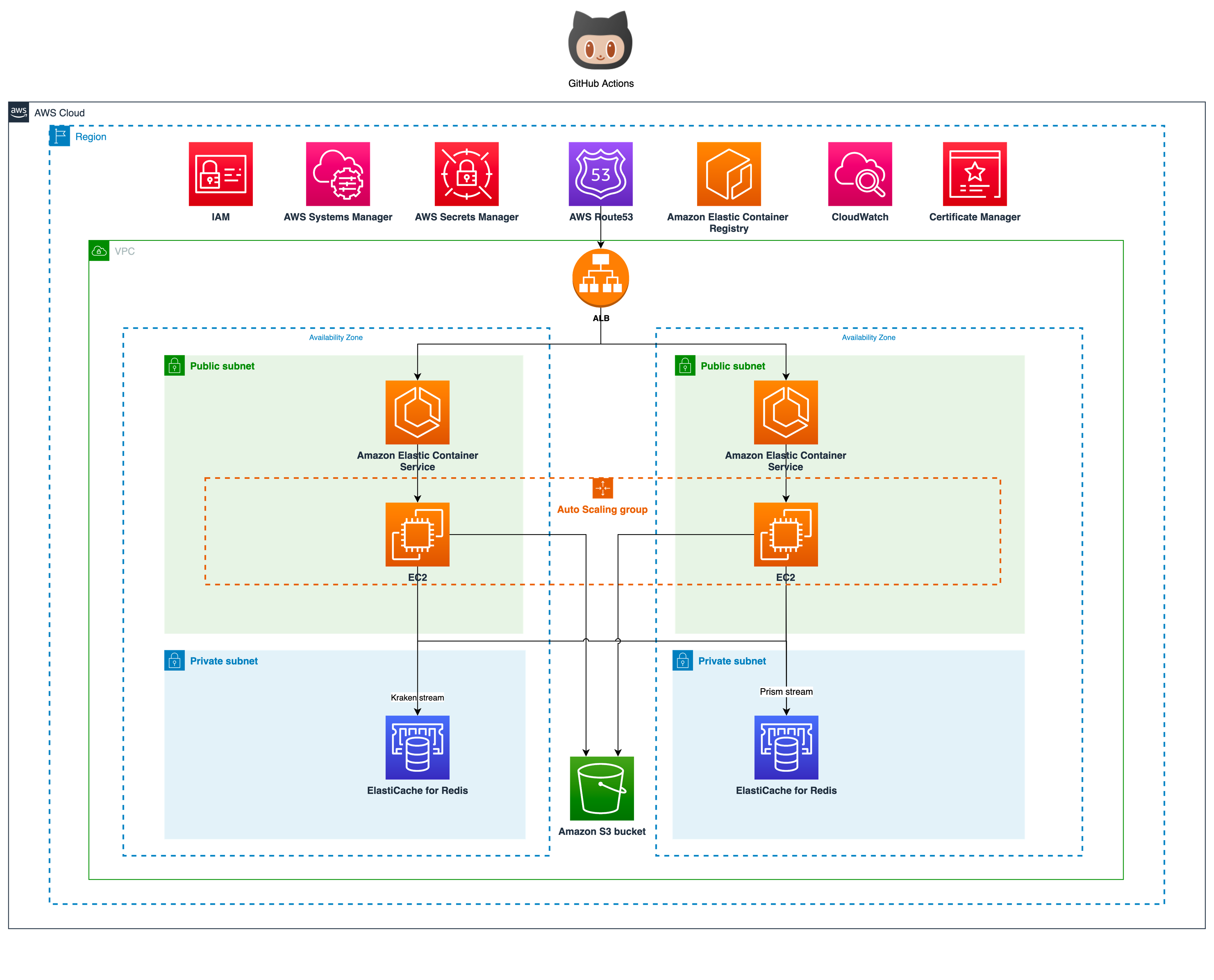
세부 아키텍처를 살펴보겠습니다. 크라켄을 이루는 컴포넌트로는 매체 API 호출 제약을 조절하는 throttling application과 수집을 담당하는 collect application, 무중단 서비스 목표를 달성하기 위한 checker application으로 나뉘어 있습니다. 모두 python으로 구현되어 있으며 GitHub Actions를 통해 자동 배포됩니다. feature 단위로 배포하고 있기 때문에 필요한 경우 하루에도 수 회 이상 배포되고도 합니다. 최근에는 신규 기능 요청이나 특별한 이슈가 없어서 최근 5번의 스프린트 동안 15회 배포 밖에 없었네요. 🙂
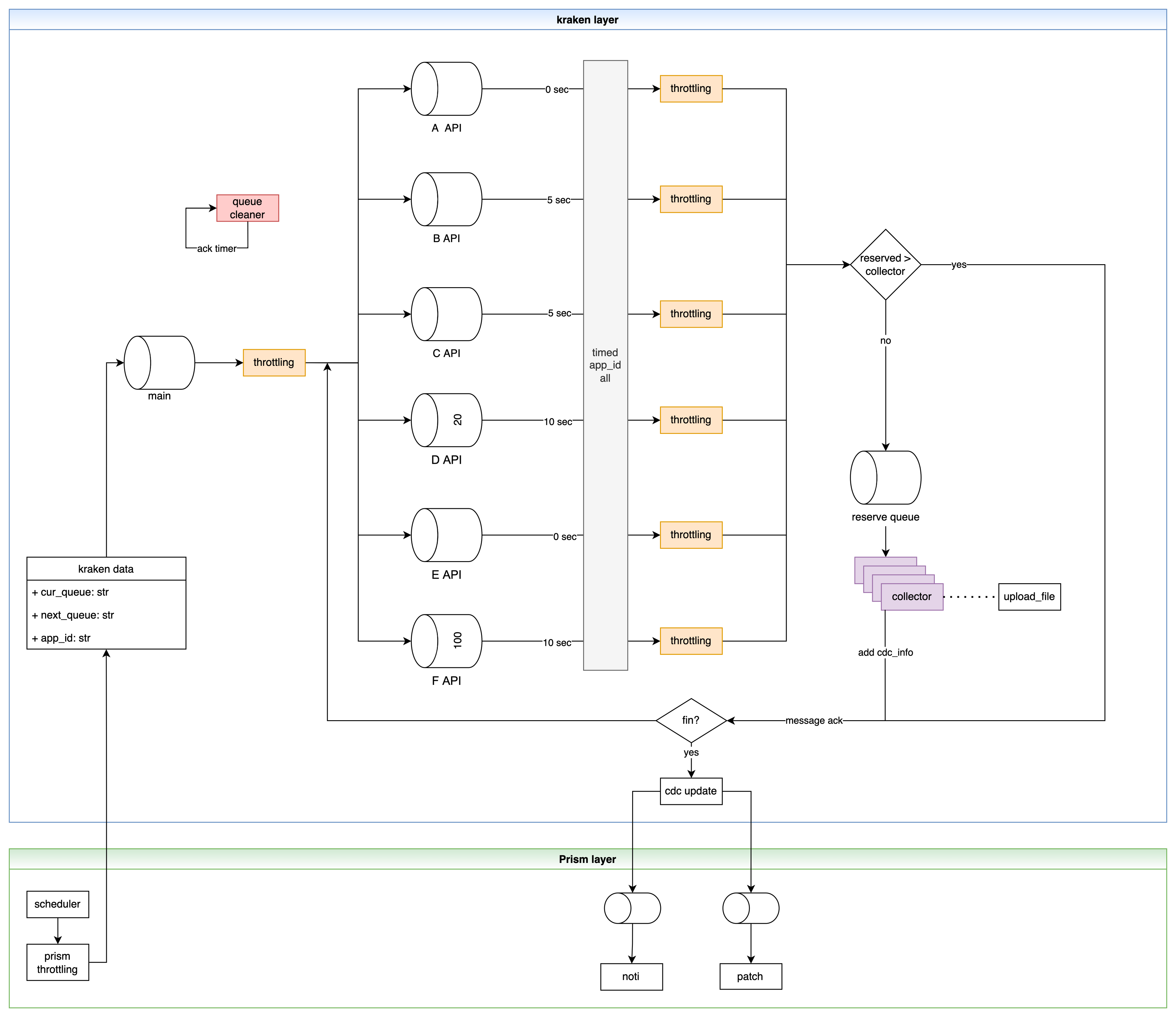
우선 수집해야 하는 광고주 정보는 RDS에서 관리됩니다. 해당 정보를 바탕으로 주기적으로 수집 프로세스가 운영되는데 이는 Event Driven 방식으로 좌측에 있는 Kraken stream(main)를 통해 요청이 들어오게 됩니다.
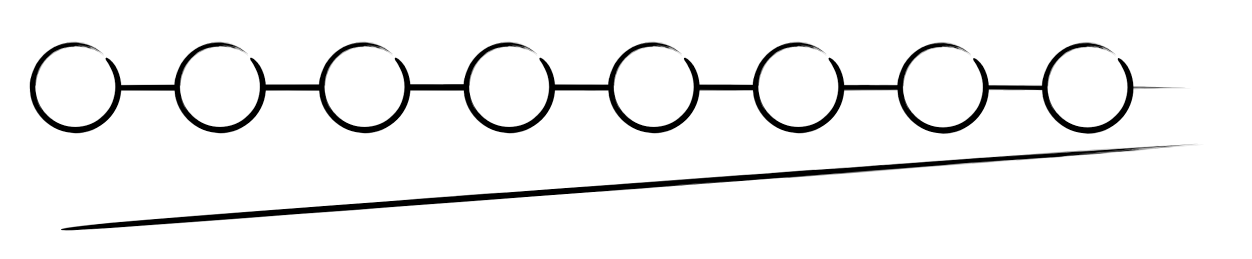
Kraken stream은 AWS ElastiCache for Redis의 stream 타입입니다. Event Driven 방식으로 설계를 할 때 교과서처럼 등장하는 kafka도 함께 고려되었지만 당장 크라켄에 필요한 건 데이터가 정상적으로 수집이 되었다는 message ack 기능이었기 때문에 redis stream으로 충분했습니다. 이해를 돕기 위해 redis stream 방식에 대해 짧게 설명하고 넘어가겠습니다. stream은 들어오는 메시지에 대해 몇 가지 상태를 정의할 수 있습니다. 아래 그림을 봐주세요.
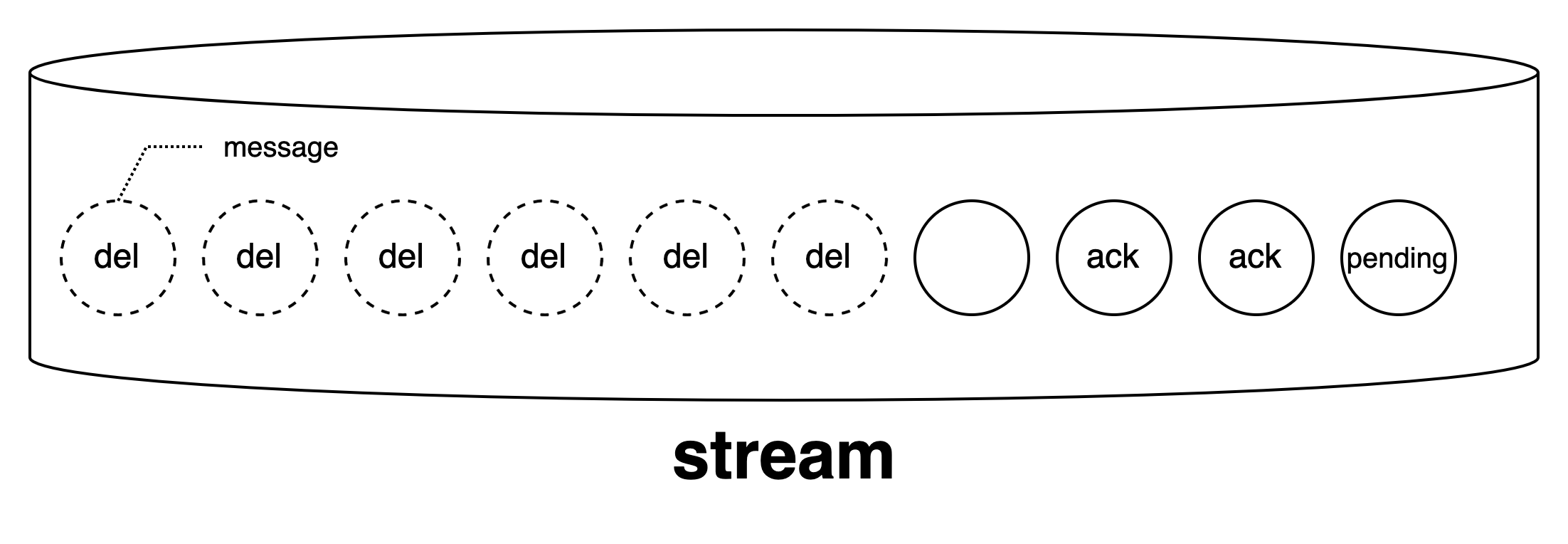
stream으로 처음 메시지가 들어오면 아무 상태도 갖지 않습니다. 위에 텍스트가 없는 빈 원을 보시면 됩니다. 그 상태에서 메시지가 꺼내지면 pending 상태로 기록되고, 메시지 처리가 끝나면 그 결과를 ack로 마킹할 수 있습니다. 끝으로 stream 내에서 메시지를 삭제할 수 있습니다. 삭제되면 존재하지 않는 상태지만 위에 그림에서는 개념상 표현을 위해 del로 표기했습니다. 이렇게 stream의 상태 기록을 통해 매체 데이터가 정상적으로 수집되었는지 크라켄은 판단하게 됩니다.
데이터 수집이 완료되면 이 정보는 Prism stream으로 전달됩니다. 프리즘(prism)은 kraken을 감싸고 있는 더 큰 플랫폼으로 매드업의 DMP(Data Management Platform)입니다. 나중에 다른 글을 통해 프리즘 아키텍처가 상세히 소개될 예정입니다. 매체 서버의 오류나 기타 이유로 수집 중간에 문제가 발생하는 경우 message ack를 처리하지 못하기 때문에 해당 정보를 감시하던 checker application은 지정된 횟수만큼 이를 다시 시도합니다.
한편, kraken stream이 크라켄의 다리 역할을 맡고 있으므로 다리 증설이 필요한 경우 stream key를 추가로 정의해주면 됩니다. 즉, 신규 API 수집이 필요한 경우 stream을 새로 지정해서 사용하게 되는데요. API 마다 endpoint, query param 등 필요한 정보가 다르므로 필연적으로 구현이 필요합니다. 하지만 초기부터 확장을 염두하고 설계/구현했기 때문에 어렵지 않게 신규 API를 붙일 수 있습니다.
마무리
이번 글에서 다루지는 않았지만 매체에는 A 리포트를 수집하려면 B 리포트 정보가 필요하고, B 리포트를 수집하려면 C 리포트가 필요한 경우가 있습니다. 그렇다는 이야기는 크라켄 다리는 완전한 독립이 아니라 서로 인과관계가 있음을 나타냅니다. 사실 크라켄의 핵심 기술은 거기에 있죠. 매체의 API 호출 제약이 나날이 심해지면서 많은 에이전시가 어려움을 겪고 있습니다. 하지만 매드업은 크라켄을 구축함으로 에러 없이 필요한 시점에 정확히 리포트 데이터를 수집하고 있습니다. 그리하여 평소 5~10% 수집 에러가 발생하고 있던 해당 매체의 에러 비율을 0%가 됐습니다.
글의 일부 내용은 실제 매체의 제약과 100% 일치하지 않습니다. 누군가 이 글을 읽는데 어려움이 없도록 편의상 각색한 부분이 존재하기 때문입니다. 예를 들어 캠페인 리포트의 경우 한 번에 5개씩 가져올 수 있으며 5초에 1회 허용됩니다. 또한 이 글이 발행되고 매체가 업데이트되는 경우 더 괴리감이 생길 수도 있습니다. 하지만 크라켄도 매체의 업데이트에 따라서 진화하게 될 겁니다 🙂
소프트웨어 엔지니어가 개발하는 코드는 비즈니스로 연결되어 고객에게 높은 가치를 제공할 때 비로소 빛을 봅니다. 매드업은 함께하는 광고주의 가치가 더욱 빛 날 수 있도록 여러 가지 프로덕트를 개발/운영하고 있습니다. 이런 즐거운 고민을 함께하실 분은 언제든 채용 문을 두드려주세요!


