매드업의 DMP - 프리즘(prism)을 소개합니다
안녕하세요. Adtech(Advertising technology) 스타트업 매드업 에서 데이터 엔지니어로 일하고 있는 칼리 입니다. 이번 글은 매드업의 Data Management Platform(DMP) - Prism을 소개하는 글입니다. 프리즘을 구축, 운영하며 어떤 고민을 했는지 그리고 앞으로의 방향을 확인해봅니다. 목차는 다음과 같습니다.
프리즘(Prism) 소개
매드업에 합류해서 동료들과 함께 구축한 Data Management Platform(DMP)을 Prism(프리즘)이라는 이름으로 사내에 공개(2021-07-01)했습니다. 프리즘은 데이터를 수집/가공/적재/공급하는 전체 파이프라인을 품고 있습니다.

자, 그러면 매드업의 프리즘은 어떤 데이터를 수집할까요? 광고 데이터 입니다. 매드업은 광고주의 광고를 대행하며 더 좋은 성과 지표를 만들기 위해 데이터를 다양한 각도로 분석해서 높은 효율을 낼 수 있도록 고민합니다. ( 더 좋은 성과는 노출, 클릭, 비용 같은 지표가 될 수도 있고 고객에 따라 기타 다른 무언가가 될 수도 있습니다 )
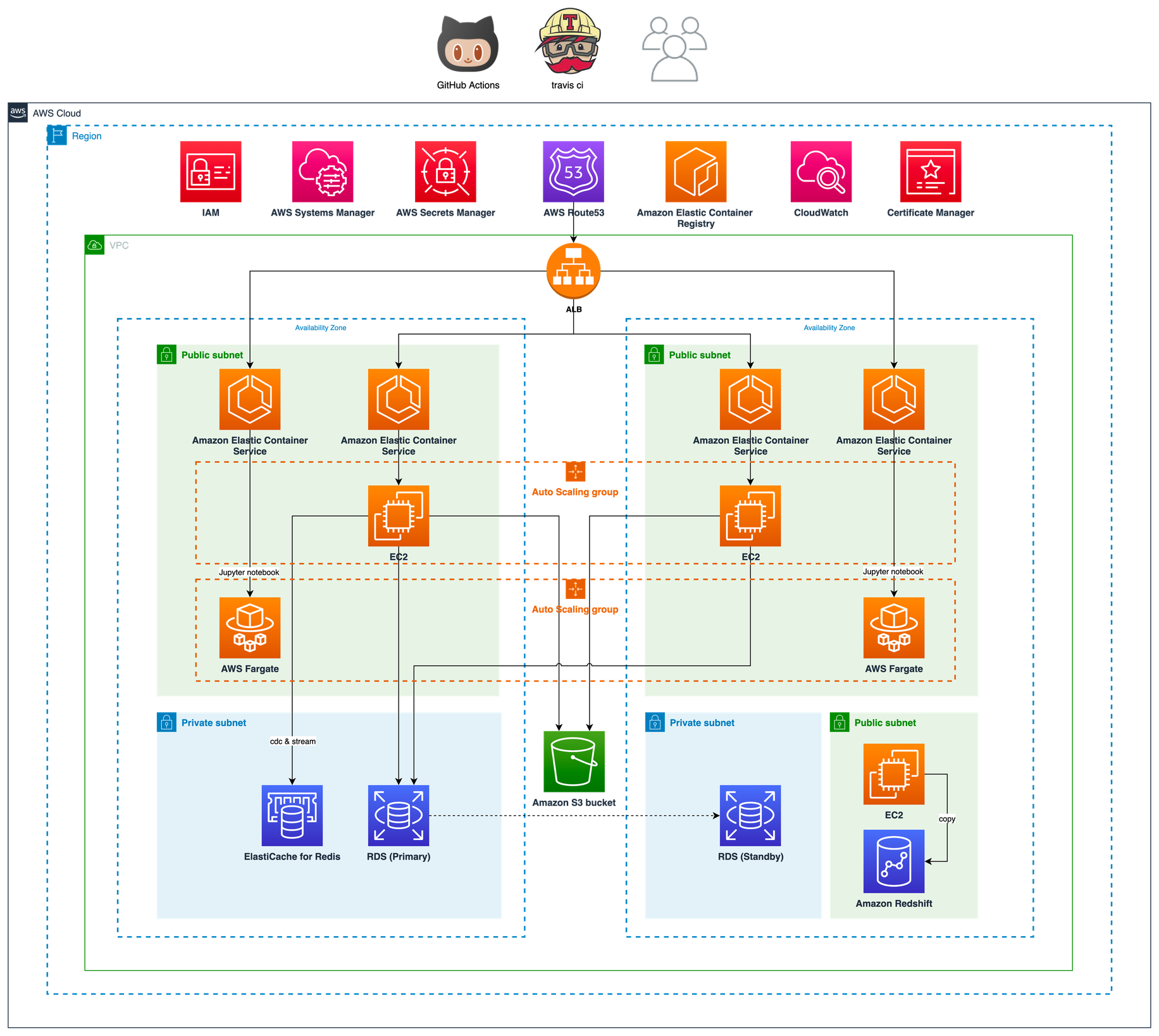
온라인에 공개 가능한 범위의 프리즘 기본 아키텍처는 다음과 같습니다. Python으로 작성된 데이터 수집기(collector)는 매드업 전체 광고주의 매체(Google, Facebook, Naver, Kakao Moment 등) 데이터와 트래커(Appsflyer, Google Analytics 등) 데이터를 주기적으로 수집해서 AWS S3에 적재합니다. 광고주별로 한번에 수집되는 데이터의 크기는 적게는 MiB 단위부터 GiB까지 스펙트럼이 굉장히 넓습니다. 이렇게 대량의 데이터를 수집하기 위해 광고주의 수에 따라 수집기는 수백~때로는 수천개까지 증축 운영 될 수 있는 아키텍처로 구축되어 있습니다. 여기서는 AWS의 대표적인 컨테이너 오케스트레이션 서비스인 Elastic Container Service(ECS)가 사용되었습니다.
이렇게 수집된 데이터는 ELT(Extract, Load, Transform)를 통해 가공됩니다. S3에 저장되어 있는 Raw 데이터(매체에서 수집한 원본)를 추출해서 Data Warehouse인 Redshift에 Load(Redshift 입장에서는 저장) 하는거죠. 필요한 경우 Load하기 전에 데이터를 사용하기 좋은 형태로 변환(Transform)하기도 합니다. Load된 이후에 쿼리를 통해 새로운 테이블로 다시 내보내기도 하고요.
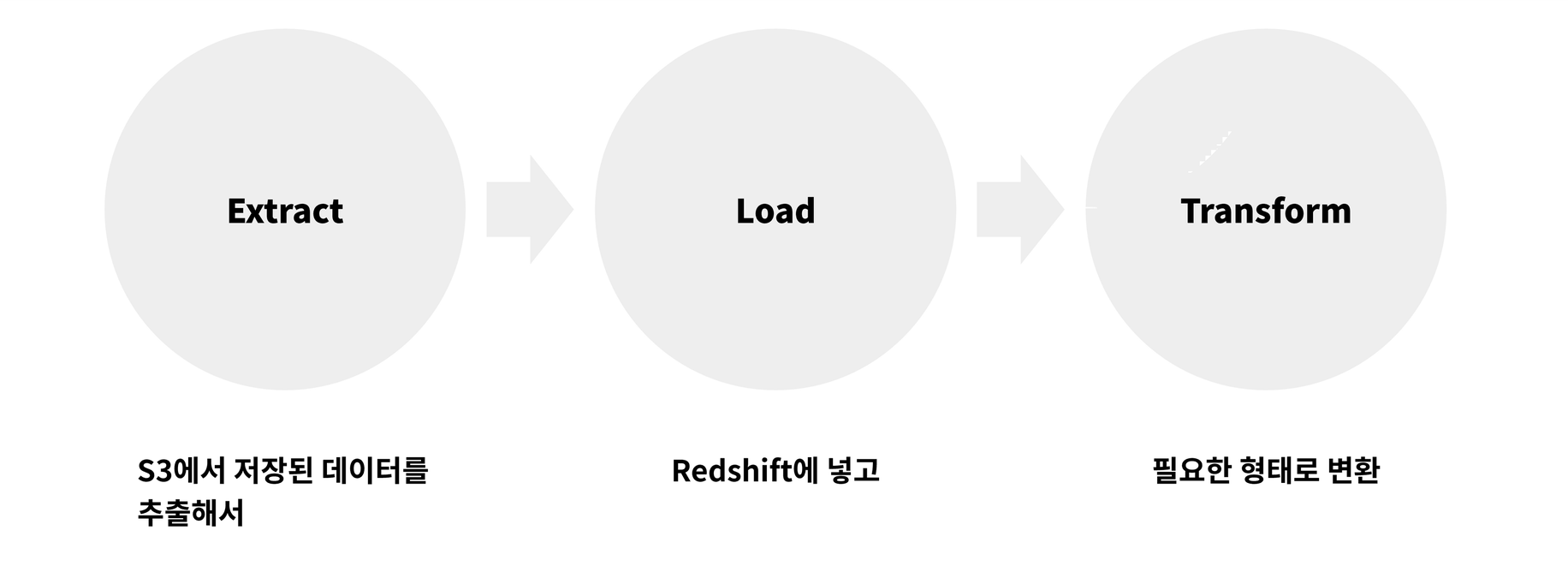
이런 과정을 IT 용어로는 ELT(Extract, Load, Transform), ETL(Extract, Transform, Load)이라고 부릅니다. 그리고 이런 처리 과정은 Workflow 도구를 사용하면 데이터가 아주 자연스럽게 흘러갈 수 있도록 운영이 가능한데요. 매드업은 Workflow의 대표적인 오픈소스, Apache Airflow 를 사용하고 있습니다.
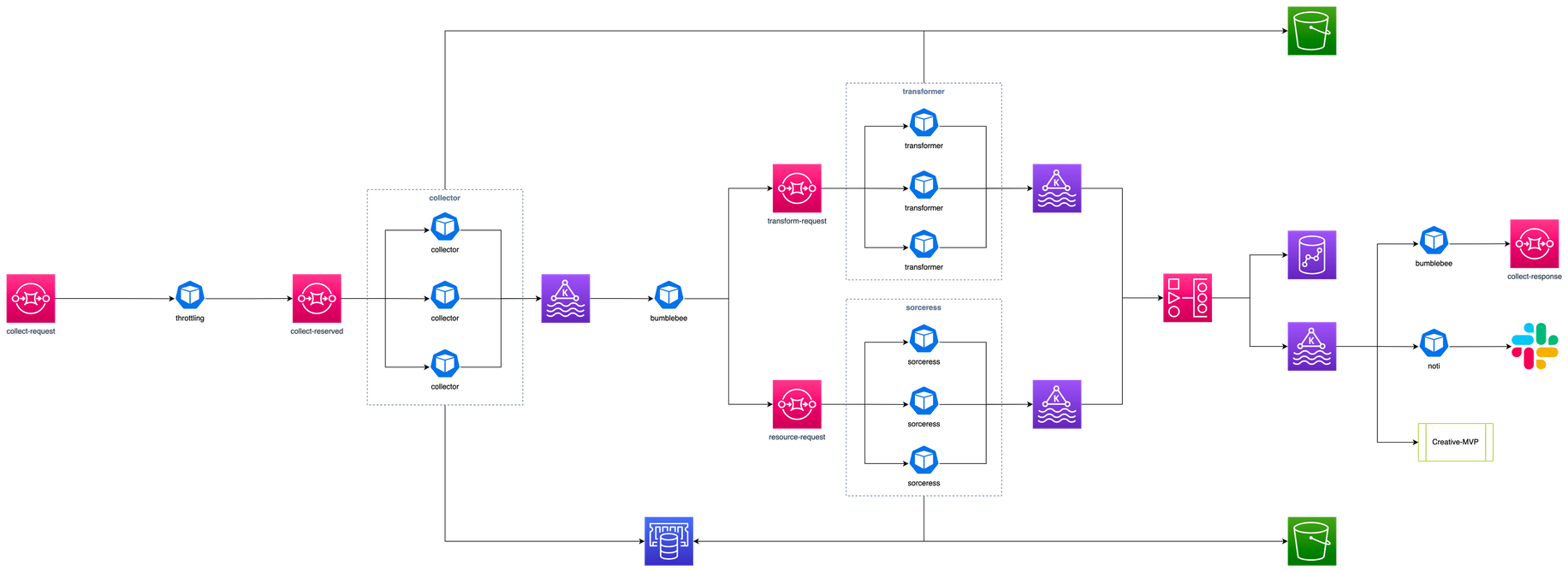
이쯤에서 프리즘의 전체 아키텍처를 도식화해서 그려놓은 그림을 살펴보시죠.
혹시 “프리즘”에서 스노든의 Prism 이 떠오르셨더라도 정상입니다. 매드업의 모든 데이터가 조회되길 바라는 마음으로 프로덕트 이름을 정했거든요 🙂
프리즘으로 광고 데이터 수집, 적재
광고 데이터에는 아주 중요한 특징이 있는데요, 광고 매체에서 내려주는 데이터가 호출(요청)마다 신선도가 좋아진다는 점입니다. 예를 들어 Google Ads에서 제공하는 2023-03-16(최근 날짜라고 가정) 데이터를 오늘 내려받았을 때와 내일 내려받았을 때 결과가 다를 수 있습니다(아니, 다릅니다. 심지어 한 달 후의 결과도 다릅니다). 이건 광고주가 전환 추적 기간 설정을 했기 때문인데요, 구글뿐만 아니라 다른 대부분의 매체도 유사합니다. 페이스북의 경우는 아래 문구를 확인해주세요. 한 달 가까운 시간 동안 데이터는 계속 업데이트될 겁니다.

이런 특징 때문에 광고 데이터를 Data Warehouse(DW)에 제대로 구축하려면 많은 어려움이 따릅니다. 자체 기술력이 부족하다면 데이터의 “정확성”을 포기하는 것도 방법입니다. 그렇게 되면 아키텍처의 많은 부분들이 간소화되니까요. 이 부분은 컴퓨팅 리소스 절감으로 시작돼서 인프라 비용까지 이어집니다.
보통 DW 구축은 데이터를 쏟아 붓기만 하면 됩니다. 하지만 완벽을 추구하는 조직(회사)라면 광고 데이터를 DW로 제공하기 위해서 필연적으로 columnar database 에 UPSERT 같은 개념(조건이 충족되는 데이터가 존재하면 UPDATE, 없으면 INSERT)이 필요합니다. 하지만 하루 최소 수백 GiB 데이터가 핸들링되어야 하는 DW에 UPSERT라뇨. 대게 이런 경우는 기존 데이터를 전부 날려버리고 Data Lake(DL)로부터 새롭게 적재(TRUNCATE©)하는 방식을 택합니다. 그게 (보통은) 훨씬 빠르고, 비용도 저렴하고, 효율적이니까요 (여기서 비용은 금전적인 부분을 이야기하는게 아니고 아키텍처 유지 비용, 혹은 자원 사용량 등을 나타냅니다). 왜냐하면 데이터 적재 시에 UPSERT를 하려면 비즈니스 로직이 들어가야 합니다. 트랜잭션과 함께 복잡한 시나리오를 고려해야 하고 그 과정에서 데이터 정합성이 깨지기도 합니다. 데이터웨어하우스 입장에서 이건 심각한 문제입니다.
단순히 데이터 분석만을 위한 용도라면 Data Lake(aws S3)에 직접 쿼리(Athena, Spectrum)하는 것도 꽤 좋은 선택입니다. 하지만 우리는 DW를 서비스 레벨로 끌어올리려는 목표를 갖고 있습니다. 그 목표를 이루기 위해 UPSERT의 효과를 얻을 수 있는 여러 가지 처리를 도입했습니다. 부분적으로는 Data Mart(DM)를 운영하고요. - DW, DL 구축에 정답은 없습니다. 서비스 / 분석 / 리포트 영역에서 필요한 데이터를 효율적이고 쉽고 빠르게 제공할 수 있으면 그걸로 된다고 생각합니다. 한편 프리즘(Prism)은 앞서 설명한 광고 데이터의 특성을 극복하고 수백, 수천 종류의 데이터를 병렬로 빠짐없이 수집하고 적절한 처리를 통해 Redshift에 적재합니다(아, DW 선택이 논쟁의 여지는 있지만 사실 저는 BigQuery를 더 사랑해요). 이 과정에서 수백 개의 컨테이너가 오케스트레이션 됩니다.

그 결과 시간당 수십만 개의 파일을 처리해서 Redshift에 적재하게 됐습니다. 용량으로 따지면 수십 GiB에 해당하는 양입니다!
프리즘을 사용하는 모든 서비스에 Near real-time에 가까운 살아있는 데이터를 제공하는 게 우리가 추구하는 프리즘의 최종 모습입니다. 고객과 데이터 사이언티스트에게 데이터는 신선하고 정확할수록 좋습니다. 아무튼, 프리즘 V1은 기반 시스템을 대부분 갖췄지만 본격적으로 데이터가 “콸콸” 흐르기 위해서는 추가적으로 개선해야 하는 포인트가 몇 군데 남아있었습니다. 80% 완성은 공개된 오픈소스와 클라우드 컴퓨팅만 적절히 사용해도 엔지니어링 역량만 어느 정도 갖추고 있다면 충분히 가능합니다. 하지만 그 이상의 디테일을 해내기 위해서는 회사와 엔지니어의 풍부한 경험과 기술력이 뒷받침되어야 하죠. 악마는 디테일에 있으니까요. 앞으로도 재미있는 일이 많이 기다리고 있습니다!
데이터 소비
프리즘은 회사 구성원 누구나 유의미한 리포트 자료를 뽑을 수 있도록 데이터를 제공합니다. 프리즘에 있는 데이터는 container orchestration 도구인 AWS Elastic Container Service(AWS ECS) 위에서 동작하는 JupyterHub를 통해 Google Workspace 개인 계정으로 접근할 수 있습니다.

Jupyter Notebook은 Fargate로 실행되기 때문에 데이터 분석을 원하는 내부 사용자가 순간적으로 몰리더라도 리소스 점유와 같은 문제는 발생하지 않습니다. 한편 클라우드 리소스는 모두 Infrastructure as Code(IaC)로 관리되기 때문에 개발 / 스테이징 / 운영 환경을 필요에 따라 빠르게 구축할 수 있습니다. JupyterHub를 ECS에서 서비스하는 건 아마도 매드업이 국내 최초 같습니다. 뭐 물론 아키텍처가 공개되지 않은 사례도 있긴 하겠죠? 이와 관련된 이야기는 다른 글을 통해 공유할 기회가 있을 겁니다.
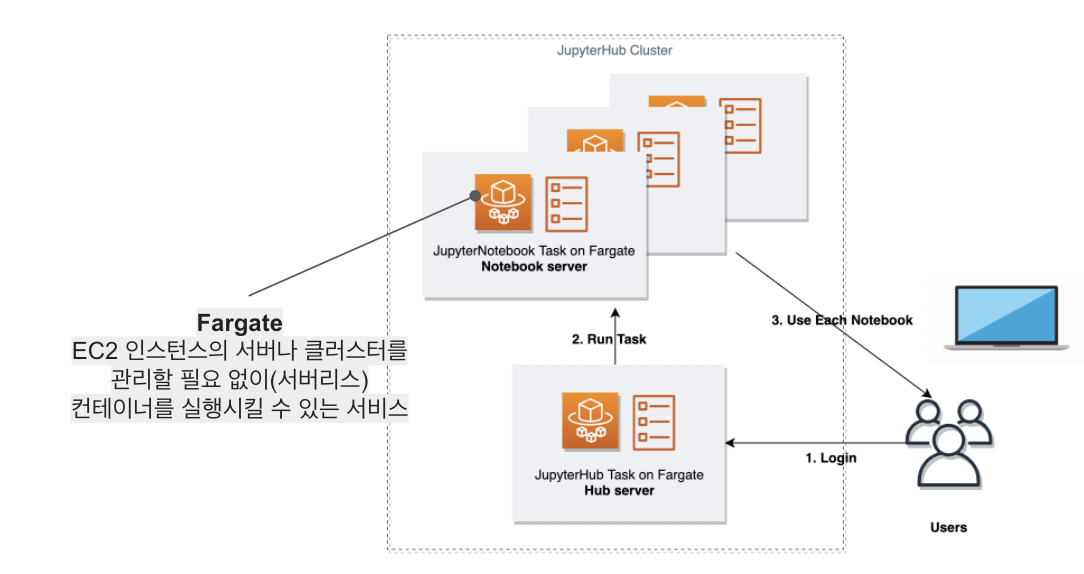
자, 여기까지의 이야기는 AWS 한국사용자모임에서 광고 데이터 수집을 위한 인프라 구축이란 내용 으로 발표했습니다. 혹시 관심 있으신 분은 영상을 통해 확인하시길 바랍니다. 아래는 프리즘 V1의 한계와 프리즘 V2를 소개합니다. 기술적인 모든 내용을 담기에는 지면이 부족하니 다양한 채널을 통해 연락 주신다면 공개 가능한 부분은 이야기드릴 수 있도록 하겠습니다 🙂
프리즘 V1의 성장 한계
약 1년 넘게 운영한 프리즘은 한계에 다다르게 됩니다. 위에 아키텍처에는 잘 드러나지 않지만 프리즘은 Event Driven Architecture(EDA) 로 구축되어 있습니다. 이벤트 처리는 Redis Stream 으로 사용했습니다. 그리고 Airflow는 EC2 환경에서 동작시켰습니다. 이런 전체적인 아키텍처도 나쁘지 않지만 우리가 앞으로 더 나아가는데 몇 가지 발목 잡히는 부분이 있었습니다. 하나씩 살펴보겠습니다.

첫 번째는 코드입니다. 대부분의 코드가 동기 방식(synchronous)으로 구현했기 때문에 효율적이지 못한 부분이 있었습니다. 동기방식은 사람이 이해하기 쉽기 때문에 추가 개발을 포함한 유지보수가 안정적이지만 광고주 수에 따라 동시에 데이터를 처리하기 위해 무조건 인스턴스를 늘려야(scale-out)만 하는 아쉬운 부분이 있습니다. 인스턴스를 늘린다는 건 결국 비용과 직결되는 문제인데요. 제대로 된 개발팀을 보유하고 있다면 빠르게 성장하는 스타트업이라도 비용 문제를 같이 해결하면서 전진하는 게 맞다고 생각합니다.
두 번째로 Redis Stream은 개발자에게 약간의 허들이 됩니다. Stream 키의 태생을 이해하고 사용법을 익혀야 하는 거죠.
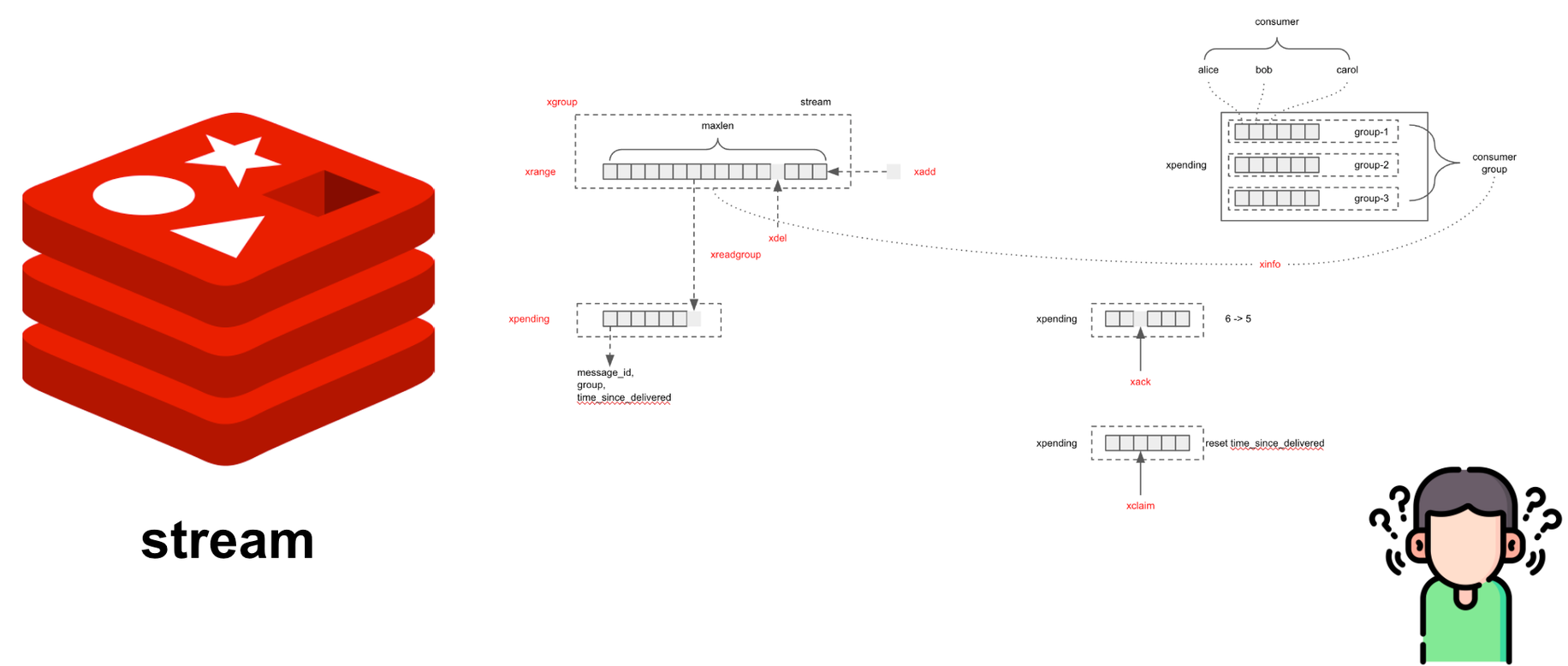
개발자라면 무릇 당연히 그래야 하는 거 아니야?라고 반문하는 분이 계실 수도 있지만 Redis Stream은 그렇게 인기 있는 기술스택이 아닙니다. 백번 양보해서 개발자가 그 기술을 통달한다고 쳐도 큰 경험으로 남기는 어렵다는 겁니다. 더욱이 Redis를 Cluster로 운영하지 않는다면 Stream에 저장된 메시지를 유실할 가능성이 높습니다. 물론 흔한 일은 아니지만요.
세 번째는 ECS입니다. 사실 이미 ECS를 이용해 수십 개의 인스턴스 위에서 수백 개의 tasks(편의상 container라고 생각하셔도 됩니다)를 안정적으로 처리하고 있습니다. 심지어 혹자는 ECS가 EKS 대비 경량화 돼서 비즈니스를 빠르게 빌드업할 수 있다고 이야기할 만큼 나름의 장점도 있는 서비스입니다. 그런데 왜 ECS에서 한계를 느끼냐구요? 우선 조직의 EKS 혹은 Kubernetes 운영 역량에 따라 충분히 ECS에 견줄 만큼 빠르고 간편한 배포와 더불어 안정성 면의 이점도 있을 것이라 판단했습니다. 또한 ECS의 배포 단위 중 하나인 “Service” 단에서는 리소스 제약을 설정할 수 없다는 단점도 있었습니다. Task와 Container에만 가능하죠. 이에 반해 AWS에서 선택 가능한 다른 컨테이너 오케스트레이션 도구인 EKS는 Pod 뿐만 아니라 Namespace 단위로 리소스를 제한할 수 있습니다.
네 번째는 Airflow on EC2입니다. 개인적으로 Airflow와 관련해서 기술적인 대화를 할 기회가 있다면 “Airflow는 충분히 익어서 안정적인 워크플로예요”라고 이야기합니다. 실제로 1년 넘게 EC2로 운영하면서 문제가 된 적은 몇 번 없었습니다. 그 몇 번도 Airflow 자체 문제는 아니었고 disk full 등의 이슈였는데 그건 운영을 잘못해서 그랬던 거죠. 아무튼, EC2에서도 문제는 없었지만 앞으로도 그런다는 보장은 없습니다. 업무시간에 인스턴스에 문제가 생긴다면 사람이 빠르게 대응해서 downtime을 최소화할 수 있을 겁니다. 하지만 새벽이라면? 장애 알람을 받아도 빠른 대응은 어려울 겁니다.
다섯 번째는 Data Warehouse(DW)입니다. 처음 프리즘을 구축할 때는 마케팅 도메인과 DW에 대한 이해가 부족했기 때문에 모든 데이터를 DW에 올리기 위해 무던히 노력했습니다. 사실상 Data Lake(DL)과 DW에 구분이 없을 정도였으니까요. 더욱이 PoC 할 때 좋은 성능을 보여줬던 DC2 노드는 운영 환경에서 꽤나 안타까운 결과를 냈습니다. DB가 안 터지면 다행이었으니까요. 우리가 쌓는(쌓을) 데이터 양을 제가 얕잡아 본건지도 모르겠습니다(웃음)
이외에도 몇 가지 더 이야기할 수 있지만 새로운 프리즘(V2)을 만들어야 하는 가장 큰 이유는 회사에서 준비 중인 새로운 프로덕트의 요구사항을 충족하기 위해서입니다. 중요한 것은 현행 유지 차원이라면 프리즘 V1도 충분히 오랫동안 버틸 수 있을 겁니다. 혹시 시스템에 일시적인 문제가 생기더라도 Self-Healing 될 수 있도록 아키텍처를 설계했거든요. 개발자가 장기 휴가를 떠나도 시스템은 튼튼하게 유지/운영됩니다. 이건 V2에도 여전히 유효할 테니 더 이상의 설명은 생략하고 다음 버전으로 넘어갑니다.
프리즘 V2를 세상 밖으로
위에서 언급한 다섯 가지 이유를 해결하기 위해 고민한 결과를 공유합니다.
첫 번째로 코드는 모두 비동기 방식(asynchronous)으로 수정했습니다. 광고 매체/트래커로부터 데이터를 수집하는 것부터 수집된 데이터를 처리하는 과정, 그리고 S3에 업로드까지 모두 비동기로 구현되었습니다. 그로 인해 인프라에 CPU를 더욱 효율적으로 활용할 수 있게 됐습니다. 이 내용은 PYTHON ASYNCIO를 활용한 효율적인 광고 데이터 수집 에서 자세히 살펴보실 수 있습니다.
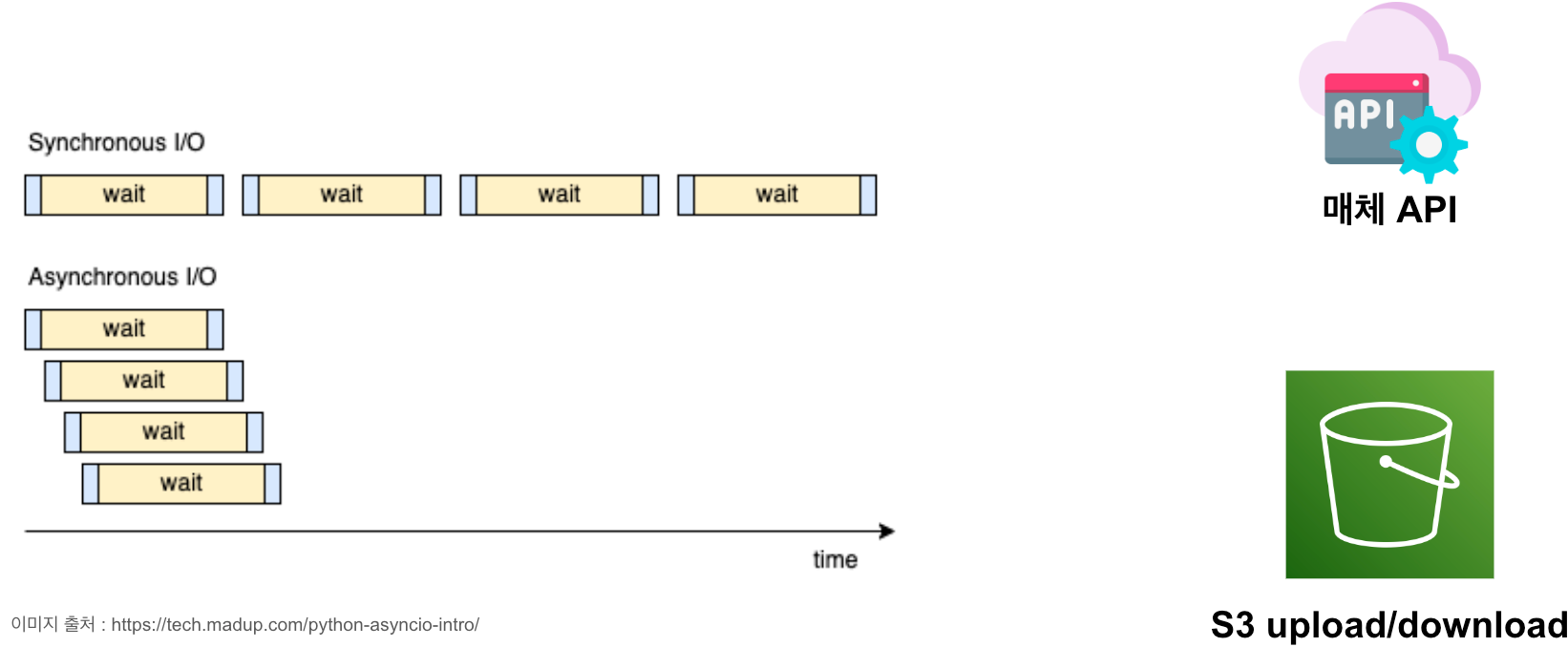
두 번째로 Redis Stream 대신 AWS SQS와 Managed Kafka인 MSK를 선택했습니다. 메시지를 넣고 꺼내는 건 클래스로 추상화시켜 두고 개발자는 비즈니스 코드에만 집중할 수 있습니다. 매니지드 서비스인 만큼 안정성이 보장됩니다. 또한 개발과정에서 개발자는 SQS와 MSK를 심도 있게 사용할 수밖에 없는데 이것들은 좋은 경험이 됩니다. SQS는 Visibility Timeout과 Receipt Handle을 제대로 다루는 게 핵심이 될 것이며 MSK는 굳이 설명이 필요 없을 정도로 많은 곳에서 널리 사용되고 있는 서비스이니 당연히 경력에도 도움이 됩니다.
세 번째로 ECS 대신 EKS를 선택했습니다. ECS와 EKS를 비교하는 자료는 많지만 그중에 프리즘이 EKS를 선택해야하는 이유에 해당하는 건 없습니다. EKS로 전환했을 때 가장 큰 장점은 kubectl이라는 강력한 도구를 통해 터미널에서 인프라 환경에 기민하게 대응할 수 있게 된다는 겁니다. 또한 EKS는 Kubernetes 기반으로 온라인에 수많은 best practice가 존재하기 때문에 많은 것을 보고 배우며 적용할 수 있게 됩니다.
네 번째로 EC2에서 운영하던 Airflow를 Amazon Managed Workflows for Apache Airflow(MWAA) 환경으로 옮겼습니다. 매니지드가 주는 안정감을 얻기 위해서입니다. 물론 매니지드 서비스로 넘어가면서 포기하는 것도 있습니다. EC2 환경에서 실행되는 DAG의 Task는 병목 없이 굉장히 빠르게 스케줄 되지만 MWAA 환경의 경우 그렇지 못합니다. 즉, DAG이 많아지고 스케줄 주기가 짧다면 문제가 될 여지가 있습니다. 이건 MWAA가 아니라 Airflow on Kubernetes도 마찬가지입니다. 온라인에는 Airflow를 Kubernetes나 다른 매니지드 서비스로 동작시킨 다양한 성공 사례가 있습니다. 하지만 은탄환1은 없다는 걸 기억하시고 비즈니스 성격에 맞는지 확인하고 적용하시길 바랍니다.
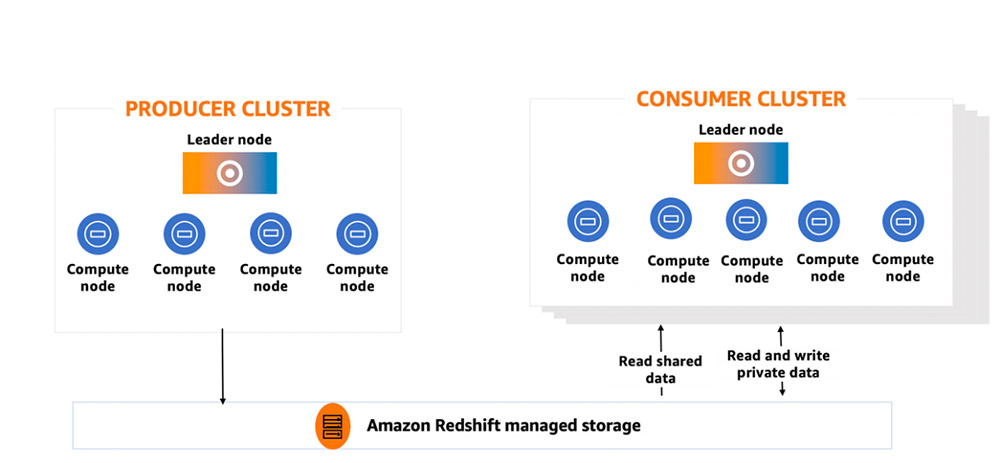
마지막으로 다섯 번째는 여전히 Redshift를 사용하지만 Node Type을 RA3로 변경했습니다. RA3 노드에는 분산형 하드웨어 가속 캐시 AQUA 가 기본탑재 됩니다. AWS 직원의 표현을 빌리자면 “Redshift는 RA3를 기준으로 기원전과 후로 나뉜다” 고 말할 정도입니다. 성능면에서 월등해졌고 DC2 노드(160 GB) 대비 압도적으로 풍부한 스토리지(ra3.xlplus 기준 32 TB)를 보유하게 됩니다. 진짜는 다음입니다. RA3 노드는 managed storage를 통해 다른 클러스터와 데이터를 공유할 수 있습니다. 아래 이미지를 보면 PRODUCER CLUSTER와 CONSUMER CLUSTER는 각자의 컴퓨팅을 침범하지 않게 됩니다. 즉, 설령 어떤 문제가 있어서 한쪽 클러스터가 중단되더라도 다른 쪽 비즈니스에 영향을 주지 않는 것을 의미합니다. 이로써 데이터 분석가는 그들의 클러스터에 마음 편히 쿼리를 실행할 수 있게 됩니다.
여기까지 설명한 내용으로 그림을 그려보면 아래와 같습니다. 여기 그림에는 표현하지 않았지만 비즈니스 목적에 따라 총 두 개의 EKS Cluster가 운영 중입니다. 서비스 애플리케이션으로는 데이터를 수집하는 collector, 수집된 데이터를 변환하는 transformer 그리고 소재 이미지를 처리하는 sorceress 가 있습니다. 또한 collector와 transformer를 연결하는 bumblebee는 MSK에서 꺼내온 메시지를 SQS로 전달하는 가교 역할을 합니다.
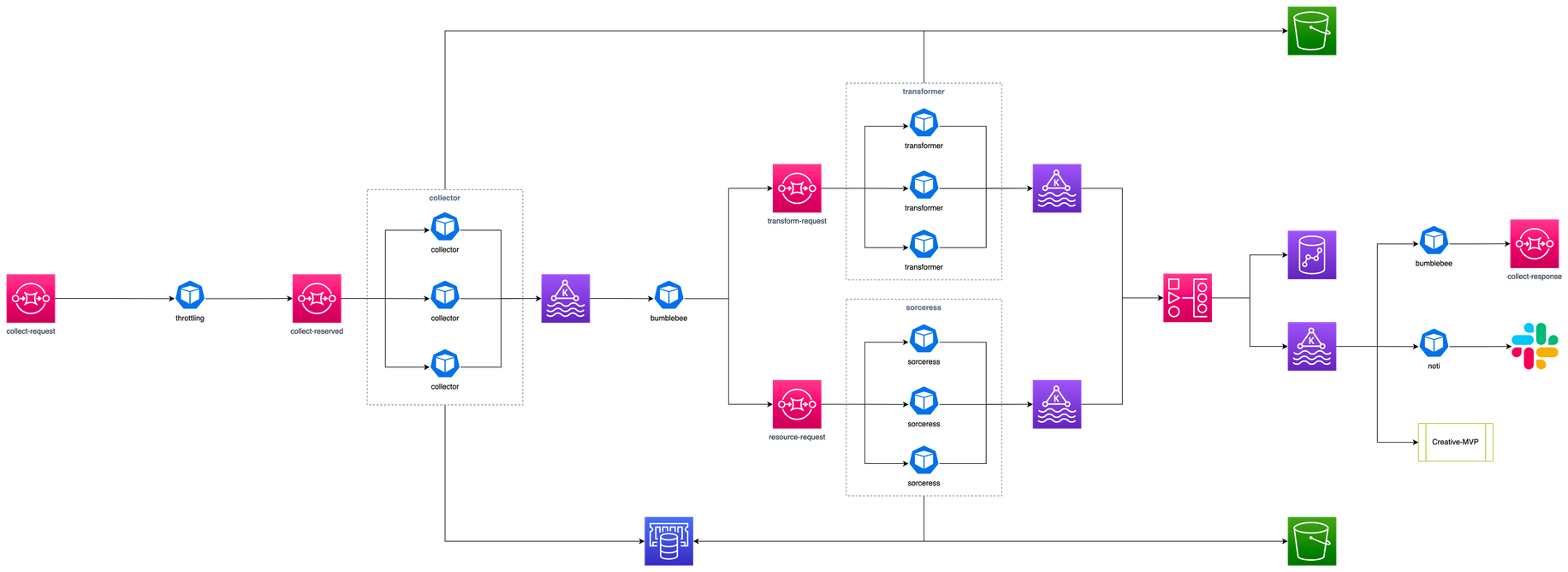
앞으로의 과제
세상에는 무수히 많은 광고 매체와 트래커가 존재합니다. 우선 프리즘을 세계 No.1의 압도적인 광고 데이터 수집기로 발전시키고자 합니다. 필요한 데이터를 적절히 수집하기 위해서 도메인에 대한 이해도 필요합니다. 이를 극복하기 위해 팀에서는 매체 스터디를 꾸준히 진행하고 있습니다. 또한 매체의 API 버전업을 유연하게 대응하기 위한 고민을 하고 있습니다.
회사 비즈니스에서 나오는 모든 데이터와 내부에서 만들어지는 데이터를 프리즘으로 빨아들이고 그걸 토대로 데이터 분석가, 데이터 사이언티스트 혹은 비즈니스 분석가가 유의미한 아웃풋을 만들어낼 수 있도록 기여하고자 합니다. 위에서 소개한 JupyterHub는 사실 작은 규모의 분석에 적합하고 대량의 데이터를 소비하기 위한 분석 플랫폼을 별도로 구축할 계획입니다.
asynchronous로 동작하는 코드에 튜닝이 필요합니다. 컴퓨팅 리소스를 우리 비즈니스에 맞게 사용하기 위해 pod와 container 안에 coroutine 개수를 조정해 나가야 합니다.

소재 이미지/영상을 다운로드하는 애플리케이션은 현재 EKS Cluster에서 동작중입니다. 현재 소재를 제공하는 매체에 다운로드 트래픽이 부하를 주지 않도록 다운로드 속도를 조절(throttling)하고 있습니다만 이미지 개수가 워낙 많아서 고민입니다. Horizontal Pod Autoscaler(HPA)로 적절히 조율해도 되겠지만 클러스터 노드의 자원을 이쪽이 전부 소진하게 둘 수는 없으니까요. 그래서 아마 App Runner 가 서울리전에 출시되면 옮겨가지 않을까 싶습니다. 어차피 애플리케이션은 dockerize 되어 있기 때문에 환경이 바뀌는 건 전혀 문제가 없습니다. 이처럼 배포한 애플리케이션이 동작하는 환경을 best practice로 생각할 수 있는지 끊임없이 의문을 갖고 개선해 나갈 예정입니다.
마치며…
이번 글에서는 프리즘을 회사차원에서 전반으로 소개했는데요. 다음 글은 개발자가 관심 있을만한 아키텍처와 데이터 파이프라인을 주제로 심도 있게 다뤄보면 좋을 것 같습니다. 사실 이번 글에서 Infrastructure as Code(IaC), Monorepo 등 하고 싶은 이야기는 많았지만 또 다른 기회가 있겠죠?
끝으로 매드업에서는 광고 데이터가 갖고 있는 문제를 함께 풀어나가며 성장하실 분을 찾고 있습니다. 동료는 최고의 복지 중에 하나입니다. 현직자에게는 지원자가, 지원자에게는 현직자가 최고의 복지가 될 수 있도록 팀을 빌딩하고 있습니다. 매드업은 내부적으로 기술적인 토론은 언제든지 환영하는 문화를 갖고 있습니다. 또한 신입사원도 프리즘의 코어와 IaC를 코드 리뷰를 통해 함께 구축해 나갑니다. 수평적인 문화를 지향하고 영어 닉네임을 사용하고 있습니다. 팬데믹에는 전사 재택을 하고 있으며 평시에는 주 2회 자유로운 재택근무가 가능합니다. 이런저런 복지가 더 많지만 지면을 아끼겠습니다. 자세한 복지는 다음 링크를 통해 확인해 주세요. - 매드업 복지
데이터 항해를 함께하길 원하시는 분, 기술적인 대화를 심도 있게 나눠보고 싶으신 분, 매드업이 궁금해서 커피 챗을 원하시는 분은 언제든 편하게 문의해 주세요. We need you :)
[1] : No Silver Bullet – Essence and Accidents of Software Engineering, 1986년 프레드릭 브룩스가 쓴 소프트웨어 공학 논문에 등장해서 주로 소프트웨어에서 사용되는 말로, 모든 문제를 한 번에 해결하는 마법은 없다는 표현.

