
AWS Batch 시작하기
구글이나 페이스북 등의 매체를 통해 쇼핑몰 광고를 할 경우 해당 매체에 쇼핑몰 상품 목록의 정해진 양식을 넘겨 주어야 효율적인 광고를 할 수 있습니다. 그 양식을 보통 카탈로그 피드(Catalog Feed)라고 부릅니다. 상품 정보, 즉 카탈로그의 양식은 각 쇼핑몰마다 다르기 때문에 광고 매체가 원하는 양식으로 변경을 해주어야 합니다.
단순 배치성 작업이기 때문에 처음에는 AWS Lambda를 떠올렸습니다. 그러나 각 쇼핑몰의 상품의 갯수가 많은 경우 작업이 끝나지 않았는데 람다가 꺼질 수 있기 때문에 다른 서비스를 찾아야 했습니다. 더욱이 상품이 많은 쇼핑몰의 피드 용량이 1~2 GB 정도 되게 때문에 람다에서는 작업할 수가 없었습니다. 그러다 발견한 서비스가 바로 AWS Batch입니다.
Batch vs Lambda
본격적으로 AWS Batch를 시작하기에 앞서 람다와 간단하게 비교를 해보겠습니다. 사실 람다와 배치는 서로의 성격이 상이하기 때문에 직접 비교하는 것은 좋진 않지만, 현재 제가 있는 TAG 팀이 처한 상황을 고려해서 간략히 비교하겠습니다. 기준은 추가 리소스 요청 없음, 서울 리전입니다.
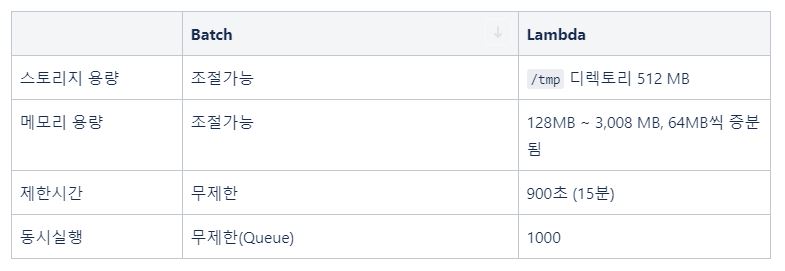
Batch 항목들을 보면, “조절가능”과 “무제한”으로 명시한 것은 Batch가 EC2 위에서 동작하기 때문입니다. AWS Batch는 단순 배치성 작업이지만 대기열(Queue) 지원, 작업(Job) 동시 실행 등이 가능하고 무엇보다 추가 요금이 없습니다. 배치 작업을 하기 위해 EC2 인스턴스가 생기는데 해당 인스턴스에 대한 요금만 내면 됩니다. 일반 EC2 인스턴스 뿐만 아니라 최근 추가된 EC2 SPOT 인스턴스로 비용을 더 절감할 수 있는 장점이 있습니다.
사실 AWS Batch는 EC2와 ECS의 wrapper 서비스입니다. AWS Batch를 시작하면 ECS에 클러스터가 생기고 작업 정의 항목에 Batch에서 생성한 작업정의가 보입니다. 그리고 실제로 작업이 작동하고 있을때 EC2에서 인스턴스를 직접 확인할 수도 있습니다.
만약 람다가 스토리지 용량을 GB 단위로 제공하고 제한시간이 더 컸다면 저희 팀 역시 익숙한 람다를 사용했을 것입니다.
AWS Batch 구성요소
AWS Batch의 구성요소는 작업을 구동할 서버의 자원을 설정하는 컴퓨팅 환경(Computing Environment), 제출한 작업이 대기하는 작업 대기열(Job Queue), 실제 작업할 소스가 담긴 작업 정의(Job Definition), 작업 정의를 실제로 실행하는 작업(Job)으로 이루어져 있습니다.
컴퓨팅 환경
컴퓨팅 환경은 작업을 실행하는 데 사용되는 관리형 또는 비관리형 컴퓨팅 리소스 세트입니다.
작업 대기열
최대 3개의 컴퓨팅 환경 위에서 작동하는 평범한 큐입니다. 자세한 설명은 없으나 실제 작동할 때나 이 유튜브 영상을 보면 비동기 큐임을 짐작할 수 있습니다.
작업 정의
작업 정의는 실제 실행할 코드, 정확히는 그 코드를 포함하는 도커 이미지를 정의합니다. 저희는 이미지를 ECR에 저장했지만 사설 레지스트리나 docker hub를 이용해도 무방합니다.
공식 문서와 한국 블로그를 보면 도커 이미지 뿐만 아니라 쉘 스크립트, 루비, 파이썬 등 리눅스에서 실행 가능한 작업을 제출할 수 있다고 되어있지만, 실제로는 도커 이미지만 지원합니다. AWS 포럼에도 문서를 읽고 저와 같은 의문을 가진 사람이 질문을 했고, 이에 대한 답변이 있습니다. 답변을 보면 ECR을 이용하기 때문이라고 하는데 실제로 컴퓨팅 환경을 생성하면 앞서 얘기했듯이 ECR 클러스터가 생성되는 것을 확인할 수 있습니다. 문서는 항상 업데이트가 느린가 봅니다.
작업
위에서 정의한 작업 정의를 실제로 구동합니다. 여러가지 환경변수를 제공하며 어레이 작업과 종속성이라는 간단하지만 강력한 배치 도구를 제공합니다.
CloudFormation으로 생성하기
저는 인프라조차도 코드로 관리하는 것을 좋아합니다. AWS 콘솔은 편하긴 하지만, 코드로 관리하지 않으면 나중에 관리하기가 힘들어집니다 그래서 CloudFormation을 좋아하는데 Batch 역시 지원합니다. 참조와 예제를 참고하면 손쉽게 작성할 수 있습니다. 물론 테라폼을 사용해도 좋습니다.
우리는 이렇게 했습니다.
저희 TAG 팀에서는 간략하게 아래와 같은 구조로 진행하기로 했습니다. 실제 회의 때 보드에 간략히 그린 구조입니다.

CloudWatch Event가 정해진 시간마다 매일 람다를 호출합니다. 람다는 상품 정보를 모으고 DB에 쓰기를 하는 작업을 트리거하고, 해당 작업에 종속성을 갖는 두 개의 작업(피드 생성, 이미지 처리)이 순차적으로 실행됩니다. 각 매체는 작업이 생성한 트리거를 정해진 시간에 읽습니다.
아래는 작업 대기열과 컴퓨팅 환경을 생성한 결과물입니다. LeverCatatlogJobQueue가 저희가 생성한 대기열입니다.

각 작업은 docker 이미지로 정의했습니다. 대략적인 구조는 아래와 같습니다.
jobs
├── README.md
├── collect_catalog/
├── generate_feed/
├── image_processing
│ ├── Dockerfile
│ ├── README.md
│ ├── requirements.txt
│ └── src
│ ├── __init__.py
│ └── main.py
└── template.yaml
이게 전부입니다. jobs 디렉토리의 하위 디렉토리들은 작업 정의이자 docker 이미지입니다. 생성한 이미지를 ECR에 푸쉬합니다. 다른 프로젝트의 이미지와 구분을 짓기 위해서 접두사로 catalog를 붙였습니다.
작업을 트리거 하는 람다 코드는 대략적으로 아래와 같습니다.
import boto3
batch_client = boto3.client("batch")
shop_id = 1234 # db에서 수집할 쇼핑몰 id
# 카탈로그 정보 쓰기 작업 제출
response = batch_client.submit_job(
jobName=f"collect-catalog-shop_{shop_id}",
jobQueue="catalog-job-queue",
jobDefinition="collect-catalog",
containerOverrides={"command": [f"{shop_id}"]},
)
job_id = response.get("jobId")
# job_id에 종속성을 갖는 피드 생성 작업 제출
batch_client.submit_job(
jobName=f"feed-shop_{shop_id}-job_{job_id}",
jobQueue="catalog-job-queue",
jobDefinition="generate-feed",
dependsOn=[{"jobId": job_id}],
containerOverrides={"command": [f"{shop_id}"]},
)
# job_id에 종속성을 갖는 이미지 처리 작업 제출
batch_client.submit_job(
jobName=f"image-shop_{shop_id}-job_{job_id}",
jobQueue="catalog-job-queue",
jobDefinition="image-processing",
dependsOn=[{"jobId": job_id}],
containerOverrides={"command": [f"{shop_id}"]},
)
정말 별거 없습니다. 작업 정의를 위해 dockerfile을 생성하고, 해당 작업 정의를 이용해 실제 작업을 작업 대기열에
제출하면 끝납니다. dependsOn 파라미터에 작업 아이디를 넘겨주어 순차적으로 실행됨을 보장만 하면 됩니다. 물론, CloudWatch Event를 이용하여 정해진 시간마다 cronjob을 설정하면 진짜 끝입니다.
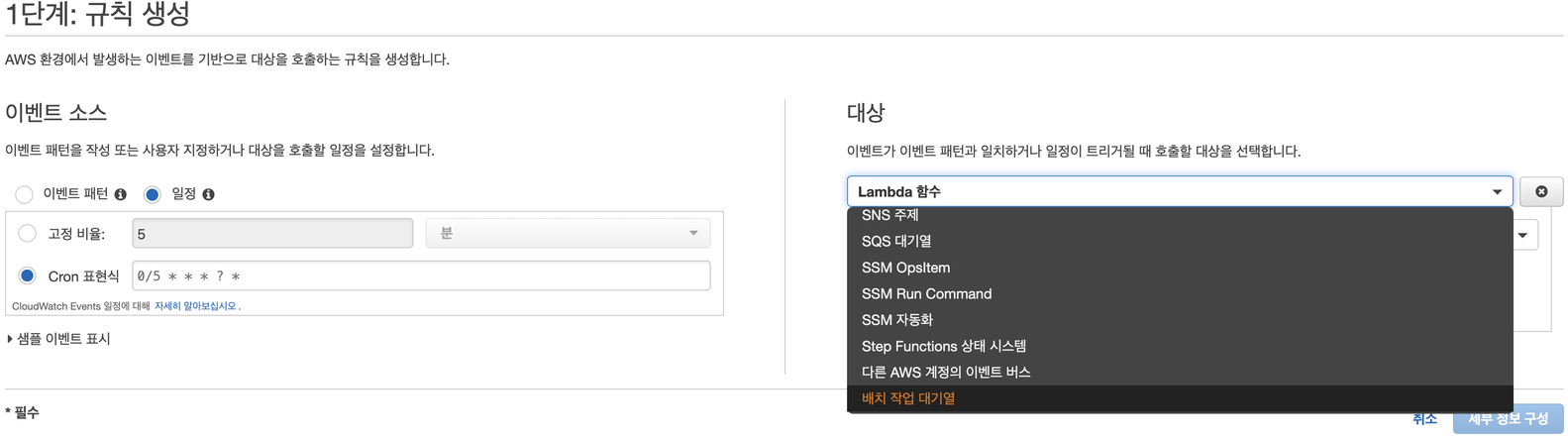
직접 대기열을 이용할 경우 제일 아래에 배치 작업 대기열을 위에서 생성한 LeverCatatlogJobQueue를 선택하면 됩니다. 저희는 람다를 이용하여 트리거 하기로 했으므로 Lambda 함수를 선택했습니다.
결론
별다른 수고 없이 컴퓨팅 환경 생성 -> 작업 대기열 생성 -> 작업 정의(dockerfile 및 실제 코드) -> 작업 제출만 하여 배치 작업을 완료했습니다. 이 외에도 어레이 작업을 이용하여 순차 또는 병렬 작업을 다양하게 실행 할 수도 있습니다. 단순한 배치성 작업을 해야 하는데, 디스크/메모리 용량과 실행시간이 많이 필요할 경우 AWS Batch를 이용하는 방법을 추천합니다.


